适用于:![]() SQL Server 2017 (14.x) 及更高版本
SQL Server 2017 (14.x) 及更高版本
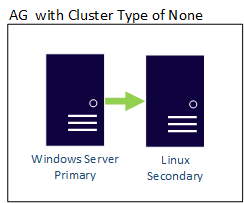
本文介绍后述操作的步骤:创建“Always On 可用性组 (AG)”,且一个副本在 Windows 服务器上,另一个副本在 Linux 服务器上。
重要
SQL Server 跨平台可用性组(包括具有完整高可用性和灾难恢复支持的异类副本)随 DH2i DxEnterprise 一起提供。 有关详细信息,请参阅具有混合操作系统的 SQL Server 可用性组。
观看以下视频,了解 DH2i 的跨平台可用性组。
此配置是跨平台的,因为副本在不同的操作系统上。 使用此配置从一个平台迁移到另一个平台或实现灾难恢复 (DR)。 此配置不支持高可用性。
在继续之前,应熟悉 Windows 和 Linux 上 SQL Server 实例的安装和配置。
场景
在此方案中,两台服务器使用不同的操作系统。 名为 WinSQLInstance 的 Windows Server 2022 承载主副本。 名为 LinuxSQLInstance 的 Linux 服务器承载次要副本。
配置 AG
创建 AG 的步骤与为“读取缩放”工作负载创建 AG 的步骤相同。 AG 群集类型是 NONE,因为没有群集管理器。
对于本文中的脚本,尖括号 < 和 > 用于标识需要根据您的环境替换的值。 脚本本身并不需要使用尖括号。
在 Windows Server 2022 上安装 SQL Server 2022 (16.x),从 SQL Server 配置管理器启用 Always On 可用性组,并设置混合模式身份验证。
提示
如果要在 Azure 中验证此解决方案,请将两个服务器放在同一可用性集中,并确保它们在数据中心中相互独立。
启用可用性组
有关说明,请参阅 启用或禁用 AlwaysOn 可用性组功能。
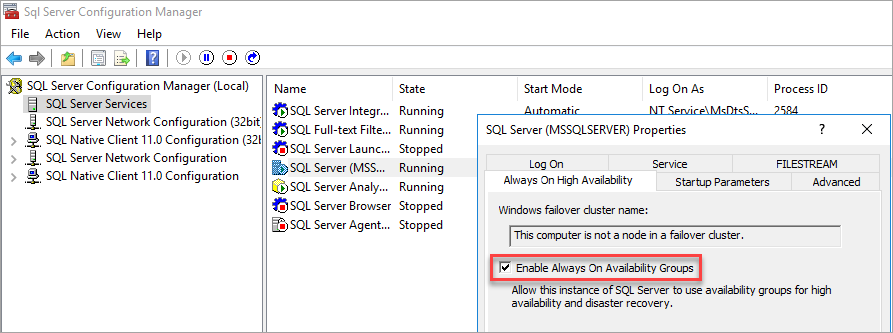
SQL Server 配置管理器指出计算机不是故障转移群集中的节点。
启用可用性组后,重新启动 SQL Server。
设置混合模式身份验证
如需相关说明,请参阅更改服务器身份验证模式。
在 Linux 上安装 SQL Server 2022 (16.x)。 有关说明,请参阅 Linux 上的 SQL Server 的安装指南。 启用
hadr和mssql-conf。要通过
mssql-conf从 shell 提示符启用hadr,请执行以下命令:sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1启用
hadr后,重启 SQL Server 实例:sudo systemctl restart mssql-server.service同时在两台服务器上配置
hosts文件或向 DNS 注册服务器名称。同时在 Windows 和 Linux 上为 TCP 1433 和 5022 打开防火墙端口。
在主副本上,创建数据库登录名和密码。
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO注意
密码应遵循 SQL Server 默认密码策略。 默认情况下,密码必须为至少八个字符且包含以下四种字符中的三种:大写字母、小写字母、十进制数字、符号。 密码可最长为 128 个字符。 使用的密码应尽可能长,尽可能复杂。
在主副本上,创建主密钥和证书,然后使用私钥备份证书。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<private-key-password>' ); GO注意
密码应遵循 SQL Server 默认密码策略。 默认情况下,密码必须为至少八个字符且包含以下四种字符中的三种:大写字母、小写字母、十进制数字、符号。 密码可最长为 128 个字符。 使用的密码应尽可能长,尽可能复杂。
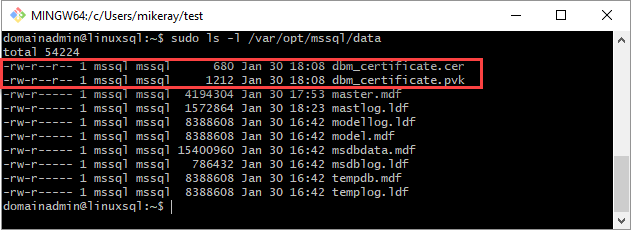
将证书和私钥复制到 Linux 服务器(次要副本)的
/var/opt/mssql/data处。 可以使用pscp将文件复制到 Linux 服务器。将私钥和证书的组和所有权设置为
mssql:mssql。以下脚本用于设置文件的用户组和所有者。
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cer下图中为证书和密钥正确设置了所有权和组。
