| 玛雅娜·佩雷拉 | 斯科特·克里斯蒂安森 |
|---|---|
| CELA 数据科学 | 客户安全和信任 |
| Microsoft | Microsoft |
摘要 — 识别安全漏洞报告(SBR)是软件开发生命周期中的重要一步。 在基于监督的机器学习方法中,通常假设完整的 bug 报告可用于训练,并且其标签无噪声。 据我们所知,这是相关领域的首次研究,它表明即使只有标题可用且存在标签干扰,也能对 SBR 进行准确的标签预测。
索引词 — 机器学习、错误标记、噪音、安全 Bug 报告、Bug 存储库
一。 介绍
在报告 bug 中确定安全问题是软件开发团队迫切需要的问题,因为此类问题要求进行更快速的修复,以满足合规性要求,并确保软件和客户数据的完整性。
机器学习和人工智能工具承诺使软件开发更快、敏捷、正确。 一些研究人员已经将机器学习应用于识别安全漏洞的问题[2]、[7]、[8]、[18]。以往已发布的研究假定整个漏洞报告可用于训练和评估机器学习模型。 这不一定是这种情况。 在某些情况下,无法提供整个 bug 报告。 例如,bug 报告可能包含密码、个人标识信息(PII)或其他种类的敏感数据——这是我们在 Microsoft 目前面临的情况。 因此,重要的是确定如何使用较少的信息更好地执行安全 bug 识别,例如当只有错误 bug 的标题可用时。
此外,bug 存储库通常包含错误标记的条目 [7]:非安全 bug 报告分类为安全相关,反之亦然。 出现错误标记的原因有多种,从开发团队缺乏安全性专业知识到某些问题的模糊性,例如,可能会以间接方式利用非安全 bug 来造成安全隐患。 这是一个严重的问题,因为 SBR 的标记错误导致安全专家不得不手动审查漏洞数据库,这是一项既昂贵又耗时的工作。 了解噪音如何影响不同的分类器,以及不同机器学习技术在受到不同干扰污染的数据集中是多么可靠(或脆弱)是一个问题,必须解决该问题,才能将自动分类引入软件工程的实践。
初步工作认为,bug 存储库本质上是干扰性的,噪音可能对性能机器学习分类器 [7] 产生负面影响。 然而,目前尚无系统和定量的研究,分析不同级别和类型的噪声如何影响不同监督式机器学习算法在识别安全漏洞报告(SRBs)中的性能。
在此研究中,我们将介绍即使只有标题可用于训练和评分,也能执行 bug 报告的分类。 据我们所知,这是这样做的第一项工作。 此外,我们还首次系统地研究了噪声在缺陷报告分类中的影响。 我们比较研究三种机器学习技术(逻辑回归、天真贝斯和 AdaBoost)对类无关噪音的稳健性。
虽然有一些分析模型捕获几个简单分类器 [5]、 [6] 的干扰的一般影响,但这些结果不会对噪音对精度的影响提供紧密边界,并且仅适用于特定的机器学习技术。 机器学习模型中干扰效果的准确分析通常通过运行计算实验来执行。 对于从软件测量数据 [4] 到卫星图像分类 [13] 和医疗数据 [12] 等多个方案,已经进行了此类分析。 然而,由于它们高度依赖数据集的性质和基础分类问题,这些结果无法转化为我们的具体问题。 据我们所知,尤其在干扰数据集对于安全 bug 报告分类的影响问题上,没有任何已发布的结果。
