语义内核提供了许多不同的组件,这些组件可以单独或一起使用。 本文概述了不同的组件,并说明了它们之间的关系。
AI 服务连接器
语义内核 AI 服务连接器提供一个抽象层,该层通过公共接口公开来自不同提供程序的多个 AI 服务类型。 支持的服务包括聊天完成、文本生成、嵌入生成、文本到图像、图像到文本、文本转音频和文本转文本。
当实现注册到内核时,默认情况下,任何对内核的方法调用都将使用聊天完成或文本生成服务。 不会自动使用其他任何受支持的服务。
提示
有关使用 AI 服务的详细信息,请参阅 将 AI 服务添加到语义内核。
矢量存储(内存)连接器
语义内核向量存储连接器提供一个抽象层,通过公共接口来呈现来自不同提供商的向量存储。 内核不会自动使用任何已注册的矢量存储,但矢量搜索可以轻松地作为插件公开到内核,在这种情况下,插件可用于提示模板和聊天完成 AI 模型。
提示
有关使用内存连接器的详细信息,请参阅 将 AI 服务添加到语义内核。
函数和插件
插件命名为函数容器。 每个函数可以包含一个或多个函数。 插件可以注册到内核,这样内核就可以通过两种方式使用它们:
- 将它们推广给聊天AI,以便AI可以选择它们进行调用。
- 使其在模板渲染过程中可以被调用。
可以轻松地从许多来源创建函数,包括原生代码、OpenAPI 规范、RAG 场景的ITextSearch实现以及提示模板。

提示
有关不同插件源的详细信息,请参阅 什么是插件?。
提示
有关用于聊天补全 AI 的广告插件的详细信息,请参阅 使用聊天补全的函数调用。
提示模板
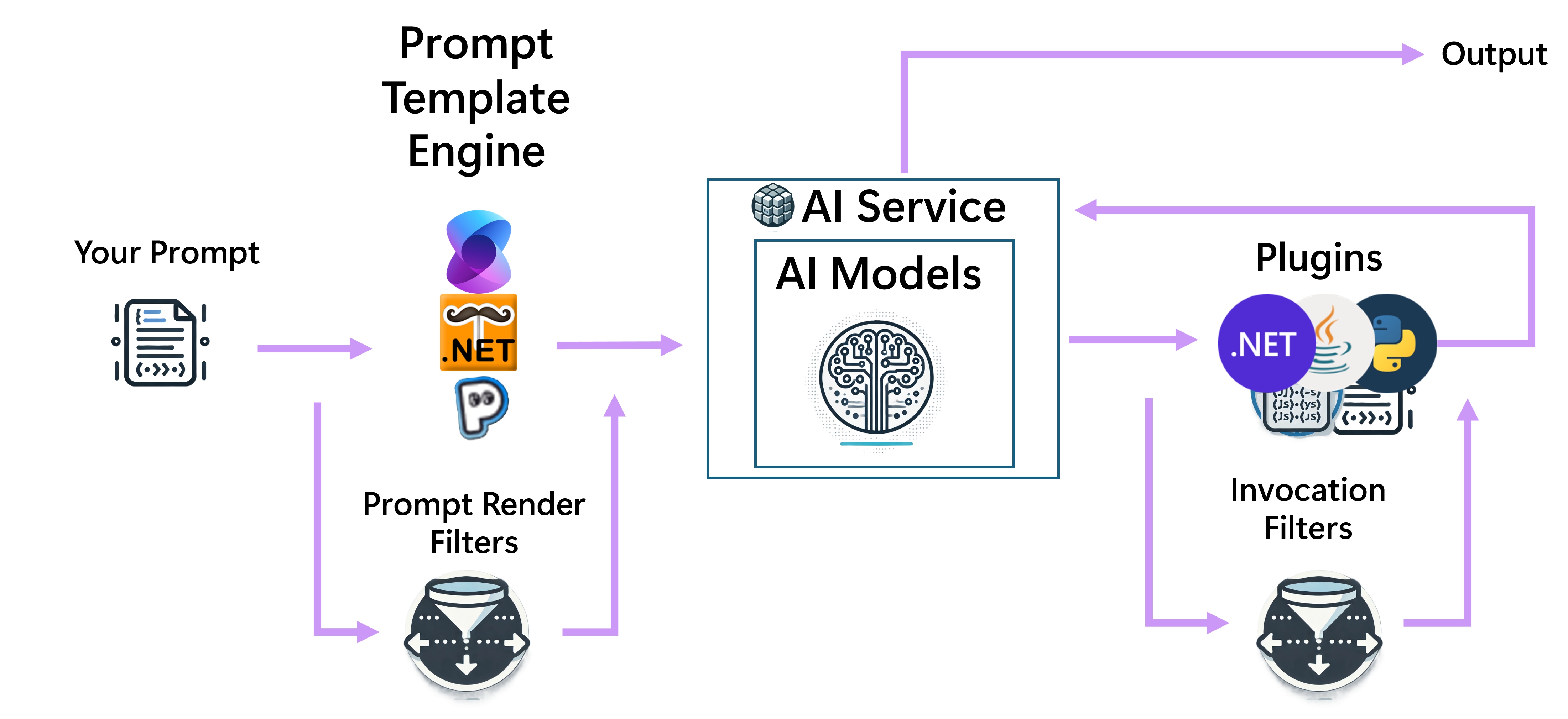
提示模板允许开发人员或提示工程师创建一个模板,该模板将 AI 的上下文和说明与用户输入和函数输出混合在一起。 例如,模板可能包含对聊天完成 AI 模型的指令、用户输入的占位符,以及在调用聊天完成 AI 模型之前必须执行的插件硬编码调用。
可以通过两种方式使用提示模板:
- 作为聊天完成流的起点,请内核呈现模板,并使用呈现的结果调用聊天完成 AI 模型。