在次要副本上,创建数据库登录名和密码并创建主密钥。
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO注意
密码应遵循 SQL Server 默认密码策略。 默认情况下,密码必须为至少八个字符且包含以下四种字符中的三种:大写字母、小写字母、十进制数字、符号。 密码可最长为 128 个字符。 使用的密码应尽可能长,尽可能复杂。
在次要副本上,恢复您复制到
/var/opt/mssql/data的证书。CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<private-key-password>' ); GO在上一示例中,将
<private-key-password>替换为在主副本上创建证书时使用的同一密码。在主副本上,创建终结点。
CREATE ENDPOINT [Hadr_endpoint] AS TCP ( LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022 ) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GO重要
必须为侦听器 TCP 端口打开防火墙。 在上面的脚本中,端口是 5022。 使用任何可用的 TCP 端口。
在次要副本上,创建终结点。 在次要副本上重复上述脚本以创建端点。
在主副本上,使用
CLUSTER_TYPE = NONE创建 AG。 示例脚本使用SEEDING_MODE = AUTOMATIC创建 AG。注意
当 SQL Server 的 Windows 实例对数据和日志文件使用不同的路径时,SQL Server 的 Linux 实例的自动种子设定会失败,因为这些路径在次要副本上不存在。 若要对跨平台 AG 使用以下脚本,数据库要求数据和日志文件在 Windows 服务器上具有相同的路径。 或者,还可以更新脚本以设置
SEEDING_MODE = MANUAL,然后使用NORECOVERY备份和还原数据库,从而为数据库设定种子。此行为适用于 Azure 市场 映像。
有关自动种子设定的详细信息,请参阅自动种子设定 - Disk Layout。
在运行脚本之前,请更新你的 AG 的值。
将
<WinSQLInstance>替换为主副本 SQL Server 实例的服务器名称。将
<LinuxSQLInstance>替换为次要副本 SQL Server 实例的服务器名称。
若要创建 AG,请更新值并在主副本上运行脚本。
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); );有关详细信息,请参阅 CREATE AVAILABILITY GROUP。
在次要副本上,联接 AG。
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GO为 AG 创建数据库。 示例步骤使用名为
TestDB的数据库。 如果使用自动播种,请为数据和日志文件设置相同的路径。在运行脚本之前,请更新数据库的值。
将
TestDB替换为数据库的名称。将
<F:\Path>替换为数据库和日志文件的路径。 为数据库和日志文件使用相同的路径。
也可以使用默认路径。
若要创建数据库,请运行该脚本。
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY (NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON (NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GO完整备份数据库。
如果不使用自动播种,请在运行 Linux 的次要副本服务器上还原数据库。 使用备份和还原将 SQL Server 数据库从 Windows 迁移到 Linux。 在次要副本上还原数据库
WITH NORECOVERY。将数据库添加到 AG。 更新示例脚本。 将
TestDB替换为数据库的名称。 在主要副本上,运行 T-SQL 查询以将数据库添加到 AG。ALTER AG [ag1] ADD DATABASE TestDB; GO验证是否在次要副本上填充了数据库。

故障转移主副本
每个可用性组仅有一个主要副本。 主要副本允许读取和写入操作。 要更改哪个副本是主节点,可以进行故障转移。 在典型的可用性组中,群集管理器自动执行故障转移流程。 在群集类型为 NONE 的可用性组中,故障转移过程是手动进行的。
在群集类型为 NONE 的可用性组中,有两种对主要副本进行故障转移方法:
