适用于:![]() Linux 上的 SQL Server 2016 (13.x)
Linux 上的 SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
从 SQL Server 2017 及更高版本开始,如果在机器学习服务(数据库内)安装中包含 Python 选项,将提供 Python 集成功能。
注意
本文目前适用于 SQL Server 2016 (13.x)、SQL Server 2017 (14.x)、SQL Server 2019 (15.x) 以及仅适用于 Linux 的 SQL Server 2019 (15.x)。
若要为 SQL Server 开发和部署 Python 解决方案,请在开发工作站上安装 Microsoft 的 revoscalepy 和其他 Python 库。 revoscalepy 库也位于远程 SQL Server 实例上,负责协调两个系统之间的计算请求。
本文介绍如何配置 Python 开发工作站,以便能够与启用了机器学习和 Python 集成的远程 SQL Server 进行交互。 完成本文中的步骤后,你将拥有与 SQL Server 上相同的 Python 库。 你还将了解如何将计算从本地 Python 会话推送到 SQL Server 上的远程 Python 会话。
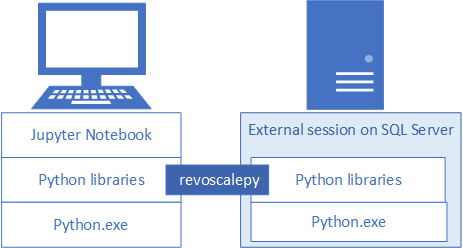
若要验证安装,你可以按本文所述使用内置的 Jupyter Notebook,也可以将库链接到你通常使用的 PyCharm 或任何其他 IDE。
提示
有关这些练习的视频演示,请参阅 Run R and Python remotely in SQL Server from Jupyter Notebooks(通过 Jupyter Notebook 在 SQL Server 中远程运行 R 和 Python)。
常用工具
无论是没接触过 SQL 的 Python 开发人员,还是没接触过 Python 和数据库内分析的 SQL 开发人员,都需要使用 Python 开发工具和 T-SQL 查询编辑器(例如 SQL Server Management Studio (SSMS))来行使数据库内分析的所有功能。
进行 Python 开发时,可以使用 Jupyter Notebook,它随附在 SQL Server 安装的 Anaconda 发行版中。 本文介绍如何启动 Jupyter Notebook,以便在本地以及在 SQL Server 上远程运行 Python 代码。
SSMS 需单独下载,它用于在 SQL Server 上创建和运行存储过程,其中包括包含 Python 代码的存储过程。 在 Jupyter Notebook 中编写的几乎所有 Python 代码都可以嵌入到存储过程中。 你可以逐步完成其他快速入门,以便了解 SSMS 和嵌入式 Python。
1 - 安装 Python 包
本地工作站必须具有与 SQL Server 上相同的 Python 包版本(包括具有 Python 3.5.2 发行版的基本 Anaconda 4.2.0),以及特定于 Microsoft 的包。
安装脚本会向 Python 客户端添加三个特定于 Microsoft 的库。 该脚本安装:
- revoscalepy 用于定义数据源对象和计算上下文。
- 可提供机器学习算法的 microsoftml。
- azureml 适用于与独立服务器上下文相关联的操作化任务,并且可能在数据库内分析中用途有限。
下载安装脚本。 在以下适当的 GitHub 页上,选择“下载原始文件”。
Install-PyForMLS.ps1 安装 Microsoft Python 包的版本 9.2.1。 此版本对应于默认 SQL Server 实例。
Install-PyForMLS.ps1 安装 Microsoft Python 包的版本 9.3。
使用提升的管理员权限打开 PowerShell 窗口(右键单击“以管理员身份运行”)。
转到下载安装程序时所在的文件夹并运行脚本。 添加
-InstallFolder命令行参数以指定库的文件夹位置。 例如:cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
如果省略安装文件夹,则默认值为 %ProgramFiles%\Microsoft\PyForMLS。
安装需要一些时间才能完成。 可在 PowerShell 窗口中监视进度。 安装完成后,将获得一整套包。
提示
有关在 Windows 上运行 Python 程序的常规用途信息,建议参考 Python for Windows 常见问题解答。
2 - 查找可执行文件
还是在 PowerShell 中,列出安装文件夹的内容,确认已安装 Python.exe、脚本和其他包。
输入
cd \以进入根驱动器,然后输入在上一步中为-InstallFolder指定的路径。 如果在安装过程中省略了此参数,则默认值为cd %ProgramFiles%\Microsoft\PyForMLS。输入
