硬件、软件和群集配置的差异以及运行时间和性能的不同应用程序要求需要针对租用、群集和运行状况检查超时值进行特定配置。 某些应用程序和工作负载需要更积极的监控才能限制硬故障后的停机时间。 其他需要对临时网络问题有更大的容忍度和高资源使用率的等待时间,而对于较慢的故障转移则可以。
每个节点上的多个服务都可以检测故障。 群集服务可以检测仲裁丢失,资源 DLL 可以检测由 Always On 运行状况检测呈现的问题,也可以直接在主实例上启动手动故障转移。 群集服务、资源主机和 SQL Server 实例通过 RPC、共享内存和 T-SQL 相互同步。 在大多数情况下,这些服务能够成功通信,但即使在同一台计算机上的服务之间,该通信也不是完全可靠的。 此外,可用性组 (AG) 需要能够承受系统范围的事件(如网络和磁盘故障),这可能会阻止通信或中断功能。 由于许多故障情况和服务之间没有完全可靠的通信,AG 依赖于各种故障转移检测机制来相互独立地检测和响应故障,因此群集状态对于所有节点来说始终保持一致。
SQL Server 2025 运行状况检查的超时诊断能力得到改进
CPU、磁盘延迟或内存耗尽等资源约束可能会触发 AlwaysOn 可用性组租约超时。 在群集日志中报告租约超时时,Windows 故障转移群集日志中报告 CPU 利用率、内存利用率和磁盘读取和写入延迟的最新性能监视器数据以及租约超时。
同样,资源限制也可能引发健康检查超时。 从 SQL Server 2025(17.x)预览版开始,当检测到运行状况检查超时时,Windows 故障转移群集日志中会报告相同的性能监视器计数器,类似于租约超时的诊断输出。
下面是针对健康检查超时的改进版 Windows 故障转移群集日志输出示例:
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] AG health check failed, logging perf counter data collected so far
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:25.0, 21.857418, 3248349184.000000, 0.000000, 0.000253
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:35.0, 11.442071, 3255394304.000000, 0.000907, 0.000382
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:45.0, 9.979768, 3253981184.000000, 0.000415, 0.000549
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:55.0, 9.762850, 3251232768.000000, 0.001989, 0.000638
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:56:5.0, 9.827234, 3250462720.000000, 0.002250, 0.001418
群集节点和资源检测
群集中的每个节点都运行一个群集服务,该服务运行故障转移群集并监视所有群集资源。 资源主机作为单独的进程运行,并且是群集服务和群集资源之间的接口。 资源主机在群集服务调用时对群集资源执行操作。 群集感知应用程序(如 SQL Server)通过资源 DLL 提供到资源监视器的自定义接口。 资源 DLL 实现自定义资源的联机和脱机操作和运行状况监视。 资源主机是群集服务的子进程,并在群集服务终止时被终止。
