在 Azure Data Studio 中使用 Jupyter Notebook
适用于:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Jupyter Notebook 是一种开源 Web 应用程序,可用于创建和共享包含实时代码、公式、可视化效果和叙述性文本的文档。 使用情况包括数据清理和转换、数值模拟、统计建模、数据可视化和机器学习。
本文介绍如何在最新版的 Azure Data Studio 中创建新笔记本,以及如何使用不同的内核开始创作自己的笔记本。
观看此短暂的 5 分钟视频,了解 Azure Data Studio 中的笔记本简介:
创建笔记本
可以通过多种方式创建新的笔记本。 在每种情况下,都会打开名为 Notebook-1.ipynb 的新文件。
转到 Azure Data Studio 中的“文件菜单”,然后选择“新建笔记本” 。
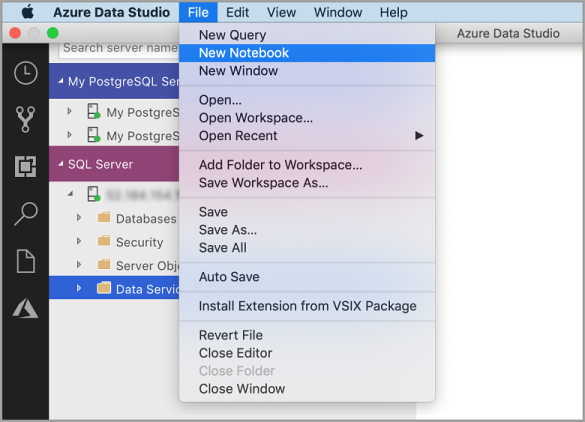
右键单击“SQL Server”连接,然后选择“新建笔记本” 。
打开命令面板 (Ctrl+Shift+P),键入“new notebook”,然后选择“New Notebook”命令 。

连接到内核
Azure Data Studio 笔记本支持多种不同的内核,包括 SQL Server、Python、PySpark 等。 每个内核在笔记本的代码单元中支持不同的语言。 例如,在连接到 SQL Server 内核时,可以在笔记本代码单元格中输入并运行 T-SQL 语句。
