适用于:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Microsoft SQL Server 2019 大数据群集已停用。 对 SQL Server 2019 大数据群集的支持已于 2025 年 2 月 28 日结束。 有关详细信息,请参阅Microsoft SQL Server 平台上的公告博客文章和大数据选项。
SQL Server 为包含部署笔记本的 Azure Data Studio 提供扩展。 部署笔记本包含可在 Azure Data Studio 中用于创建 SQL Server 大数据群集的文档和代码。
笔记本最初是作为开放源代码项目实现的,现已在 Azure Data Studio 中实现。 可以在文本单元格中使用 markdown 作为文本,并使用其中一个可用核心在代码单元格中编写代码。
可以使用笔记本来部署 SQL Server 大数据群集。
Prerequisites
若要启动笔记本,还需要满足以下必备条件:
- 已安装 Azure Data Studio 预览体验内部版本的最新版本
除此之外,部署大数据群集还需要:
启动笔记本
启动 Azure Data Studio。
在“连接”选项卡上,选择省略号 (...),然后选择“部署 SQL Server...” 。
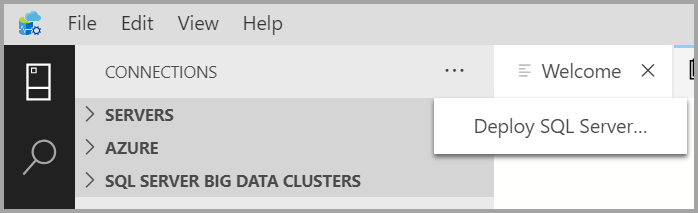
从部署选项中选择“SQL Server 大数据群集” 。
在“选项”下的“部署目标”中,选择“新建 Azure Kubernetes 群集”或“现有 Azure Kubernetes 服务群集” 。
接受隐私和许可条款。
此对话框还会检查主机上是否存在部署所选类型的 SQL 所需的工具。 工具检查成功后才会启用“选择”按钮 。
选择“选择”按钮 。 此操作将启动部署体验。
设置部署配置模板
可以按照以下说明自定义部署配置文件的设置。
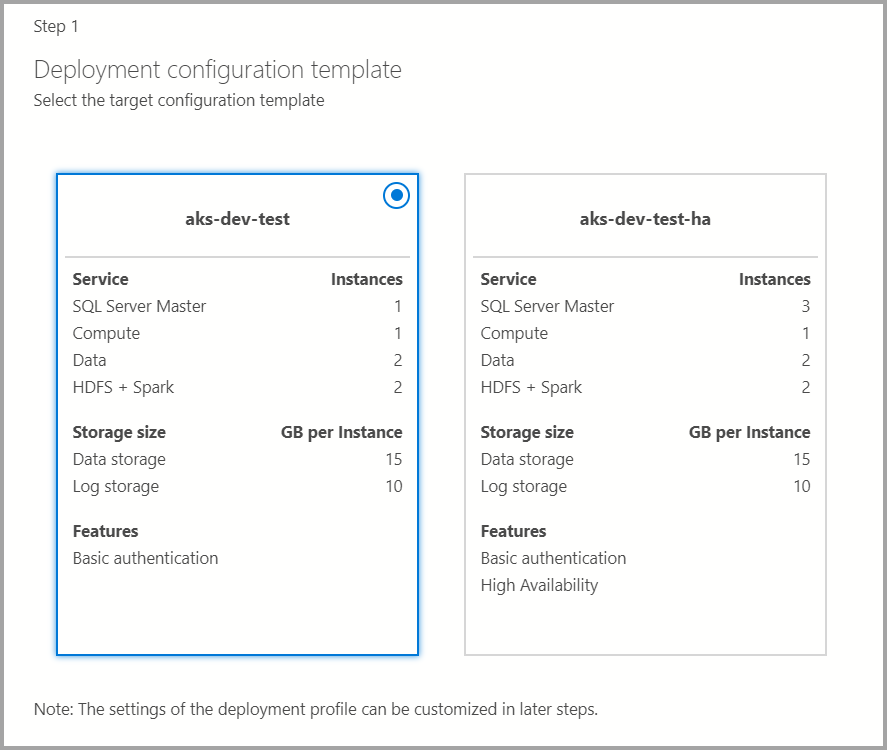