对于 SQL Server,AG 资源 DLL 基于 AG 租用机制和 Always On 运行状况检测来确定 AG 的运行状况。 AG 资源 DLL 通过 IsAlive 操作公开资源运行状况。 资源监视器按照由 IsAlive 和 CrossSubnetDelay 群集范围内的值设置的群集检测信号间隔轮询 SameSubnetDelay。 在主节点上,只要资源 DLL 的 IsAlive 调用返回的 AG 运行不正常,群集服务就会启动故障转移。
群集服务将检测信号发送到群集中的其他节点,并确认从它们接收到的检测信号。 当一个节点检测到来自一系列未确认检测信号的通信故障时,它会广播一条消息,导致所有可访问的节点协调其群集节点运行状况的视图。 这个称为 “重组事件”的事件会保持所有节点的群集状态的一致性。 在重组事件之后,如果仲裁丢失,则包括此分区中的 AG 在内的所有群集资源都将脱机。 该分区中的所有节点都转换为解析状态。 如果存在一个保留仲裁的分区,则 AG 将分配给该分区中的一个节点并成为主副本,而所有其他节点将成为辅助副本。
Always On 运行状况检测
Always On 资源 DLL 监视内部 SQL Server 组件的状态。
sp_server_diagnostics 在由 HealthCheckTimeout 控制的时间间隔内报告这些 SQL Server 组件的运行状况。
sp_server_diagnostics 报告五个实例级别组件的运行状况:系统、资源、查询处理、io 子系统和事件。 它还报告每个 AG 的运行状况。 每次更新时,资源 DLL 根据 AG 的故障级别更新 AG 资源的运行状况。 当数据由 sp_server_diagnostics 返回时,它会将每个组件显示为干净、警告、错误或未知状态,并使用一些描述组件状态的 XML 数据。 对于运行状况检测,资源 DLL 仅在组件处于错误状态时才采取行动。
如果运行状况检测无法报告资源 DLL 在多个时间间隔内的更新,那么 AG 将被视为运行不正常,并将报告有关 IsAlive 调用的故障。
租用机制
与其他故障转移机制不同,SQL Server 实例在租用机制中发挥着积极的作用。 租用机制用于充当群集资源主机与 SQL Server 进程之间的“表面活跃度”验证机制。 该机制用于确保双方(群集服务器和 SQL Server 服务)通信频繁,检查彼此的状态并最终避免出现裂脑情况。 使 AG 作为主副本联机时,SQL Server 实例会为 AG 生成一个专用的租用工作进程线程。 租用工作进程与包含续租和租用停止事件的资源主机共享一小块内存区域。 租用工作进程和资源主机以循环方式工作,发出信号通知各自的续租事件,然后休眠,等待另一方发出信号通知自己的续租事件或停止事件。 资源主机和 SQL Server 租用线程都会维护一个生存时间值,每次线程在由另一个线程发出信号后唤醒时都会更新这个值。 如果在等待信号时达到生存时间,则租约到期,然后将副本转换到该特定 AG 的解析状态。 如果发出信号通知租用停止事件,则副本将转换为解析角色。
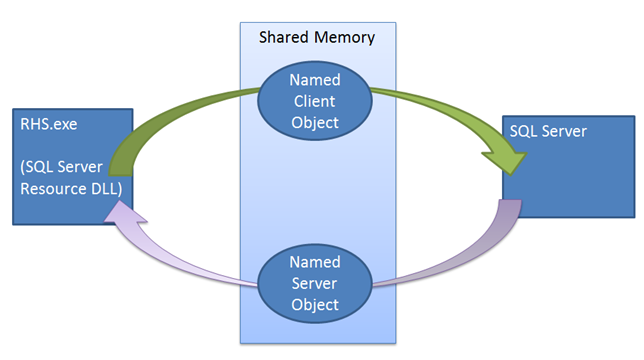
租用机制强制执行 SQL Server 和 Windows Server 故障转移群集之间的同步。 发出故障转移命令时,群集服务会对当前主副本的资源 DLL 进行 Offline 调用。 资源 DLL 首先尝试使用存储过程使 AG 脱机。 如果此存储过程失败或超时,则会将失败报告回群集服务,然后发出终止命令。 终止再次尝试执行相同的存储过程,但使 AG 在一个新副本上联机之前,群集这次不会等待资源 DLL 报告成功或失败。 如果第二个过程调用失败,那么资源主机将不得不依赖租用机制使实例脱机。 调用资源 DLL 使 AG 脱机时,资源 DLL 会发出租用停止事件的信号,唤醒 SQL Server 租用工作线程使 AG 脱机。 即使未发出停止事件的信号,租用也将过期,并且副本将转换为解析状态。