我们的研究贡献:
我们训练分类器,让其仅根据安全 bug 报告 (SBR) 的标题来识别这类报告。 据我们所知,这是相关领域的首次研究工作。 早期的工作要么使用完整的 bug 报告,要么通过额外的补充功能增强 bug 报告。 当由于隐私问题而无法提供完整的 bug 报告时,仅基于磁贴对 bug 进行分类尤其相关。 例如,臭名昭著的是包含密码和其他敏感数据的 bug 报告。
我们还首次系统研究用于 SPR 自动分类的不同机器学习模型和技术的标签噪音容忍度。 我们比较研究三种不同的机器学习技术(逻辑回归、朴素贝叶斯和 AdaBoost)针对类依赖噪声和类独立噪声的稳健性。
论文的其余内容如下:第二节我们介绍了文献中以前的一些作品。 在第三节中,我们将介绍数据集以及如何预处理数据。 在第四节中描述了该方法论,并在第五节中对我们的实验结果进行了分析。最后,在第六节中提出了我们的结论和未来工作。
第二节 上一篇作品
机器学习应用于 BUG 存储库。
关于在尝试自动执行费力任务(例如安全 bug 检测 [2]、[7]、[8]、[18]、bug 重复标识 [3]、bug 会审 [1]、[11])时将文本挖掘、自然语言处理和机器学习应用于 bug 存储库,已经有广泛的文献。 理想情况下,机器学习(ML)和自然语言处理的结合可能会减少整理 bug 数据库所需的手动工作,缩短完成这些任务所需的时间,并提高结果的可靠性。
在 [7] 中,作者建议使用自然语言模型,根据 bug 的说明自动执行 SBR 分类。 作者从训练数据集中的所有 bug 说明中提取词汇,并手动将其精心策划为三个单词列表:相关字词、停止字词(与分类似乎无关的常见字词)和同义词。 他们比较了根据所有由安全工程师评估的数据训练的安全漏洞分类器的性能,以及根据一般由漏洞报告者标记的数据训练的分类器。 尽管针对安全工程师评审的数据进行训练时,其模型明显更高效,但建议的模型基于手动派生词汇表,使其依赖于人类的组织结果。 此外,没有分析不同级别的噪音如何影响其模型、不同分类器对噪音的反应,以及任一类中的噪音是否对性能产生不同的影响。
Zou et.al [18] 利用 bug 报告中包含的多种类型的信息,其中包括 bug 报告的非文本字段(例如,时间、严重性和优先级),以及 bug 报告的文本内容(文本特征,即摘要字段中的文本)。 它们基于这些功能构建模型,以便通过自然语言处理和机器学习技术自动识别 SBR。 在 [8] 中,作者执行类似的分析,但此外,它们比较监督和非监督机器学习技术的性能,并研究训练模型所需的数据量。
