重要
本文仅适用于 经典电子数据展示 (高级版) 体验。 经典电子数据展示 (Premium) 体验将于 2025 年 8 月停用 ,停用后在 Microsoft Purview 门户中将不作为体验选项提供。
建议尽早开始规划此转换,并开始在 Microsoft Purview 门户中使用新的电子数据展示体验。 若要详细了解如何使用最新的电子数据展示功能和功能,请参阅 了解电子数据展示。
重要
预测编码已于 2024 年 3 月 31 日停用,在新的电子数据展示案例中不可用。 对于具有已训练预测编码模型的现有案例,可以继续将现有分数筛选器应用于审阅集。 但是,无法创建或训练新模型。
本文介绍了在 Microsoft Purview 电子数据展示 (Premium) 中使用预测编码的快速入门。 预测编码模块使用智能机器学习功能来帮助你剔除与调查无关的大量案例内容。 这是通过创建和训练自己的预测编码模型来实现的,这些模型可帮助你确定要审阅的最相关的项的优先级。
下面是预测编码过程的快速概述:

首先,请创建一个模型,将多达 50 个项标记为相关或不相关。 然后,系统使用此训练将预测分数应用于审阅集中的每一项。 这使你可以根据预测分数筛选项目,从而可以先查看最相关的 (或不相关的) 项。 如果要以更高的准确度和召回率训练模型,可以在后续训练轮中继续标记项,直到模型稳定下来。 稳定模型后,可以应用最终预测筛选器来确定要查看的项目的优先级。
有关预测编码的详细概述,请参阅 了解电子数据展示 (Premium) 中的预测编码 。
提示
如果你不是 E5 客户,请使用 90 天Microsoft Purview 解决方案试用版来探索其他 Purview 功能如何帮助组织管理数据安全性和合规性需求。 立即在 Microsoft Purview 试用中心开始。 了解有关 注册和试用条款的详细信息。
步骤 1:创建新的预测编码模型
注意