租用主要是主实例和群集之间的同步机制,但它也可以创建无需故障转移的故障条件。 例如,高 CPU 使用率、内存不足的情况(虚拟内存较低、进程分页)、SQL 进程在生成内存转储时无响应、系统无响应、群集 (WSFC) 脱机(例如由仲裁丢失所致)会阻止 SQL 实例续租并导致重启或故障转移。
群集超时值的准则
仔细考虑权衡之策并了解对 SQL Server 群集进行不太积极的监视的后果。 增加群集超时值将增加对临时网络问题的容忍度,但会减慢对硬故障的反应。 增加处理资源压力或大范围地域延迟所需的超时值,将增加从硬故障或不可恢复故障中恢复的时间。 虽然这对许多应用程序都是可以接受的,但在任何情况下都不是理想之选。
默认设置经过优化,可以快速响应硬故障症状并限制停机时间,但这些设置对于某些工作负载和配置也可能过于积极。 不建议将 LeaseTimeout、CrossSubnetDelay、CrossSubnetThreshold、SameSubnetDelay、SameSubnetThreshold 或 HealthCheckTimeout 中的任何一项降低到默认值以上。 每个部署的正确设置会有所不同,可能需要较长时间的微调才能发现。 在对这些值进行更改时,请逐步进行并考虑这些值之间的关系和依赖关系。
群集超时与租用超时之间的关系
租用机制的主要功能是:如果在执行到另一个节点的故障转移时群集服务无法与实例通信,则脱机采用 SQL Server 资源。 当群集对 AG 群集资源执行脱机操作时,群集服务会对 rhs.exe 执行 RPC 调用以使资源脱机。 资源 DLL 使用存储过程通知 SQL Server 以使 AG 脱机,但此存储过程可能失败或超时。资源主机也会在脱机调用期间停止自己的续租线程。 在最坏的情况下,SQL Server 将导致租用在 ½ * LeaseTimeout 内过期并将实例转换为解析状态。 故障转移可以由多个不同方发起,但至关重要的是群集状态视图在整个群集和不同 SQL Server 实例上一致。 例如,假设主实例与群集其余部分失去连接。 由于群集超时值,群集中的每个节点都会在相似时间确定故障,但只有主节点可以与主 SQL Server 实例交互以强制它放弃主角色。
从主节点的角度来看,群集服务将丢失仲裁,服务将开始自行终止。 群集服务将对资源主机发出一个 RPC 调用来终止该进程。 此终止调用负责让 AG 在 SQL Server 实例上脱机。 此脱机调用通过 T-SQL 完成,但不能保证 SQL 和资源 DLL 之间的连接将成功建立。
从群集其余部分的角度来看,目前没有主副本,它将为集群中的其余节点投票并建立一个新的主副本。 如果由资源 DLL 调用的存储过程失败或超时,则群集可能容易受“裂脑”情况的影响。
租用超时可防止在发生通信错误时出现“裂脑”情况。 即使所有通信都失败,资源 DLL 进程也会终止并无法更新租用。 一旦租用到期,它将使 AG 自行脱机。 SQL Server 的实例需要知道,在群集建立新副本之前,它不再托管主副本。 由于负责选择新的主副本的群集的其余部分无法与当前的主副本协调,因此超时值可确保在当前的主副本自行脱机之前不会创建新的主副本。
当群集故障转移时,托管以前的主副本的 SQL Server 实例必须在新的主副本联机之前转换到解析状态。 任何时候 SQL Server 租用线程的剩余生存时间为 ½ * LeaseTimeout,因为无论何时续租,新的生存时间将更新为 LeaseInterval 或 ½ * LeaseTimeout。 如果群集服务或资源主机停止或终止而没有发出租用停止事件的信号,则群集将在 SameSubnetThreshold\ SameSubnetDelay 毫秒后声明主节点已停止。 在这段时间内,租用必须到期,以确保主群集处于脱机状态。 由于租用超时的最长生存时间为 ½ * LeaseTimeout,所以 ½ * LeaseTimeout 必须小于 SameSubnetThreshold * SameSubnetDelay。