在 [2] 中,作者还根据它们的说明探索不同的机器学习技术,将 bug 分类为 SBR 或 NSR(非安全 Bug 报告)。 他们建议基于 TFIDF 进行数据处理和模型训练的管道。 他们将建议的管道与基于单词包和 Naive Bayes 的模型进行比较。 Wijayasekara 等人[16]还使用文本挖掘技术基于频繁的字词生成每个错误报告的特征向量,以识别隐藏影响错误(HIB)。 Yang 等人 [17] 声明借助术语频率 (TF) 和 Naive Bayes 来识别高影响 bug 报告(例如 SBR)。 在 [9] 中,作者建议一个模型来预测 bug 的严重性。
标签干扰
已广泛研究处理具有标签噪音的数据集的问题。 Frenay 和 Verleysen 建议在 [6] 中使用标签噪音分类,以便区分不同类型的干扰标签。 作者提出了三种不同类型的标签噪声:一种是独立于真实类别和实例特征值的标签噪声;一种是仅依赖真实标签的标签噪声;还有一种是错误标记的概率也取决于特征值的标签噪声。 在我们的工作中,我们研究前两种类型的噪音。 从理论角度来看,标签噪音通常会降低模型的性能 [10],但在某些特定情况下除外 [14]。 通常,可靠的方法依赖于过度拟合规避来处理标签干扰 [15]。 在卫星图像分类[13]、软件质量分类[4]和医学领域分类[12]等许多领域,已经对分类中的噪音效果进行了研究。 据我们所知,尚未发布关于标签干扰对 SBR 分类问题的影响的精确定量研究结果。 在此方案中,尚未确定噪音级别、噪音类型和性能下降之间的精确关系。 此外,值得了解不同的分类器在噪音的存在下的行为。 总体来说,我们没有发现任何系统地研究噪音数据集对软件缺陷报告中不同机器学习算法性能影响的工作。
III. 数据集说明
我们的数据集由 1,073,149 个 bug 标题组成,其中 552,073 个对应于 SBR,521,076 个对应于 NSBR。 这些数据是在 2015 年、2016 年、2017 年和 2018 年Microsoft各个团队收集的。 所有标签都是通过基于签名的 bug 验证系统或人工标记获得的。 数据集中的 Bug 标题非常短的文本,包含大约 10 个单词,并概述了问题。
A. 在数据预处理中,按 bug 标题空格分析每个 bug 标题,从而生成一个标记列表。 我们处理每个令牌列表,如下所示:
删除所有是文件路径的标记
拆分存在以下符号的标记:{、(、)、-、}、{、[、]、}
删除停用词、仅由数字字符组成的标记以及在整个语料库中出现次数少于 5 次的标记。
四。 方法论
训练机器学习模型的过程包括两个主要步骤:将数据编码为特征向量和训练监督机器学习分类器。
A. 特征向量和机器学习技术