目标配置模板
从可用模板中选择目标配置模板。 可用的配置文件是根据前一对话框中选择的部署目标类型来筛选的。
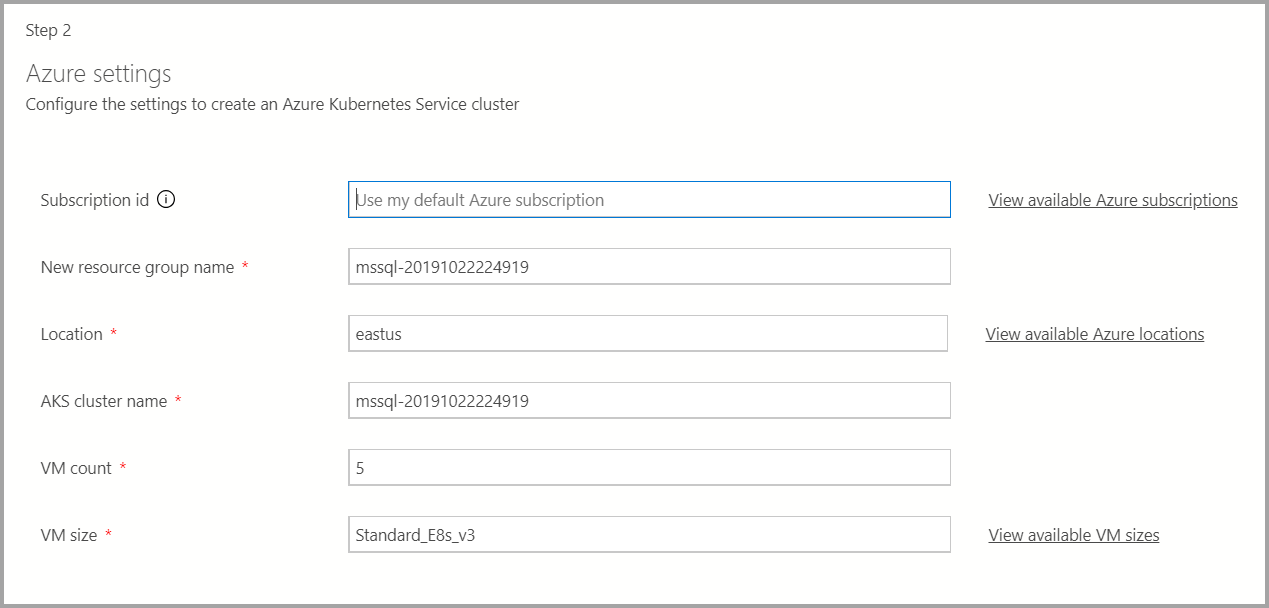
Azure settings
如果部署目标是新的 Azure Kubernetes 服务 (AKS),则需要使用额外的信息(例如 Azure 订阅 ID、资源组、AKS 群集名称、VM 计数、大小和其他附加信息)来创建 AKS 群集。
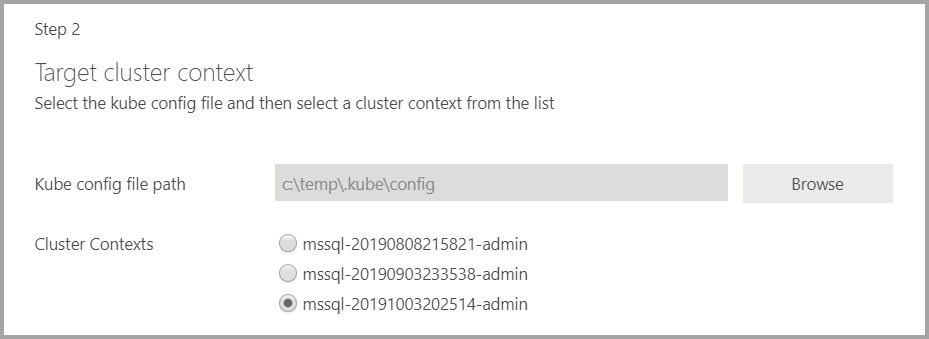
如果部署目标是现有的 Kubernetes 群集,向导则会提示你输入 kube 配置文件的路径以导入 Kubernetes 群集设置 。 请确保选择适当的群集上下文,可在其中部署 SQL Server 2019 大数据群集。
群集、docker 和 AD 设置
输入大数据群集的群集名称、管理员用户名和密码。 控制器和 SQL Server 使用的是与此相同的帐户。