SameSubnetThreshold \<= CrossSubnetThreshold 和 SameSubnetDelay \<= CrossSubnetDelay 应适用于所有 SQL Server 群集。
运行状况检查超时操作
运行状况检查超时更加灵活,因为没有其他的故障转移机制直接依赖它。 默认值 30 秒将 sp_server_diagnostics 间隔设置为 10 秒,超时和间隔的最小值分别为 15 秒和 5 秒。 一般来说,sp_server_diagnostics 更新间隔始终为 1/3 * HealthCheckTimeout。 如果资源 DLL 在一个时间间隔内都没有收到一组新的运行状况数据,则它将继续使用前一时间间隔的运行状况数据来确定当前的 AG 和实例运行状况。 增加运行状况检查超时值会增加主群集对 CPU 压力的容忍度,这可能会阻止 sp_server_diagnostics 在每个时间间隔内提供新数据,但它依赖过时数据运行状况检查的时间更长。 无论超时值如何,收到数据表明副本不正常后,下个 IsAlive 调用将返回实例不正常,群集服务将启动故障转移。
AG 的故障条件级别改变了运行状况检查的故障条件。 对于任何失败级别,如果 AG 元素被 sp_server_diagnostics 报告为不正常,则运行状况检查将失败。 每个级别从它下面的级别继承所有失败条件。
| 级别 | 实例被认为停止的条件 |
|---|---|
| 1:OnServerDown | 如果除 AG 之外的资源出现故障,运行状况检查不会采取任何措施。 如果在 5 个间隔内未收到 AG 数据,或 5/3 * HealthCheckTimeout |
| 2:OnServerUnresponsive | 如果没有从 HealthCheckTimeout 的 sp_server_diagnostics 收到数据 |
| 3:OnCriticalServerError | (默认)如果系统组件报告错误 |
| 4:OnModerateServerError | 如果资源组件报告错误 |
| 5:OnAnyQualifiedFailureConditions | 如果查询处理组件报告错误 |
更新群集和 Always On 超时值
群集值
WSFC 配置中有四个值负责确定群集超时值:
- 同子网延迟
- 同一子网阈值
- 跨子网延迟
- 跨子网阈值
延迟值确定群集服务的检测信号之间的等待时间,阈值设置了在对象被群集声明为不活动之前不能从目标节点或资源接收确认的检测信号次数。 如果同一子网中的节点之间没有超过 SameSubnetDelay \* SameSubnetThreshold 毫秒的成功检测信号,则该节点被确定为不活动。 这同样适用于使用跨子网值的跨子网通信。
要列出当前所有群集值,请在目标群集的任何节点上打开提升的 PowerShell 终端。 运行以下命令:
Get-Cluster | fl *
要更新其中任意值,请在提升的 PowerShell 终端中运行以下命令:
(Get-Cluster).<ValueName> = <NewValue>
当增加延迟 * 阈值产品以使群集超时更加包容时,在增加阈值之前首先增加延迟值会更有效。 通过增加延迟,每次检测信号之间的时间增加。 检测信号之间的时间越多,可以将更多的时间用于解决自身的临时网络问题,并减少相对于在同一时间段内发送更多检测信号的网络拥塞。
租用超时
租用机制由 WSFC 群集中特定于每个 AG 的单个值来控制。 租用超时可能会导致以下错误:
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