第一部分涉及使用 [2] 中所用的术语频率-反转文档频率算法 (TF-IDF) 将数据编码为功能矢量。 TF-IDF 是一种用于权衡术语频率 (TF) 及其反转文档频率 (IDF) 的信息检索技术。 每个单词或术语都有其各自的 TF 和 IDF 分数。 TF-IDF 算法根据文档中出现的次数为该单词分配重要性,更重要的是,它会检查关键字在整个数据集中的标题集合中的重要性。 我们训练并比较了三种分类技术:天真贝叶斯(NB)、提升决策树(AdaBoost)和逻辑回归(LR)。 我们已经选择了这些技术,因为它们已经在基于本宣传资料中的整个报告识别安全 bug 报告的相关任务中表现良好。 这些结果在初步分析中得到确认,其中这三个分类器优于支持向量机和随机森林。 在我们的试验中,我们使用 scikit-learn 库进行编码和模型训练。
B. 噪音类型
本文中所述的干扰是指训练数据的类标签中的干扰。 因此,在出现此类噪音的情况下,学习过程和所得模型会受到错误标记的样本的损害。 我们分析应用于类信息的不同噪音级别的影响。 先前在文献中使用不同的术语讨论了标签噪音的类型。 在我们的工作中,我们分析分类器中两种不同的标签噪音的影响:独立于类的标签噪音,这是通过随机选取实例并更改其标签引入的;依赖于类的噪音,则是指不同的类具有不同的噪音可能性。
a) 与类无关的噪音:与类无关的噪音是指那些与实例的真实类别无关的噪音。 在此类型的干扰中,错误标记 pbr 的概率与数据集中的所有实例相同。 在数据集中引入独立于类的干扰的方法是随机翻转数据集中概率为 pbr 的每个标签。
b) 依赖于类的干扰:依赖于类的干扰是指依赖于实例的真实类的干扰。 在此类型的干扰中,SBR 类中错误标记的概率为 psbr,类 NSBR 中错误标记的概率为 pnsbr。 在数据集中引入依赖于类的干扰的方法是翻转数据集中 true 标签为 SBR 且概率为 psbr 的每个条目。 类似地,我们翻转概率为 pnsbr 的 NSBR 实例的类标签。
c) 单类噪音:单类噪音是类依赖干扰的特殊情况,其中 pnsbr = 0,psbr> 0。 请注意,对于独立于类的干扰,psbr = pnsbr = pbr。
C. 噪声生成
我们的实验调查了 SBR 分类器训练中不同噪音类型和级别的影响。 在我们的试验中,我们将数据集的 25 个% 设置为测试数据,10 个% 设置为验证,65 个% 设置为训练数据。
对于不同级别的 pbr、psbr 和 pnsbr,向训练和验证数据集添加干扰。 我们不会对测试数据集进行任何修改。 使用的不同噪音级别是 P = {0.05 × i|0 < i < 10}。
在类别无关的噪音实验中,对于 pbr ∈ P,我们执行以下操作。
为训练和验证数据集生成干扰;
使用训练数据集训练逻辑回归、天真贝莱斯和 AdaBoost 模型(带有噪音):* 使用验证数据集优化模型(带有干扰):
使用测试数据集测试模型(无噪音)。
在依赖于类的噪声实验中,对于 psbr ∈ P 和 pnsbr ∈ P,我们针对 psbr 和 pnsbr的所有组合执行以下操作:
为训练和验证数据集生成干扰;
使用训练数据集(带有噪音)训练逻辑回归、朴素贝叶斯和 AdaBoost 模型。
使用验证数据集(带有干扰)优化模型;
使用测试数据集测试模型(无噪音)。
V. 实验性结果
在本部分中,分析根据第四节中所述的方法进行的实验结果。
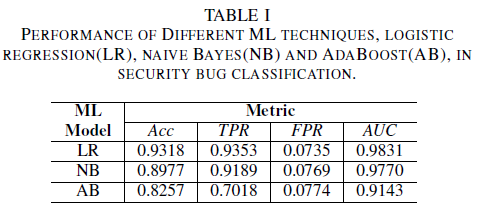
a) 训练数据集中没有噪声时的模型性能:本文的贡献之一是提出了一种机器学习模型,该模型仅使用 bug 标题作为决策依据来识别安全漏洞。 即使开发团队不希望由于存在敏感数据而完全共享 bug 报告,这也能实现机器学习模型的训练。 仅使用 bug 标题进行训练时,我们比较了三个机器学习模型的性能。
逻辑回归模型是性能最佳的分类器。 它是 AUC 值最高的分类器,值为 0.9826,对 FPR 值为 0.0735 的召回率为 0.9353。 与逻辑回归分类器相比,Naive Bayes 分类器的性能略低,AUC 为 0.9779,对于 FPR 值 0.0769,召回率为 0.9189。 与前面提到的两个分类器相比,AdaBoost 分类器的性能较低。 它的 AUC 为 0.9143,对于 0.0774 FPR,召回率为 0.7018。 ROC 曲线下的面积(AUC)是比较多个模型性能的良好指标,因为它可以用一个值来汇总真阳性率(TPR)与假阳性率(FPR)的关系。 在后续分析中,我们将比较分析限制为 AUC 值。
A. 类干扰:单类
可以想象一种方案:默认情况下,所有 bug 都分配给类 NSBR,如果有安全专家审查 bug 存储库,则只会将 bug 分配给类 SBR。 此方案采用单类试验性设置表示,其中我们假设 pnsbr = 0 且 0 < psbr< 0.5。
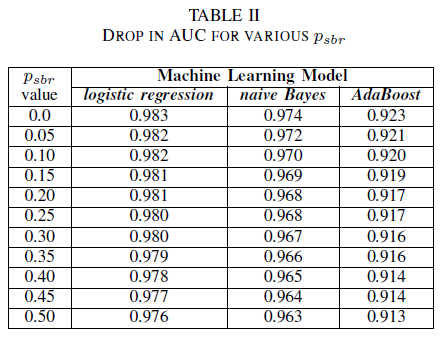
从表 II 中,我们观察到所有三个分类器在 AUC 中的影响很小。 psbr = 0 的训练模型的 AUC-ROC 与 psbr = 0.25 的模型的 AUC-ROC 相比,逻辑回归相差 0.003,Naive Bayes 相差 0.006,AdaBoost 相差 0.006。 对于 psbr = 0.50,每个模型测量的 AUC 与使用 psbr = 0 训练的模型相比,逻辑回归模型差异为 0.007,朴素贝叶斯模型为 0.011,AdaBoost 模型为 0.010。 与天真贝叶斯和 AdaBoost 分类器相比,在存在单类噪音的情况下训练的逻辑回归分类器在其 AUC 指标中呈现了最小的变化,即更可靠的行为。
B. 类干扰:独立于类
我们比较了三种分类器在训练集被独立于类的干扰破坏的情况下的性能。 对于在训练数据中使用不同 pbr 级别训练的每个模型,我们测量其 AUC。
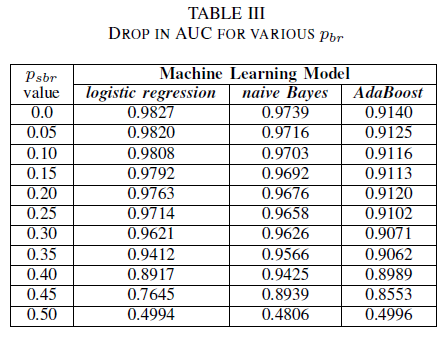