dir *.exe以列出可执行文件。 应该会显示“python.exe”、“pythonw.exe”和“uninstall-anaconda.exe”。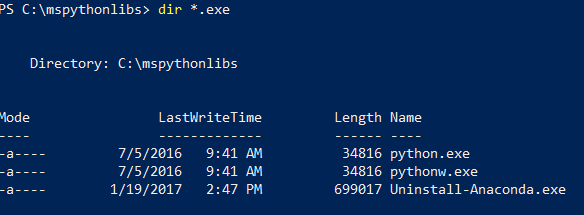
在具有多个 Python 版本的系统上,如果要加载 revoscalepy 和其他 Microsoft 包,请务必使用这个特定的 Python.exe。
注意
该安装脚本不会修改计算机上的 PATH 环境变量,这意味着系统不会将刚安装的新 python 解释器和模块自动提供给你可能拥有的其他工具。 有关将 Python 解释器和库链接到工具的帮助,请参阅安装 IDE。
3 - 打开 Jupyter Notebook
Anaconda 包含 Jupyter Notebook。 下一步是创建笔记本,并运行包含刚安装的库的 Python 代码。
在 PowerShell 提示符下,仍然是在
%ProgramFiles%\Microsoft\PyForMLS目录中,打开“Scripts”文件夹中的 Jupyter Notebook:.\Scripts\jupyter-notebook应该会在默认浏览器中 (
https://localhost:8889/tree) 打开一个笔记本。另一种启动方法是双击“jupyter-notebook.exe”。
选择“新建”,然后选择“Python 3”。
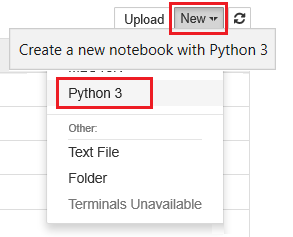
输入
import revoscalepy并运行该命令,以加载其中一个特定于 Microsoft 的库。输入并运行
print(revoscalepy.__version__)以返回版本信息。 你应该会看到 9.2.1 或 9.3.0。 可以在服务器上使用其中任一版本的 revoscalepy。输入一系列更复杂的语句。 此示例使用 rx_summary 针对某个本地数据集生成摘要统计信息。 其他函数用于获取示例数据的位置,以及为本地 .xdf 文件创建数据源对象。
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
下面的屏幕截图显示了输入和部分输出(为简洁起见对输出进行了剪裁)。

4 - 获取 SQL 权限
若要连接到 SQL Server 实例以运行脚本和上传数据,必须在数据库服务器上具有有效的登录名。 可以使用 SQL 登录凭据或集成 Windows 身份验证信息。 我们通常建议你使用 Windows 集成身份验证,但在某些情况下使用 SQL 登录更为简单,尤其是当脚本包含到外部数据的连接字符串时。
用于运行代码的帐户至少必须具有从正在使用的数据库进行读取的权限,以及具有特殊权限 EXECUTE ANY EXTERNAL SCRIPT。 大多数开发人员还需要有创建存储过程的权限,以及将数据写入包含训练数据或评分数据的表中的权限。
让数据库管理员在使用 Python 的数据库中为你的帐户配置以下权限:
- EXECUTE ANY EXTERNAL SCRIPT,以便在服务器上运行 Python。
- db_datareader 特权,以便运行用于训练模型的查询。
- db_datawriter,以便写入训练数据或评分数据。
- db_owner,以便创建存储过程、表和函数等对象。 你还需要使用 db_owner 来创建示例数据库和测试数据库。
如果你的代码需要使用默认情况下未随 SQL Server 安装的包,请与数据库管理员联系,将这些包随实例一起安装。 SQL Server 是一种受保护的环境,对包的安装位置有一些限制。 即使有相应权限,也不建议将包临时安装为代码的一部分。 此外,在服务器库中安装新包之前,请务必仔细考虑安全问题。
5 - 创建测试数据
如果有权在远程服务器上创建数据库,则可以运行以下代码来创建用于本文其余步骤的 Iris 演示数据库。
5-1 - 远程创建 irissql 数据库
from mssql_python import connect
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
conn = connect(connection_string.format("master"))
conn.setautocommit(True)
conn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
conn.cursor().execute("CREATE DATABASE " + new_db_name)
conn.close()
print("Database created")
5-2 - 从 SkLearn 导入 Iris 示例
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5-3 - 使用 Revoscalepy API 创建表并加载 Iris 数据
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with mssql-python
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6 - 测试远程连接
