正则表达式(通常称为正则表达式)是定义搜索模式的字符序列。 正则表达式主要用于与字符串的模式匹配和字符串匹配;例如,在“查找和替换”作中。 可以使用 Microsoft Purview 数据丢失防护 (DLP) 中的正则表达式来定义有助于识别敏感数据和分类的模式,或帮助检测内容中的模式。 Microsoft Purview DLP 中最常见的正则表达式用途是:
本文介绍使用正则表达式时出现的常见问题以及如何解决这些问题。
将正则表达式与 DLP 配合使用时的潜在验证问题
- 模式的基本单位(如文本字符、数字、空格和标点符号)可以自行表示,也可以由称为元字符的特殊符号表示,例如
\d,对于任何数字、\s任何空格或\.文本点。 - 基本单位与限定符结合使用时,指定在匹配中可以或必须发生的次数。 例如,
*表示零或更多,+表示一个或多个,?表示零或一,表示{n,m}和m时间之间n。 例如,\d+表示一个或多个数字,\s?表示可选的空格,表示a{3,5}文本字符 a 的三到五 个实例。 - 正则表达式要么使用正面外观,要么使用负面外观。 lookbehind 用于检查输入字符串中某个位置之前是否有匹配项,而不包括匹配中的实际字符。 正外观隐藏用于 在存在外观 模式时进行匹配,而负外观隐藏用于在 不存在 外观模式时进行匹配。
- 请考虑此示例:
(?<=^|\s|_)。 此示例演示了一个外观,其中包含三种可能性:-
^断言位置。 在这种情况下,它要求模式匹配从行的开头开始。 -
\s将任何空格字符检测为匹配项。 -
_匹配文本下划线字符 ( _ ) 。
-
- 在前面的示例中,可能性 #2 和 #3 将分别匹配单个字符。 但是,可能性 #1 仅指示匹配应从何处开始。 它不会生成任何字符匹配的结果。
- 以第二个示例为例
^\d+$。 此正则表达式将仅检测完全由数字组成的字符串(从头到尾)。 - 默认情况下,条件中的正则表达式模式验证不区分大小写。 若要遵循区分大小写,请将 (?-i) 添加到模式
如何获取提取的文本
正则表达式在内容的提取文本上匹配,而不是在内容本身上匹配。 因此,即使模式出现在内容上,在评估 DLP 策略时也可能不匹配。
若要确保捕获适当的匹配项,请执行以下步骤:
- 使用 Test-TextExtraction cmdlet 获取提取的文本,该文本将包含字符串流。
- 接下来,使用提取的文本来匹配正则表达式。
例如:
$data = ([System.IO.File]::ReadAllBytes('<FilePath>'))
$tr = Test-TextExtraction -FileData $data
$tr.ExtractedResults.ExtractedStreamText | Format-List
如何验证敏感信息类型检测
若要验证敏感信息类型 (SIT) 检测,我们需要获取刚刚提取的文本,然后在其中运行 Test-DataClassification cmdlet 来验证检测。 运行 cmdlet 的结果将指示正则表达式是否有任何 SIT 匹配项。
例如:
$textStream = $tr.ExtractedResults.ExtractedStreamText | Out-String
$result = Test-DataClassification -TextToClassify $textStream
$result.ClassificationResults | Format-List
在 DLP 策略规则中使用正则表达式的示例
在此示例中,我们将阻止包含以 ABC 开头、后跟数字的字符串的电子邮件。
使用的正则表达式:^ABC\d
DLP 规则示例:New-DlpComplianceRule -Name "Rule_00" -Policy "Policy_00" -SubjectOrBodyMatchesPatterns "^ABC\d" - BlockAccess $True
示例电子邮件
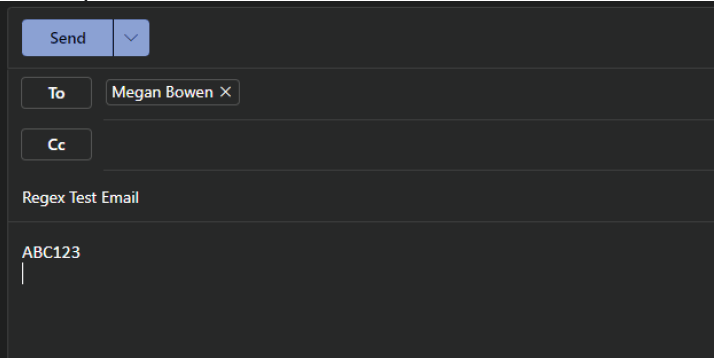
虽然正则表达式似乎将检测与此邮件项的匹配项,但提取的文本如下所示:
Regex Test Email ABC123
可以看到,提取的文本以电子邮件主题行中的内容开头,而不是电子邮件正文中的内容。 但是,在正则表达式的开头包含断言字符 ^,要求 ABC... 字符串必须位于提取的文本的开头才能检测到匹配项。
若要解决此问题,可以将正则表达式更改为 ABC\d。