在表 III 中,我们可以看到试验中每个干扰增量的 AUC-ROC 下降。 使用无干扰数据训练的模型中测量的 AUC-ROC 与 pbr = 0.25 的带有独立于类的干扰训练的模型的 AUC-ROC 相比,逻辑回归相差 0.011,Naive Bayes 相差 0.008,AdaBoost 相差 0.0038。 我们观察到当干扰级别低于 40% 时,标签干扰不会对 Naive Bayes 和 AdaBoost 分类器的 AUC 产生明显影响。 另一方面,当标签干扰级别超过 30% 时,逻辑回归分类器会影响 AUC 度量值。
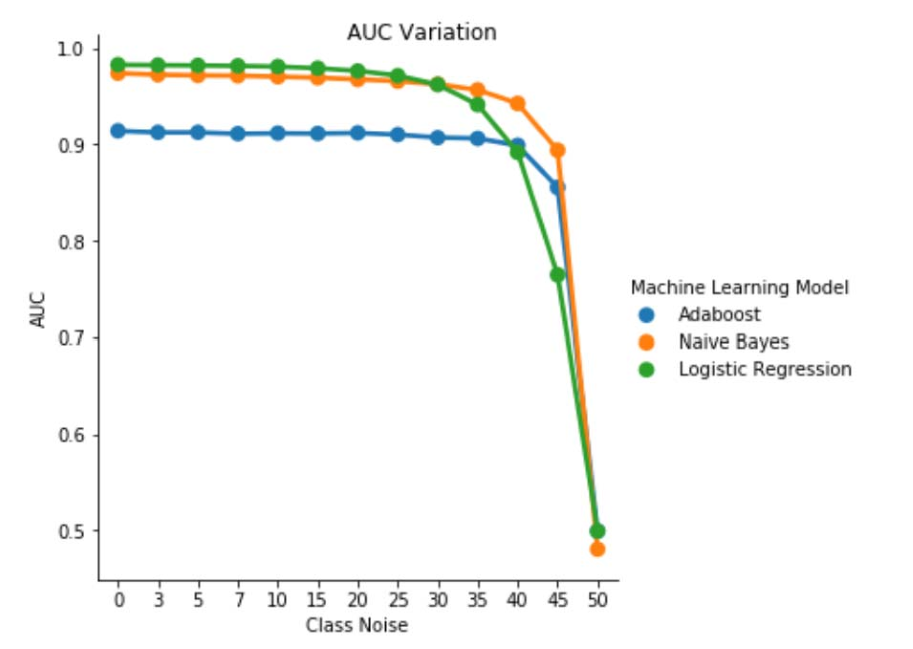
图 1. 独立于类的干扰中 AUC-ROC 的变化。 对于干扰级别 pbr =0.5,分类器的行为类似于随机分类器,即 AUC≈0.5。 但是我们可以观察到,对于较低的噪音水平(pbr ≤ 0.30),逻辑回归学习器与其他两个模型相比,性能更好。 但是,对于 0.35≤ pbr ≤0.45 的范围,朴素贝叶斯学习器提供了更好的 AUCROC 指标。
C. 类干扰:依赖于类
在最后一组试验中,我们考虑了一种方案,其中不同的类包含不同的噪音级别,即 psbr ≠ pnsbr。 我们在训练数据中,将 psbr 和 pnsbr 独立地系统递增 0.05,并观察这三个分类器的行为变化。
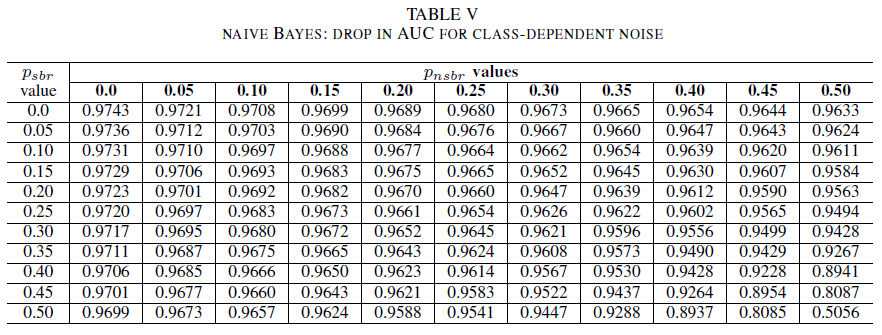
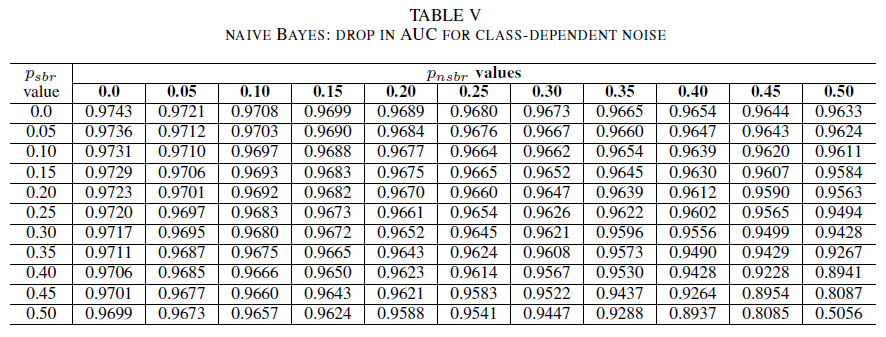
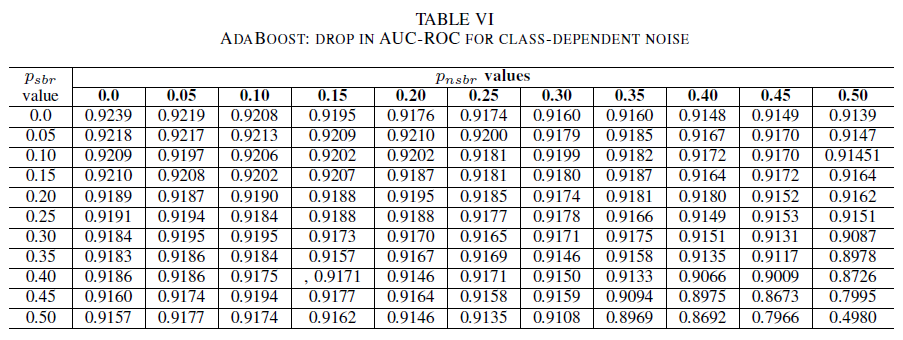
表 IV、V、VI 分别显示对于逻辑回归、Naive Bayes 和 AdaBoost,AUC 随着干扰在每个类中不同级别的增加而产生的变化。 对于所有分类器,我们注意到在两个类都包含30% 以上的干扰级别的情况下对 AUC 指标的影响。 Naive Bayes 表现最可靠。 在负类包含的干扰标签少于等于 30% 的情况下,即使正类中 50% 的标签已翻转,对 AUC 的影响也很小。 在这种情况下,AUC 中的下降值为 0.03。 AdaBoost 展示了所有三个分类器中最可靠的行为。 AUC 中的显著变化仅会发生在两个类别噪声级别超过 45% 的情况下。 在这种情况下,我们开始观察 AUC 衰减大于 0.02。
D. 原始数据集中存在残留干扰
我们的数据集由基于签名的自动化系统和人类专家标记。 此外,所有漏洞报告都经过人类专家的进一步审查并已关闭。 虽然我们预计数据集中的噪音量最小,在统计上并不显著,但残差干扰的存在不会使结论失效。 事实上,举例说明,假设原始数据集被每个条目的独立且同等分布 (i.i.d) 的独立于类的干扰 (0 < p < 1/2) 破坏。