- 手动故障转移(无数据丢失)
- 强制手动故障转移(存在数据丢失的风险)
手动切换(无数据丢失)
主要副本可用时使用此方法,但你需要暂时或永久更改托管主要副本的实例。 为了避免潜在的数据丢失,在发出手动故障转移之前,确保目标次要副本已更新到最新状态。
手动故障转移(无数据丢失):
将当前的主要副本和目标次要副本设置为
SYNCHRONOUS_COMMIT。ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);若要确定活动事务已提交到主副本和至少一个同步的辅助副本,请运行以下查询:
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;当
synchronization_state_desc为SYNCHRONIZED时,会同步次要副本。将
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT更新为 1。以下脚本在名为
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT的可用性组上将ag1设置为 1。 运行以下脚本前,将ag1替换为可用性组的名称:ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);此设置可确保将每个活动事务提交到主要副本和至少一个同步次要副本。
注意
此设置并非特定于故障转移,应该根据环境的具体要求进行设置。
将主要副本和不参与故障转移的次要副本设置为脱机,以便为角色更改做好准备:
ALTER AVAILABILITY GROUP [AGRScale] OFFLINE将目标次要副本升级为主要副本。
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;将旧的主要和其他次要副本的角色更新为
SECONDARY,在托管旧的主要副本的 SQL Server 实例上运行以下命令:ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);注意
若要删除可用性组,请使用删除可用性组。 对于使用群集类型为 NONE 或 EXTERNAL 创建的可用性组,请对可用性组的所有副本执行该命令。
恢复数据移动,为托管主要副本的 SQL Server 实例上的可用性组中的每个数据库运行以下命令:
ALTER DATABASE [db1] SET HADR RESUME重新创建出于读取缩放目的创建且不受群集管理器管理的所有侦听器。 如果原监听器指向旧主节点,请删除它,然后重新创建,使其指向新的主节点。
强制手动故障转移(数据可能会丢失)
如果主要副本不可用且无法立即恢复,则需要强制故障转移到次要副本,这将导致数据丢失。 但是,如果原始主要副本在故障转移后恢复,它将重新担任主要角色。 若要避免每个副本节点处于不同的状态,在执行导致数据丢失的强制故障转移后,请从可用性组中删除原始主节点。 原始主副本恢复联机后,将该可用性组从主副本中完全移除。
若要强制执行从主要副本 N1 到次要副本 N2 的手动故障转移(存在数据丢失),请执行以下步骤:
在次要副本 (N2) 上,启动强制故障转移:
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;在新的主要副本 (N2) 上,删除原始主要副本 (N1):
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';验证所有的应用程序流量均指向监听器和/或新的主副本。
如果主副本 (N1) 恢复联机状态,则应立即在主副本 (N1) 上将可用性组 AGRScale 脱机。
ALTER AVAILABILITY GROUP [AGRScale] OFFLINE如果存在数据或未同步的更改,则通过备份或其他可满足业务需求的数据复制选项来保存这些数据。
接下来,从原始主副本 (N1) 中删除可用性组:
DROP AVAILABILITY GROUP [AGRScale];删除原始主副本 (N1) 上的可用性组数据库:
USE [master] GO DROP DATABASE [AGDBRScale] GO(可选)如果需要,现可将 N1 作为新的次要副本添加回可用性组 AGRScale 中。
本文回顾了如何创建跨平台 AG 以支持迁移或扩展读取负载的步骤。 它可用于手动灾难恢复。 还介绍了如何对 AG 进行故障转移。 跨平台 AG 使用群集类型 NONE,不支持高可用性。