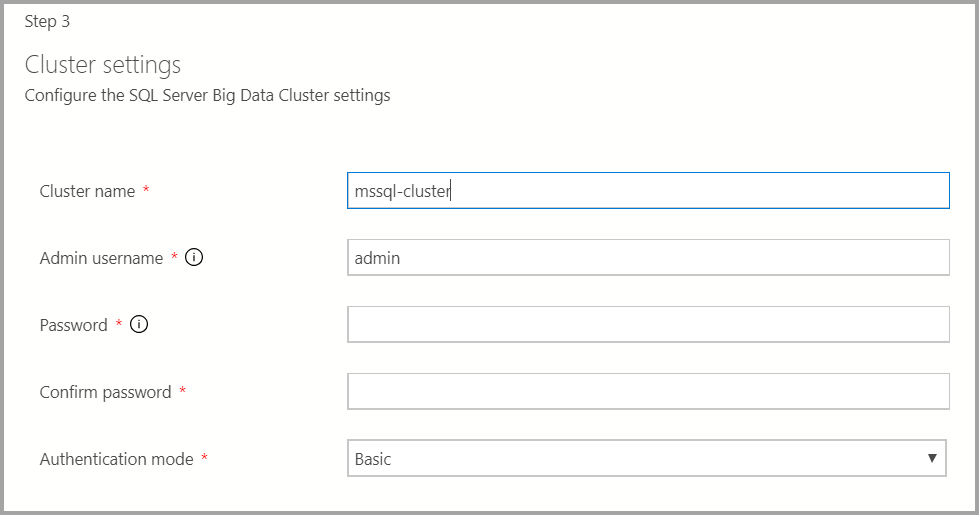
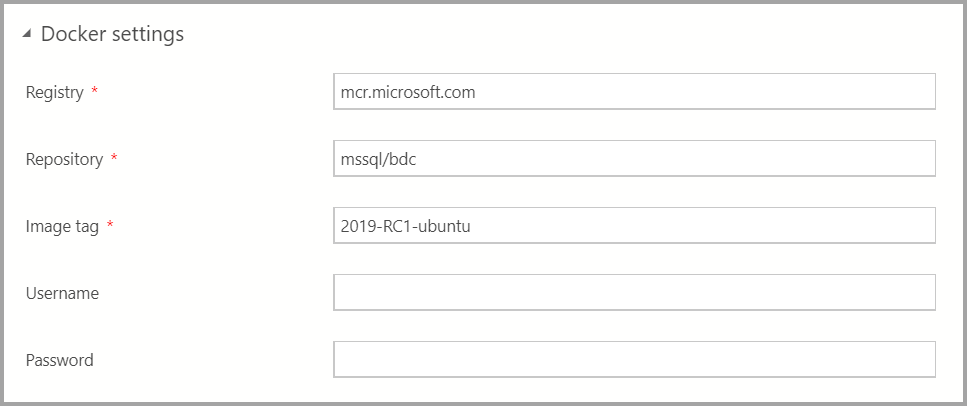
输入适当的 Docker 设置。
Important
确保映像标记字段是最新的:2019-CU13-ubuntu-20.04
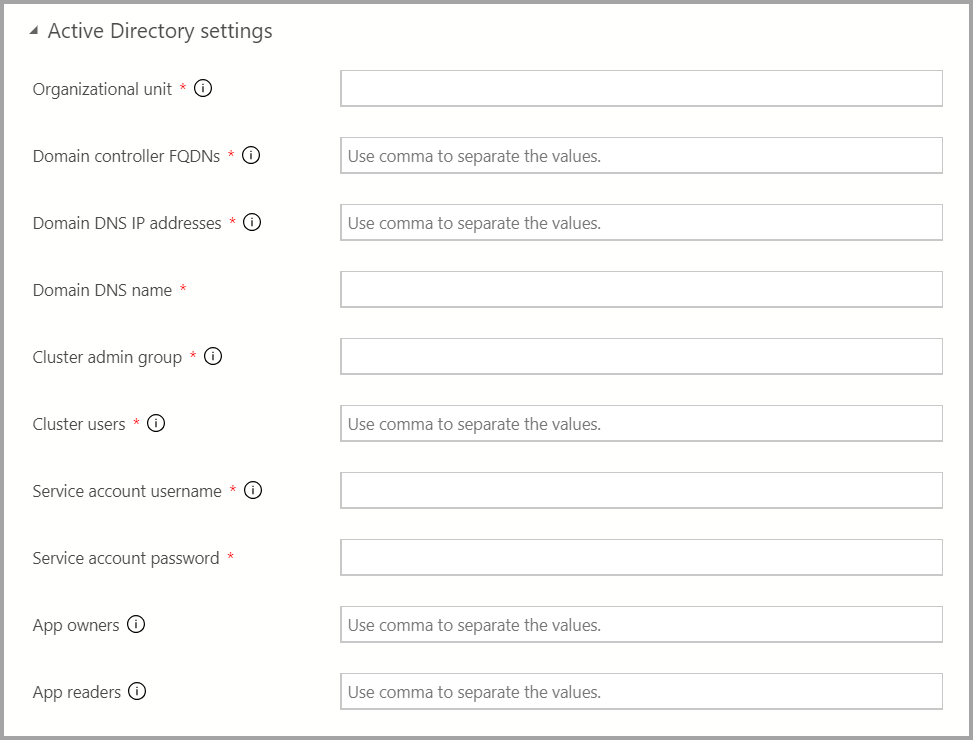
如果 AD 身份验证可用,请输入 AD 设置。
Service settings
此屏幕中包含各种设置的输入,例如“缩放”、“终结点”、“存储”和其他的“高级存储设置” 。 输入适当的值,然后选择“下一步”。
Scale settings
输入大数据群集中每个组件的实例数量。
Spark 实例可以随 HDFS 一起提供。 它包含在存储池中,或者单独位于 Spark 池中。
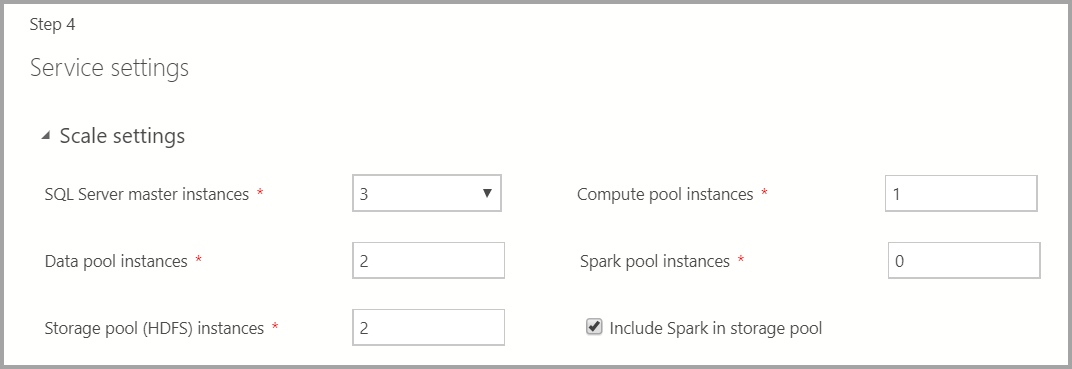
有关这些组件的其他信息,可以参考主实例、数据池、存储池或计算池。