如果我们在原始噪音的基础上,添加一个与类无关的噪音,概率为 pbr i.i.d,则每个条目产生的噪音将为 p∗ = p(1 − pbr )+(1 − p)pbr。 对于 0 < p,pbr< 1/2,我们发现每个标签 p∗ 的实际噪音严格大于我们人为添加到数据集中的噪音 pbr。 因此,如果分类器首先使用完全无噪音的数据集(p = 0)进行训练,分类器的性能会更好。 总之,实际数据集中存在残差干扰意味着分类器的抗干扰能力优于此处显示的结果。 此外,如果数据集内的残留干扰在统计学上相关,则对于绝对低于 0.5 的干扰级别,分类器的 AUC 将变成 0.5(随机推测)。 我们在结果中没有观察到此类行为。
六。 结论和未来工作
我们在本文中的贡献有两个方面。
首先,我们仅根据 bug 报告的标题显示了安全 bug 报告分类的可行性。 这在由于隐私约束而无法提供整个 bug 报告的情况下尤其相关。 例如,在本例中,bug 报告包含密码和加密密钥等私有信息,并且无法训练分类器。 我们的结果显示,即使只有报表标题可用,SBR 标识也能以较高的准确度执行。 使用 TF-IDF 和逻辑回归组合的分类模型在 AUC 为 0.9831 的情况下执行。
其次,我们分析了错误标记的训练和验证数据的效果。 我们比较了三种众所周知的机器学习分类技术(朴素贝叶斯、逻辑回归和 AdaBoost),以评估它们在应对不同噪音类型和噪音级别的鲁棒性。 这三个分类器都对单类噪音非常可靠。 训练数据中的干扰对生成的分类器没有显著影响。 AUC 的降幅非常小(0.01),在噪音水平为 50%的情况下。 对于两类样本中存在且与类无关的噪声,只有当干扰级别大于 40%的数据集被用于训练时,朴素贝叶斯和 AdaBoost 模型的 AUC 才会出现显著变化。
最后,仅当这两个类中的干扰超过 35% 时,依赖于类的干扰才会显著影响 AUC。 AdaBoost 表现出了最稳健性。 在负类包含的干扰标签少于等于 45% 的情况下,即使正类中 50% 的标签有干扰,对 AUC 的影响也很小。 在这种情况下,AUC 中的下降小于 0.03。 据我们所知,这是首次系统研究噪声数据集对安全漏洞报告识别的影响。
未来工作
在本文中,我们开始对机器学习分类器的性能中噪声的影响进行系统性研究,以识别安全漏洞。 在这项工作中,有几个有趣的后续研究,包括:研究噪声数据集对确定安全漏洞严重性级别的影响;了解类别不平衡对已训练模型抵抗噪声能力的影响;理解数据集中故意引入的噪声的效果。
引用
[1] 约翰·安维克、林登·希尤和盖尔·墨菲。 谁应该修复此 bug? 在第28届软件工程国际会议上,第361-370页。 ACM, 2006.
[2] 迪克沙·伯尔、沙伊尔·汉达和阿努贾·阿罗拉。 使用朴素贝叶斯和 TF-IDF 识别和分析安全漏洞的漏洞挖掘工具。 在优化、可靠性和信息技术(ICROIT)国际会议上,2014年,第294-299页。 IEEE, 2014.