在有限的时间内,新的 Microsoft Purview 门户中提供了经典电子数据展示体验。 在电子数据展示体验设置中启用 Purview 门户经典电子数据展示体验,以便在新的 Microsoft Purview 门户中显示经典体验。
第一步是在审阅集中创建新的预测编码模型:
在 Microsoft Purview 门户中,打开电子数据展示 (Premium) 事例,然后选择“ 审阅集 ”选项卡。
打开审阅集,然后选择“ 分析>管理预测编码 (预览) 。
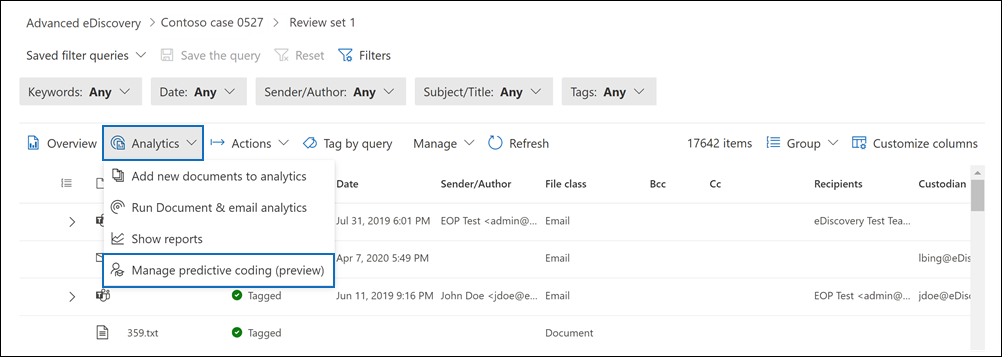
在 “预测编码模型 (预览) ”页上,选择“ 新建模型”。
在浮出控件页上,键入模型的名称和可选说明。
选择“ 保存” 以创建模型。
系统准备模型需要几分钟时间。 准备就绪后,可以进行第一轮训练。
有关更详细的说明,请参阅 创建预测编码模型。
步骤 2:执行第一轮训练
注意
在有限的时间内,新的 Microsoft Purview 门户中提供了经典电子数据展示体验。 在电子数据展示体验设置中启用 Purview 门户经典电子数据展示体验,以便在新的 Microsoft Purview 门户中显示经典体验。
创建模型后,下一步是通过将项标记为相关或不相关的项来完成第一轮训练。
打开审阅集,然后选择“ 分析>管理预测编码 (预览) 。
在 “预测编码模型 (预览) ”页上,选择要训练的模型。
在“ 概述 ”选项卡上的“ 第 1 轮”下,选择 “开始下一轮训练”。
将显示“ 训练 ”选项卡,其中包含 50 个要标记的项目。
查看每个文档,然后在阅读窗格底部选择“ 相关 ”或“ 不相关 ”进行标记。
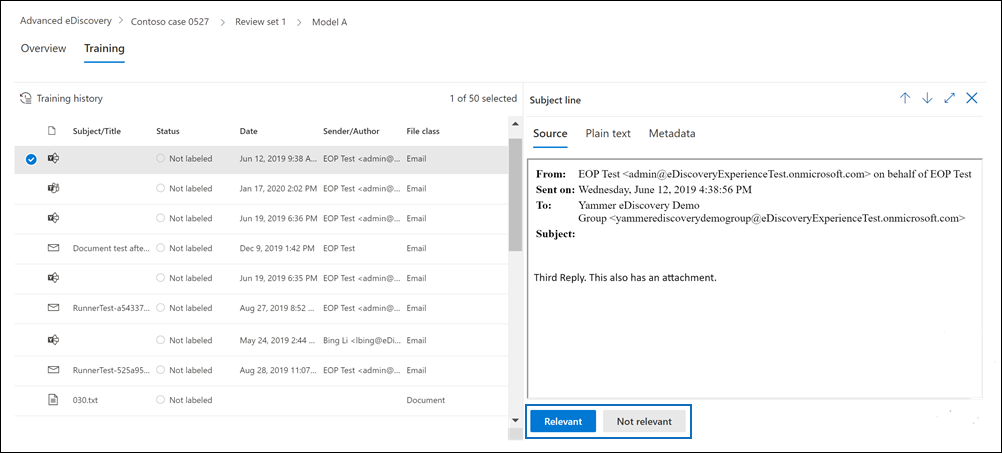
标记所有 50 个项目后,选择“ 完成”。
系统需要几分钟时间才能从标记中“学习”并更新模型。 此过程完成后,预测编码模型 (预览) 页上显示模型的状态为“就绪”。
有关更详细的说明,请参阅 训练预测编码模型。