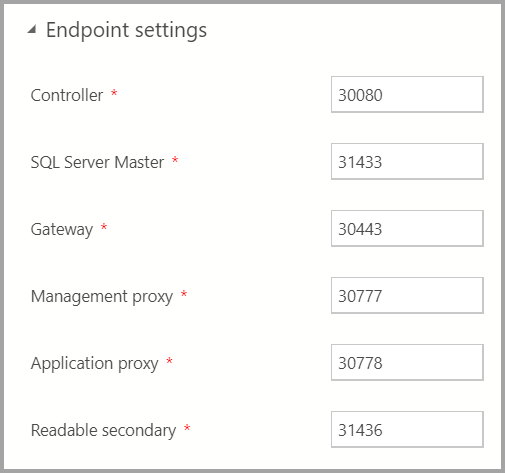
Endpoint settings
已预填充了默认的终结点。 但可以对它们进行适当的更改。
Storage settings
存储设置包括数据和日志的存储类和声明大小。 这些设置可应用于存储、数据和 SQL Server 主池。

高级存储设置
可以在“高级存储设置”下添加其他存储设置
存储池 (HDFS)
Data pool
SQL服务器大师

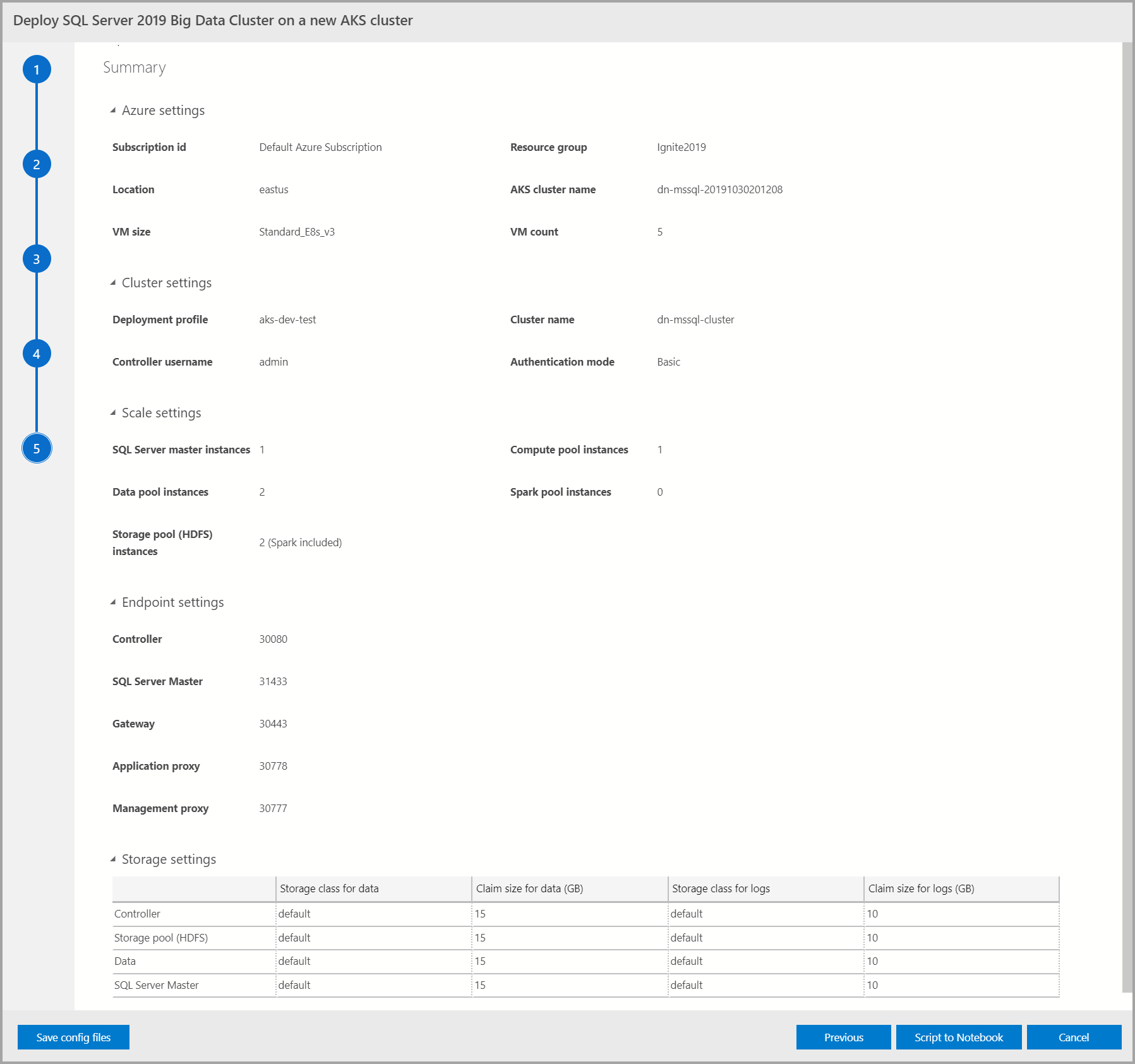
Summary
此屏幕中汇总了为部署大数据群集而提供的所有输入。 可以通过“保存配置文件”按钮下载配置文件 。 选择“在笔记本中编写脚本”,以在笔记本中编写整个部署配置的脚本。 打开该笔记本后,选择“运行单元格”开始将大数据群集部署到所选目标。
Next steps
有关部署的详细信息,请参阅 SQL Server 大数据群集部署指南。