[3] 尼古拉·贝滕堡、拉胡尔·普雷姆拉杰、托马斯·齐默曼和宋顺金。 重复的 bug 报告确实被视为有害? 在 软件维护中,2008。ICSM 2008。IEEE 国际会议,第 337-345 页。 IEEE, 2008.
[4] 安德烈斯·福莱科、塔吉·霍什戈夫塔尔、杰森·范·赫尔斯和洛夫顿·布拉德。 识别对低质量数据具有鲁棒性的学习者。 在 信息重用和集成,2008。IRI 2008. IEEE 国际会议。第 190-195 页。 IEEE, 2008.
[5] Benoˆıt Frenay.' 机器学习中的不确定性和标签噪音。 2013年,比利时卢文市卢文天主教大学博士论文。
[6] Benoît Frenay 和 Michel Verleysen. 存在标签噪音时的分类问题:一项综述。 IEEE 神经网络与学习系统汇刊,25(5): 845–869, 2014.
[7] 迈克尔·格吉克、皮特·罗泰拉和陶谢。 通过文本挖掘识别安全漏洞报告:工业案例研究。 在 挖掘软件存储库(MSR),2010年IEEE第7届工作会议上,第11-20页。 IEEE, 2010.
[8] 卡捷琳娜 Goseva-Popstojanova 和雅各布·蒂约。 使用监督和非监督分类通过文本挖掘识别安全相关的 bug 报告。 在 2018 年 IEEE 软件质量、可靠性和安全性国际会议(QRS),第 344-355 页,2018 年。
[9] 艾哈迈德·拉姆坎菲、谢尔盖·德梅耶、伊曼纽尔·吉格和巴特·戈多雷斯。 预测报告中缺陷的严重性。 在 2010 年第七届 IEEE 挖掘软件存储库(MSR)工作会议中,第 1~10 页。 IEEE, 2010.
[10] 纳雷什·曼瓦尼和 PS 萨斯特里。 风险最小化下的噪音容忍度。 IEEE控制论汇刊,43(3):1146–1151, 2013.
[11] G 墨菲和 D 库布拉尼奇。 使用文本分类进行自动 bug 分析。 在第十六届软件工程与知识工程国际会议上。 2004年,Citeseer。
[12] Mykola Pechenizkiy、Alexey Tsymbal、Seppo Puuronen 和 Oleksandr Pechenizkiy。 医学领域的课堂噪音和监督学习:特征提取的影响。 在 null 中,页面 708–713。 IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre, and Gerard Dedieu.´ Effect of training class label noise on classification performances for land cover mapping with satellite image time series. 遥感,9(2):173,2017。
[14] PS 萨斯特里、GD 纳根德拉和纳雷什·曼瓦尼。 一个连续操作动作学习自动机团队,用于对半空间进行抗噪声学习。 IEEE 系统、人与控制论汇刊,第 B 部分(控制论), 40(1):19–28, 2010年。
[15] Choh-Man Teng. 噪音处理技术的比较。 在 FLAIRS Conference 上,页面 269-273,2001 年。
[16] 杜米杜·维贾亚塞卡拉、米洛斯·马尼奇和迈尔斯·麦奎恩。 通过文本挖掘 bug 数据库进行漏洞识别和分类。 在 工业电子学会, IEEE 第40届年度大会 (IECON 2014), 页面 3612–3618。IEEE,2014年。
[17] 新丽杨、大卫·罗、乔黄、新霞、建陵孙。 利用不平衡学习策略自动识别高影响力的错误报告。 在 计算机软件和应用程序会议(COMPSAC),2016 年 IEEE 第 40 届年度第 1 卷,第 227-232 页。 IEEE, 2016.
[18] 德庆祖、志军邓、振力、海金。 通过多类型特性分析自动识别安全漏洞报告。 在 澳大利亚信息安全和隐私大会上,页面 619–633。 斯普林格,2018年。