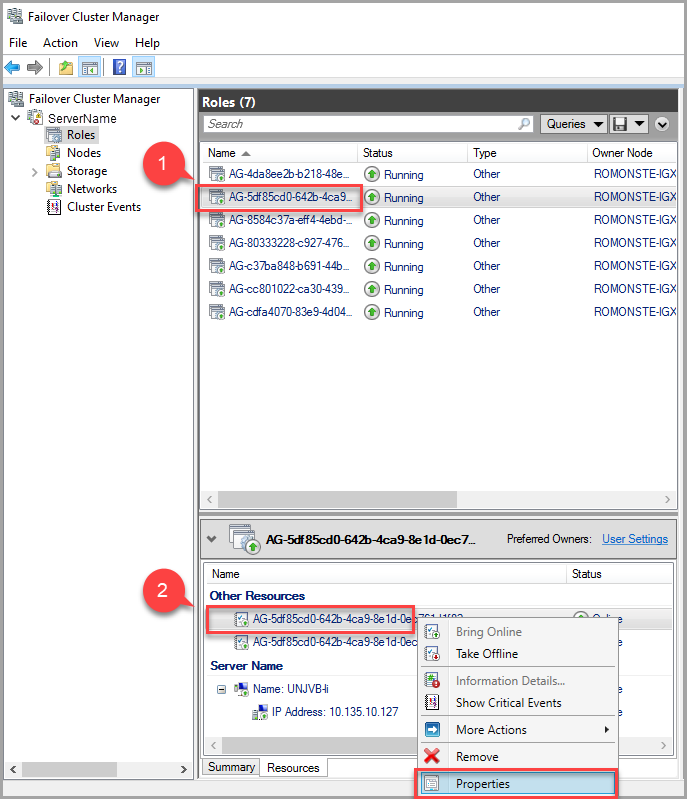
若要修改租用超时值,请使用故障转移群集管理器执行以下步骤:
在“角色”选项卡中,找到目标 AG 角色。 选择目标 AG 角色。
右键单击窗口底部的 AG 资源,然后选择“属性” 。
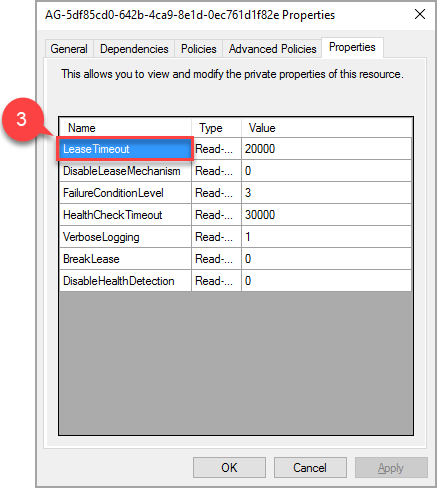
在弹出窗口中,导航到“属性”选项卡,即可查看一个特定于此 AG 的值列表。 选择 LeaseTimeout 值以更改它。
根据 AG 的配置,可能会为侦听器、共享磁盘、文件共享等提供额外资源,这些资源不需要任何其他配置。
注意
属性“LeaseTimeout”的新值将在资源脱机并再次联机时生效。
运行状况检查值
两个值控制 AlwaysOn 运行状况检查:FailureConditionLevel 和 HealthCheckTimeout。 FailureConditionLevel 指示由 sp_server_diagnostics 报告的特定故障条件的容差级别,HealthCheckTimeout 配置资源 DLL 可以在没有从 sp_server_diagnostics 接收更新的情况下运行的时间。
sp_server_diagnostics 的更新间隔始终为 HealthCheckTimeout/3。
要配置故障转移条件级别,请使用 FAILURE_CONDITION_LEVEL = <n> 或 CREATEALTER 语句的 AVAILABILITY GROUP 选项,其中 <n> 是 1 到 5 之间的整数。 以下命令将 AG 'AG1' 的故障条件级别设置为 1:
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
要配置运行状况检查超时,请使用 HEALTH_CHECK_TIMEOUT 或 CREATEALTER 语句的 AVAILABILITY GROUP 选项。 以下命令将 AG AG1 的运行状况检查超时设置为 60000 毫秒:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
超时指南摘要
建议不要将任何超时值降低到默认值以下。
租用时间间隔 (½ * LeaseTimeout) 必须短于 SameSubnetThreshold * SameSubnetDelay
SameSubnetThreshold = CrossSubnetThreshold <
同子网延迟 <= 跨子网延迟
| 超时设置 | 目的 | 出现在 | 使用 | IsAlive 和 LooksAlive | 原因 | 业务成效 |
|---|---|---|---|---|---|---|
| 租用超时 默认值:20000 |
防止脑裂 | 主站点到群集 (HADR) |
Windows 事件对象 | 在两者中使用 | OS 无响应、虚拟内存不足、工作集分页、生成转储、限定 CPU、WSFC 故障(失去仲裁) | AG 资源脱机-联机、故障转移 |
| 会话超时 默认值:10000 |
就主副本和辅助副本之间的通信问题进行通知 | 辅助副本到主副本 (HADR) |
TCP 套接字(通过 DBM 终结点发出的消息) | 二者都不使用 | 网络通信, 辅助副本的问题 - 故障、OS 无响应、资源争用 |
辅助副本 - 已断开连接 |
| HealthCheck 超时 默认值:30000 |
指示尝试确定主副本的运行状况时超时 | 群集到辅助副本 (FCI 和 HADR) |
T-SQL sp_server_diagnostics | 在两者中使用 | 满足故障条件、OS 无响应、虚拟内存不足、工作集微调、生成转储、WSFC(失去仲裁)、计划程序问题(死锁计划程序) | AG 资源脱机-联机或故障转移、FCI 重启/故障转移 |