“附加到”提供内核的上下文。 例如,如果使用的是 SQL 内核,则可以附加到任何 SQL Server 实例。 如果使用的是 Python3 内核附加到 localhost,可将此内核用于本地 Python 开发。
SQL 内核还可用于连接到 PostgreSQL 服务器实例。 如果你是 PostgreSQL 开发人员,并想要将笔记本连接到 PostgreSQL 服务器,请在 Azure Data Studio 扩展市场中下载 PostgreSQL 扩展,然后连接到 PostgreSQL 服务器。
如果已连接到 SQL Server 2019 大数据群集,则默认“附加到”是群集的终点。 可以使用群集的 Spark 计算提交 Python、Scala 和 R 代码。
| 内核 | 说明 |
|---|---|
| SQL 内核 | 编写面向关系数据库的 SQL 代码。 |
| PySpark3 和 PySpark 内核 | 使用群集中的 Spark 计算编写 Python 代码。 |
| Spark 内核 | 使用群集中的 Spark 计算编写 Scala 和 R 代码。 |
| Python 内核 | 编写用于本地开发的 Python 代码。 |
有关特定内核的详细信息,请参阅:
- 创建和运行 SQL Server 笔记本
- 创建和运行 Python 笔记本
- Azure Data Studio 中的 Kqlmagic 扩展 - 它扩展了 Python 内核的功能