步骤 3:将预测分数筛选器应用于审阅集中的项目
注意
在有限的时间内,新的 Microsoft Purview 门户中提供了经典电子数据展示体验。 在电子数据展示体验设置中启用 Purview 门户经典电子数据展示体验,以便在新的 Microsoft Purview 门户中显示经典体验。
在租用一轮训练中执行后,可以将预测分数筛选器应用于审阅集中的项目。 这使你可以查看模型预测为相关或不相关的项。
打开审阅集。
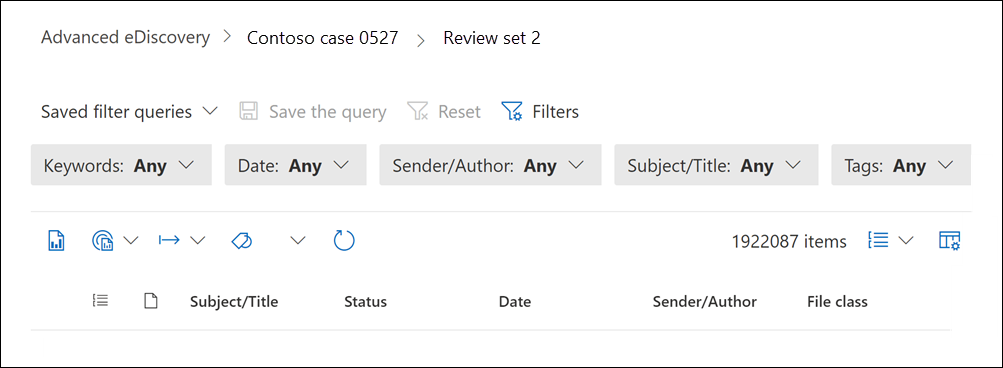
预加载的默认筛选器显示在审阅集页面的顶部。 可以将这些设置保留为 “任何”。
选择 “筛选器” 以显示 “筛选器 ”浮出控件页。
展开 “分析 & 预测编码 ”部分以显示一组筛选器。
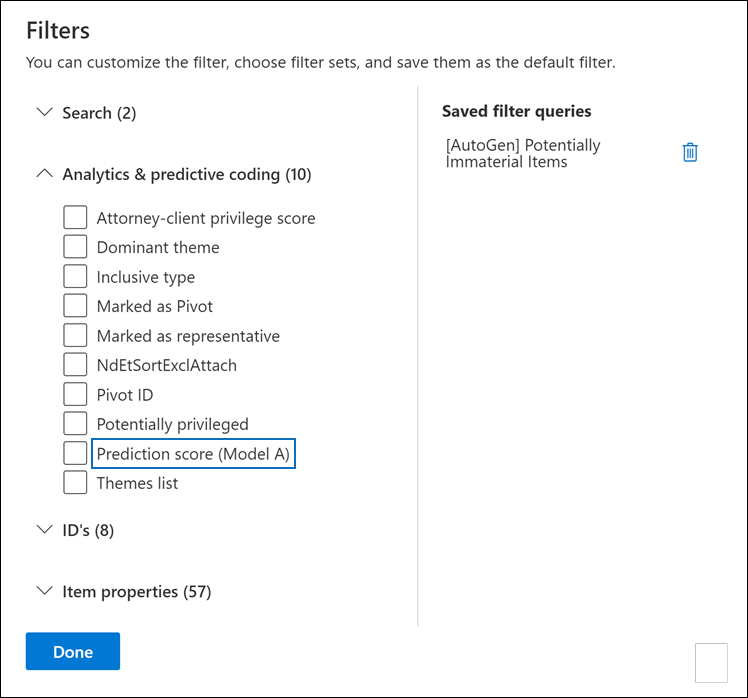
预测分数筛选器的命名约定是 预测分数 (模型名称) 。 例如,名为 “模型 A ”的模型的预测分数筛选器名称 (模型 A) 。
选择要使用的预测分数筛选器,然后选择“ 完成”。
在审阅集页上,选择预测分数筛选器的下拉列表,并为预测分数范围键入最小值和最大值。 例如,以下屏幕截图显示了 0.5 到 1.0 之间的预测分数范围。
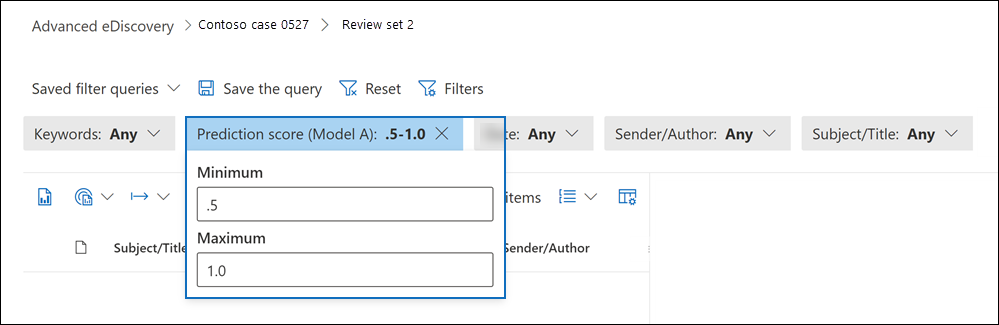
选择筛选器外部,将筛选器自动应用于审阅集。
审阅集页上会显示预测分数在指定范围内的文档列表。
有关更详细的说明,请参阅 将预测筛选器应用于审阅集。
步骤 4:执行更多训练轮次
很可能,你将不得不执行更多的训练轮来训练模块,以更好地预测评审集中的相关和不相关的项目。 通常,你将训练模型足够多的时间,直到它稳定到足以满足你的要求。
有关详细信息,请参阅 执行其他训练轮次
步骤 5:应用最终预测分数筛选器,确定评审的优先级
重复步骤 3 中的说明,将最终预测分数应用于评审集,以在完成所有训练轮次并稳定模型后确定相关项和非相关项目的评审优先级。