适用于:![]() Linux 上的 SQL Server
Linux 上的 SQL Server
本文档介绍如何使用 Red Hat Enterprise Linux 在共享磁盘故障转移群集上为 SQL Server 执行以下任务。
- 手动故障转移群集
- 监视故障转移群集 SQL Server 服务
- 添加群集节点
- 删除群集节点
- 更改 SQL Server 资源监视频率
体系结构说明
集群层基于在 Pacemaker 的基础上构建的 Red Hat Enterprise Linux (RHEL) HA 加载项。 Corosync 和 Pacemaker 协调群集通信和资源管理。 SQL Server 实例在一个节点或另一个节点上处于活动状态。
下图显示了 SQL Server 的 Linux 群集中的组件。
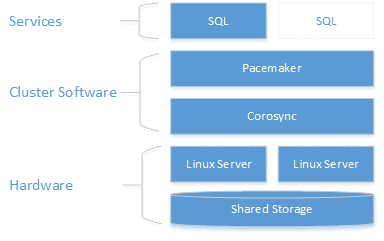
有关群集配置、资源代理选项和管理的详细信息,请访问 RHEL 参考文档。
手动故障转移群集
resource move 命令创建一个约束,用于强制资源在目标节点上启动。 执行 move 命令后,执行资源 clear 将移除该约束,因此可以再次移动资源或自动故障转移资源。
sudo pcs resource move <sqlResourceName> <targetNodeName>
sudo pcs resource clear <sqlResourceName>
以下示例将 mssqlha 资源移到名为 sqlfcivm2 的节点中,然后删除该约束,以便稍后可以将资源移到其他节点。
sudo pcs resource move mssqlha sqlfcivm2
sudo pcs resource clear mssqlha
监视故障转移群集 SQL Server 服务
查看当前群集状态:
sudo pcs status
查看群集和资源的实时状态:
sudo crm_mon
在 /var/log/cluster/corosync.log 查看资源代理日志
向群集添加节点
检查每个节点的 IP 地址。 以下脚本显示当前节点的 IP 地址。
ip addr show为每个节点提供长度不超过 15 个字符的唯一名称。 默认情况下,在 Red Hat Linux 中,计算机名为
localhost.localdomain。 此默认名称可能不是唯一的,并且过长。 将新节点设为计算机名称。 通过将计算机名添加到/etc/hosts来设置该名称。 以下脚本可使用/etc/hosts编辑vi。sudo vi /etc/hosts以下示例展示了
/etc/hosts,其中包含了三个名为sqlfcivm1、sqlfcivm2和sqlfcivm3的节点的新增项。127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 fcivm1 10.128.16.77 fcivm2 10.128.14.26 fcivm3此文件在每个节点上应相同。
在新节点上停止 SQL Server 服务。
按照说明将数据库文件目录装载到共享位置:
从 NFS 服务器安装
nfs-utils:sudo yum -y install nfs-utils在客户端和 NFS 服务器上打开防火墙:
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reload编辑
/etc/fstab文件,将装载命令包括在内:<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intr运行
mount -a使更改生效。在新节点上,创建一个文件来存储用于登录 Pacemaker 的 SQL Server 用户名和密码。 以下命令创建并填充此文件:
sudo touch /var/opt/mssql/passwd sudo echo "<loginName>" >> /var/opt/mssql/secrets/passwd sudo echo "<password>" >> /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/passwd sudo chmod 600 /var/opt/mssql/passwd注意
密码应遵循 SQL Server 默认密码策略。 默认情况下,密码必须为至少八个字符且包含以下四种字符中的三种:大写字母、小写字母、十进制数字、符号。 密码可最长为 128 个字符。 使用的密码应尽可能长,尽可能复杂。
在新节点上,打开 Pacemaker 防火墙端口。 若要使用
firewalld打开这些端口,请运行以下命令:sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reload如果使用的是没有内置高可用性配置的其他防火墙,则需要打开以下端口,Pacemaker 才能与群集中的其他节点通信:
- TCP:端口 2224、3121、21064
- UDP:端口 5405
在新节点上安装 Pacemaker 包。
sudo yum install pacemaker pcs fence-agents-all resource-agents为安装 Pacemaker 和 Corosync 包时创建的默认用户设置密码。 使用与现有节点相同的密码。
sudo passwd hacluster启用并启动
pcsd服务和 Pacemaker。 这允许新节点在重新启动后重新加入群集。 在新节点上运行以下命令。sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemaker为 SQL Server 安装 FCI 资源代理。 在新节点上运行以下命令。
sudo yum install mssql-server-ha在群集中的现有节点上,验证新节点并将其添加到群集中:
sudo pcs cluster auth <nodeName3> -u hacluster sudo pcs cluster node add <nodeName3>下面的示例将名为 vm3 的节点添加到群集。
sudo pcs cluster auth sudo pcs cluster start
从群集中删除节点
若要从群集中移除节点,请运行以下命令:
sudo pcs cluster node remove <nodeName>
更改 sqlservr 资源监视间隔的频率
sudo pcs resource op monitor interval=<interval>s <sqlResourceName>
以下示例将 mssql 资源的监视间隔时间设置为 2 秒:
sudo pcs resource op monitor interval=2s mssqlha
对适用于 SQL Server 的 Red Hat Enterprise Linux 共享磁盘群集进行故障排除
在对群集进行故障排除时,了解三个守护程序如何协同工作以管理群集资源会有所帮助。
| 守护程序 | 说明 |
|---|---|
| Corosync | 提供仲裁成员身份并在群集节点之间传递消息。 |
| 起搏器 | 位于 Corosync 之上,为资源提供状态机器。 |
| PCSD | 通过 pcs 工具管理 Pacemaker 和 Corosync。 |
需要运行 PCSD 才能使用 pcs 工具。
当前群集状态
sudo pcs status 返回有关每个节点的群集、仲裁、节点、资源和守护程序状态的基本信息。
正常的 pacemaker 仲裁输出的示例如下:
Cluster name: MyAppSQL
Last updated: Wed Oct 31 12:00:00 2016 Last change: Wed Oct 31 11:00:00 2016 by root via crm_resource on sqlvmnode1
Stack: corosync
Current DC: sqlvmnode1 (version 1.1.13-10.el7_2.4-44eb2dd) - partition with quorum
3 nodes and 1 resource configured
Online: [ sqlvmnode1 sqlvmnode2 sqlvmnode3 ]
Full list of resources:
mssqlha (ocf::sql:fci): Started sqlvmnode1
PCSD Status:
sqlvmnode1: Online
sqlvmnode2: Online
sqlvmnode3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
在此示例中,partition with quorum 表示节点的大多数仲裁处于联机状态。 如果群集丢失节点的大多数仲裁,pcs status 返回 partition WITHOUT quorum,并且所有资源都停止。
online: [sqlvmnode1 sqlvmnode2 sqlvmnode3] 返回当前参与此群集所有节点的名称。 如果有任何节点未参与,pcs status 返回 OFFLINE: [<nodename>]。
PCSD Status 显示每个节点的群集状态。
节点可能处于脱机状态的原因
节点处于脱机状态时检查以下各项。
防火墙
需要在所有节点上打开以下端口,才能使 Pacemaker 进行通信。
- **TCP:2224、3121、21064
正在运行的 Pacemaker 或 Corosync 服务
节点通信
节点名映射