添加代码单元格
使用代码单元格,可以在笔记本中以交互方式运行代码。
通过单击工具栏中的“+单元格”命令并选择“代码单元格”,添加一个新的代码单元格 。 新的代码单元格将添加到当前选定的单元格之后。
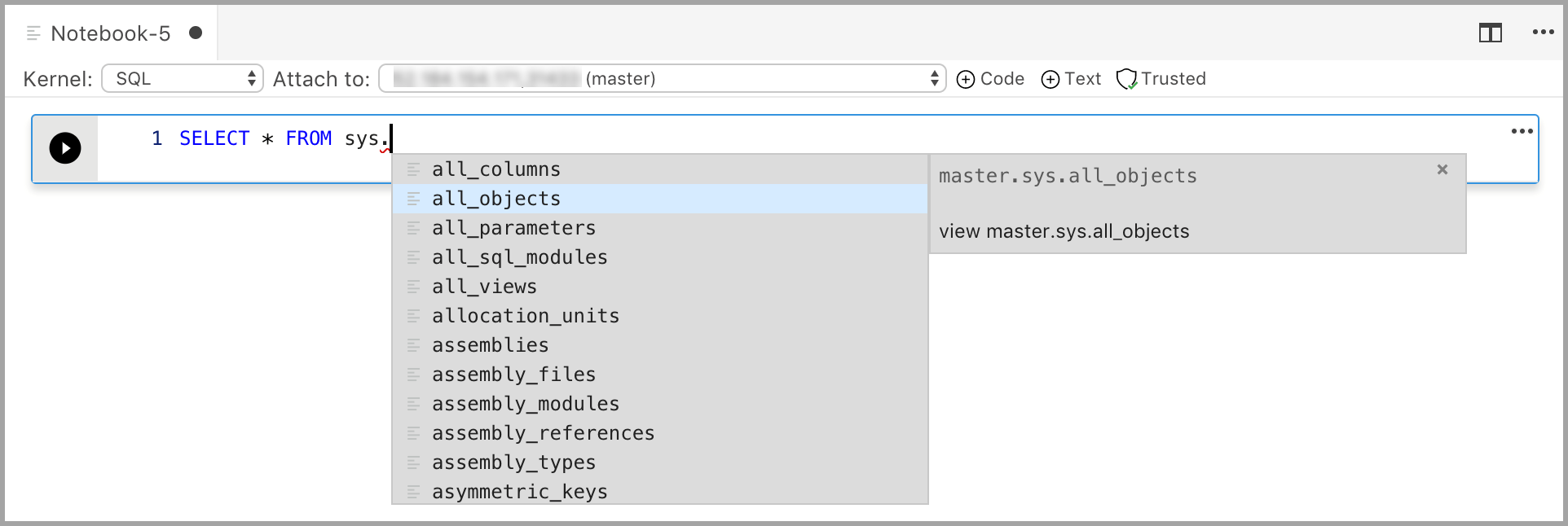
在单元格中为所选内核输入代码。 例如,如果使用的是 SQL 内核,则可以在代码单元格中输入 T-SQL 命令。
使用 SQL 内核输入代码类似于 SQL 查询编辑器。 代码单元格通过丰富的 SQL 编辑器、IntelliSense 和内置代码片段等内置功能支持新式 SQL 编码体验。 通过代码片段,可以生成正确的 SQL 语法来创建数据库、表、视图、存储过程,还可以更新现有的数据库对象。 使用代码片段快速创建用于开发或测试的数据库副本,然后生成并执行脚本。
添加文本单元格
使用文本单元格可通过在代码单元格之间添加 Markdown 文本块来记录代码。
通过单击工具栏中的“+单元格”命令并选择“文本单元格”,添加一个新的文本单元格 。
单元格在编辑模式下开始,可以在其中键入 Markdown 文本。 键入时,预览如下所示。
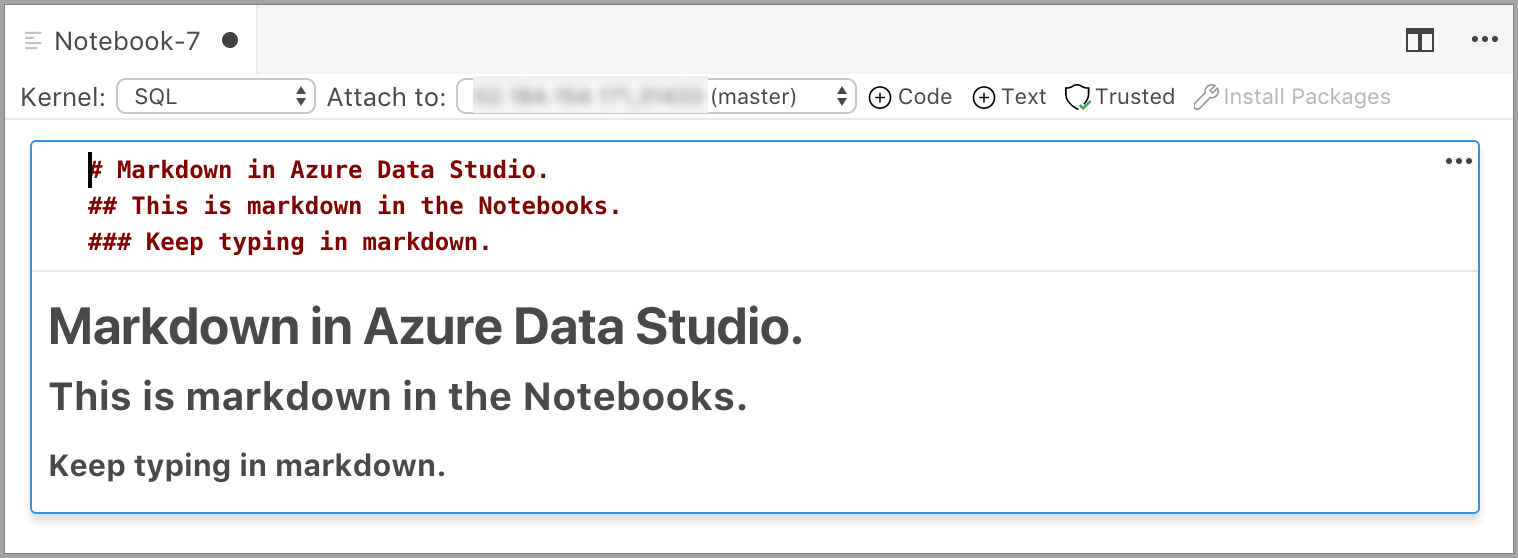
选择文本单元格外部即可显示 Markdown 文本。
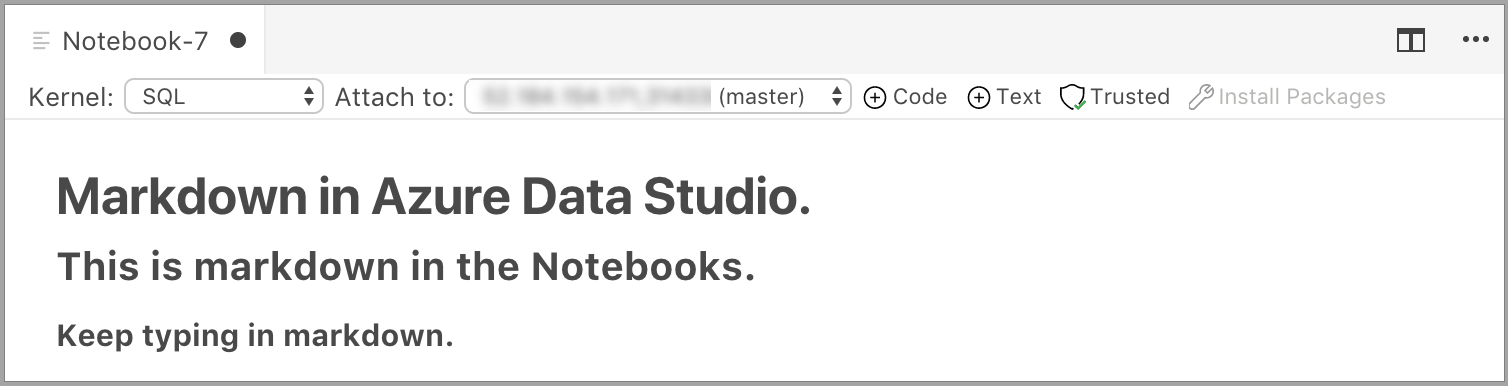
如果再次单击文本单元格,它将更改为编辑模式。
运行单元格