在尝试执行此步骤之前,请确保对 SQL Server 实例具有权限,并且具有到 Iris 示例数据库的连接字符串。 如果该数据库不存在,但你拥有足够的权限,则可以使用这些内联指令来创建数据库。
将连接字符串替换为有效值。 示例代码使用 "Server=localhost;Database=irissql;Trusted_Connection=Yes;",但你的代码应指定一个远程服务器(可能使用实例名称)和一个映射到数据库登录名的凭据选项。
6-1 定义函数
以下代码定义了一个将在后续步骤中发送到 SQL Server 的函数。 执行时,它使用远程服务器上的数据和库(revoscalepy、pandas、matplotlib)创建 iris 数据集的散点图。 它将 .png 的字节流返回给 Jupyter Notebook,以在浏览器中呈现。
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6-2 将函数发送到 SQL Server
在此示例中,创建远程计算上下文,然后使用 rx_exec 将函数的执行任务发送到 SQL Server。 rx_exec 函数非常有用,因为它接受计算上下文作为参数。 要远程执行的任何函数都必须具有一个计算上下文参数。 某些函数(例如 rx_lin_mod)直接支持此参数。 对于不执行的操作,可以使用 rx_exec 在远程计算上下文中传递代码。
在此示例中,无需将原始数据从 SQL Server 传输到 Jupyter Notebook。 所有计算都在 Iris 数据库内进行,并且仅将图像文件返回到客户端。
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
下面的屏幕截图显示了输入和散点图输出。

7 - 通过工具启动 Python
由于开发人员经常使用多个版本的 Python,因此安装程序不会将 Python 添加到你的 PATH 中。 若要使用安装程序安装的 Python 可执行文件和库,请将 IDE 链接到同时还提供 revoscalepy 和 microsoftml 的路径下的 Python.exe。
命令行
从 (或为 Python 客户端库安装指定的任何位置)运行 Python.exe 时,可以访问完整的 Anaconda 发行版以及 Microsoft Python 模块 revoscalepy 和 microsoftml。
- 转到
%ProgramFiles%\Microsoft\PyForMLS并执行 Python.exe。 - 打开交互式帮助:
help()。 - 在帮助提示符下键入模块名称:
help> revoscalepy。 帮助命令会返回名称、包内容、版本和文件位置。 - 在 help> 提示符下返回版本和包信息:。 多按几次 Enter 键退出帮助。
- 导入模块:
import revoscalepy。
Jupyter Notebook
本文使用内置的 Jupyter Notebook 来演示对 revoscalepy 的函数调用。 如果你不熟悉此工具,下面的屏幕截图将说明各个部分如何组合在一起,以及它们为什么都能“正常工作”。
父文件夹 %ProgramFiles%\Microsoft\PyForMLS 包含 Anaconda 和 Microsoft 包。 Jupyter Notebook 包含在 Anaconda 的 Scripts 文件夹下,Python 可执行文件会自动注册到 Jupyter Notebook。 可以将在 site-packages 下找到的包导入到笔记本中,其中包括用于数据科学和机器学习的三个 Microsoft 包。
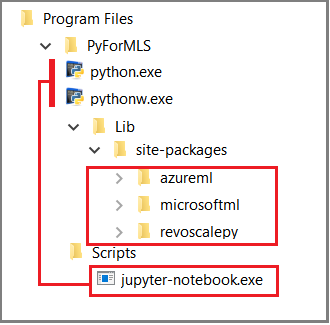
如果使用其他 IDE,则需要将 Python 可执行文件和函数库链接到工具。 以下部分介绍了各种常用工具。
Visual Studio
如果 Visual Studio 中有 Python ,可使用以下配置选项来创建一个包含 Microsoft Python 包的 Python 环境。
| 配置设置 | 值 |
|---|---|
| 前缀路径 | %ProgramFiles%\Microsoft\PyForMLS |
| 解释器路径 | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| 窗口化解释器 | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
有关配置 Python 环境的帮助,请参阅在 Visual Studio 中管理 Python 环境。
PyCharm
在 PyCharm 中,将解释器设置为安装的 Python 可执行文件。
在新项目的“设置”中,选择“添加本地”。
输入
%ProgramFiles%\Microsoft\PyForMLS\。
现在可以导入 revoscalepy、microsoftml 或 azureml 模块。 还可以选择“工具”“Python 控制台”来打开交互式窗口 。