- 作为插件函数,以便可以像调用任何其他函数一样调用它。
使用提示模板时,首先将呈现该模板,并执行其中任何硬编码的函数引用。 然后,呈现的提示将传递给聊天完成 AI 模型。 AI 生成的结果将返回到调用方。 如果提示模板已注册为插件函数,则可能会选择该函数供聊天完成 AI 模型执行。在这种情况下,调用者是语义内核,代表 AI 模型进行调用。
以这种方式使用提示模板作为插件函数可能会导致相当复杂的流。 例如,考虑将提示模板 A 注册为插件的方案。
同时,可能会将不同的提示模板 B 传递给内核以启动聊天完成流。
B 可以硬编码调用 A。
这将导致以下步骤:
-
B的渲染开始,系统在执行时找到了对A的引用。 - 呈现
A。 -
A的呈现输出将传递给聊天完成 AI 模型。 - 聊天完成功能的 AI 模型的结果将返回到
B。 - 呈现
B完成。 -
B的呈现输出将传递给聊天完成 AI 模型。 - 聊天完成 AI 模型的结果将返回给调用方。
另请考虑这样一种情况:从 B 到 A没有硬编码调用。
如果启用了函数调用,聊天完成 AI 模型仍可能决定应调用 A,因为它需要 A 可以提供的数据或功能。
将提示模板注册为插件函数可以创建使用人类语言而不是实际代码描述的功能。 将该功能分离为插件允许 AI 模型在主要执行流之外进行单独推理,可能会使 AI 模型提高成功率,因为这样它可以一次专注于一个问题。
要了解从提示模板启动的简单流程,请参阅下图。

提示
有关提示模板的详细信息,请参阅 什么是提示?。
过滤 器
筛选器提供了在聊天完成流期间执行特定事件前后自定义操作的方法。 这些事件包括:
- 函数调用的前后
- 提示呈现前后。
需要向内核注册筛选器,才能在聊天完成流期间调用筛选器。
请注意,由于在执行前始终将提示模板转换为 KernelFunction,因此将为提示模板调用函数和提示筛选器。 由于筛选器在多个可用时会嵌套,因此函数型筛选器是外部筛选器,而提示型筛选器是内部筛选器。
提示
有关筛选器的详细信息,请参阅 什么是筛选器?。