若要运行单个单元格,请单击单元格左侧的“运行单元格”(圆形黑色箭头),或选择此单元格并按 F5。 可以通过单击工具栏中的“全部运行”来运行笔记本中的所有单元格,每次运行一个单元格,如果在单元格中遇到错误,则执行停止。
单元格的结果显示在单元格下方。 可以通过选择工具栏中的“清除结果”按钮,清除笔记本中所有已执行单元格的结果。
保存笔记本
若要保存笔记本,请执行以下操作之一。
- 键入 Ctrl+S
- 在“文件”菜单中选择“保存”
- 在“文件”菜单中选择“另存为”
- 在“文件”菜单中选择“全部保存”,可保存所有打开的笔记本
- 在命令面板中,输入“File:Save”
笔记本保存为 .ipynb 文件。
受信任与不受信任
在 Azure Data Studio 中打开的笔记本默认为“受信任”。
如果从其他源打开笔记本,它会在“不受信任”模式下打开,然后你可以将其设为“受信任” 。
示例
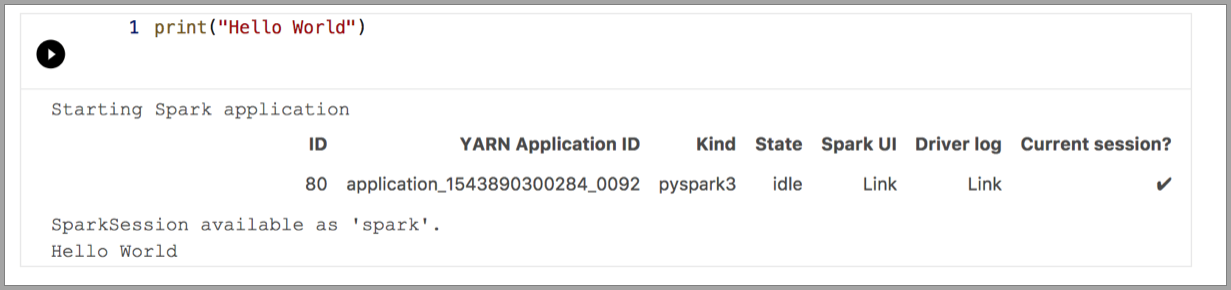
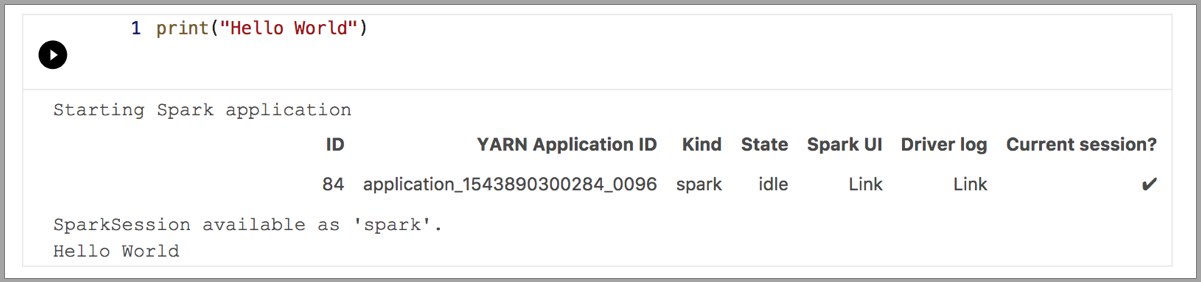
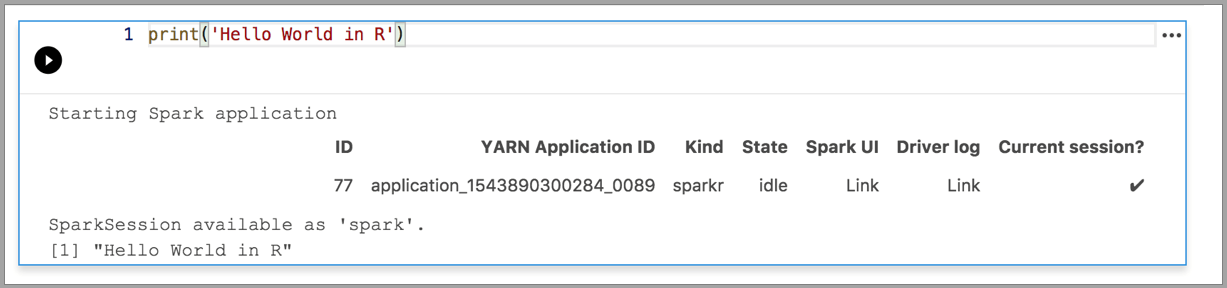
以下示例演示了如何使用不同的内核来运行简单的“Hello World”命令。 选择内核,在单元格中输入示例代码,然后单击“运行单元格”。
Pyspark
Spark | Scala 语言
Spark | R 语言
Python 3

后续步骤
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