本指南介绍如何识别和解决在具有特定工作负荷的高并发系统上运行 SQL Server 应用程序时观察到的闩锁争用问题。
随着服务器上 CPU 内核数的不断增加,并发性也相应增加,这可能会在必须在数据库引擎内以串行方式访问的数据结构中引入争用点。 对于高吞吐量/高并发事务处理 (OLTP) 工作负荷,尤其如此。 可以使用多种工具和方法来应对这些挑战,也可以在设计应用程序时,采用可能有助于完全避免这些挑战的做法。 本文将讨论数据结构中一种特殊类型的争用,此类争用使用旋转锁串行化对这些数据结构的访问。
注意
此内容由 Microsoft SQL Server 客户顾问团队 (SQLCAT) 根据其识别和解决页闩锁争用相关问题的过程编写而成,这些问题发生在高并发系统上的 SQL Server 应用程序中。 本文记载的建议和最佳做法基于实际 OLTP 系统开发和部署过程中的实际经验。
什么是 SQL Server 闩锁争用?
闩锁是 SQL Server 引擎使用的轻量级同步基元,可确保内存中结构(包括索引、数据页)和内部结构(例如 B 树中的非叶页)的一致性。 SQL Server 使用缓冲区闩锁来保护缓冲池中的页,使用 I/O 闩锁来保护尚未载入缓冲池的页。 每当在 SQL Server 缓冲池的页中写入或读取数据时,工作线程都必须先获取该页的缓冲区闩锁。 有多种类型的缓冲区闩锁可用于访问缓冲池中的页,包括独占闩锁 (PAGELATCH_EX) 和共享闩锁 (PAGELATCH_SH)。 如果 SQL Server 尝试访问缓冲池中尚不存在的页,系统会发送一个异步 I/O,将该页加载到缓冲池中。 如果 SQL Server 需要等待 I/O 子系统响应,它会根据请求类型等待独占 (PAGEIOLATCH_EX) 或共享 (PAGEIOLATCH_SH) I/O 闩锁;这样做是为了防止另一个工作线程使用不兼容的闩锁将同一页加载到缓冲池中。 闩锁还用于保护对缓冲池页以外的内部内存结构的访问;这些闩锁称为非缓冲区闩锁。
页闩锁争用是多 CPU 系统上最常见的情况,因此,本文将着重介绍这些内容。
当多个线程同时尝试获取同一内存中结构的不兼容闩锁时,就会发生闩锁争用。 闩锁是一种内部控制机制,因此 SQL 引擎会自动确定何时使用它。 因为闩锁的行为是确定性的,所以应用程序决策(包括架构设计)可以影响此行为。 本文旨在提供以下信息:
- 有关 SQL Server 如何使用闩锁的背景信息。
- 用于调查闩锁争用的工具。
- 如何确定观察到的争用量是否有问题。
我们将讨论一些常见情况,以及如何以最佳方式处理它们,以缓解争用。
SQL Server 如何使用闩锁?
SQL Server 中一个页的大小为 8 KB,可以存储多行。 为了提高并发性和性能,缓冲区闩锁仅在页上的物理操作期间保留,这与在逻辑事务期间保留的锁不同。
闩锁是 SQL 引擎的内部机制,用于提供内存一致性,而锁则是 SQL Server 用来提供逻辑事务一致性的。 下表将闩锁与锁进行了比较:
| 结构 | 目的 | 控制者 | 性能开销 | 公开者 |
|---|---|---|---|---|
| 闩锁 | 保证内存中结构的一致性。 | 仅 SQL Server 引擎。 | 性能开销较低。 为了最大程度地提高并发性和性能,闩锁仅在内存中结构的物理操作期间保留,这与在逻辑事务期间保留的锁不同。 | sys.dm_os_wait_stats (Transact-SQL) - 提供有关 PAGELATCH、PAGEIOLATCH 和 LATCH 等待类型(LATCH_EX、LATCH_SH 用于对所有非缓冲区闩锁等待进行分组)的信息。 sys.dm_os_latch_stats (Transact-SQL) - 提供有关非缓冲区闩锁等待的详细信息。 sys.dm_db_index_operational_stats (Transact-SQL) - 此 DMV 提供每个索引的聚合等待,这对于排查与闩锁相关的性能问题很有用。 |
| 锁定 | 保证事务的一致性。 | 可由用户控制。 | 与闩锁相比,性能开销较高,因为锁必须在事务期间保留。 | sys.dm_tran_locks (Transact-SQL)。 sys.dm_exec_sessions (Transact-SQL)。 |
SQL Server 闩锁模式和兼容性
某些闩锁争用应该是 SQL Server 引擎操作的正常部分。 高并发系统上出现多个兼容性不同的并发闩锁请求,这种现象是不可避免的。 SQL Server 通过以下方式实现闩锁兼容性:要求不兼容的闩锁请求在队列中等待,直到未完成的闩锁请求完成为止。
可在五种不同模式中的任一模式下获取闩锁,这与访问级别有关。 SQL Server 闩锁模式可以总结如下:
KP - 保留闩锁,确保无法破坏被引用的结构。 当线程要查看缓冲区结构时使用。 因为 KP 闩锁与除破坏 (DT) 闩锁以外的所有闩锁兼容,所以 KP 闩锁被认为是“轻量级”的,这意味着使用 KP 闩锁对性能的影响最小。 由于 KP 闩锁与 DT 闩锁不兼容,因此它会阻止任何其他线程破坏被引用的结构。 例如,KP 闩锁会阻止惰性写入器进程破坏其引用的结构。 有关如何将惰性写入器进程与 SQL Server 缓冲区页管理配合使用的详细信息,请参阅写入页。
SH - 读取引用的结构(例如读取数据页)所需的共享闩锁。 多个线程可同时访问共享闩锁下的一个资源以进行读取。
UP - 更新闩锁,与 SH(共享闩锁)和 KP 兼容,但与其他闩锁不兼容,因此它不允许 EX 闩锁写入被引用的结构。
EX - 独占闩锁,阻止其他线程写入或读取被引用的结构。 例如,可使用它修改页内容,以保护残缺页。
DT - 破坏闩锁,必须在破坏被引用结构的内容前获取。 例如,在将干净页添加到可供其他线程使用的空闲缓冲区列表之前,惰性写入器进程必须获取 DT 闩锁来释放该页。
闩锁模式具有不同级别的兼容性,例如,共享闩锁 (SH) 与更新 (UP) 或保留 (KP) 闩锁兼容,但与破坏闩锁 (DT) 不兼容。 只要闩锁兼容,就可以在同一结构上同时获取多个闩锁。 当线程尝试获取不兼容的模式中保留的闩锁时,系统会将其放入队列中,等待指示资源可用的信号。 SOS_Task 类型的旋转锁用于通过强制串行化队列访问来保护等待队列。 必须获取此旋转锁才能向队列添加项。 SOS_Task 旋转锁还会在系统释放不兼容的闩锁时,向队列中的线程发出信号,从而允许正在等待的线程获取兼容的闩锁并继续工作。 当系统释放闩锁请求时,将按先进先出 (FIFO) 的顺序处理等待队列。 闩锁遵循此 FIFO 原则,以确保公平并防止线程饥饿。
下表列出了闩锁模式兼容性(Y 表示兼容,N 表示不兼容):
| 闩锁模式 | KP | SH | UP | EX | DT |
|---|---|---|---|---|---|
| KP | Y | Y | Y | Y | N |
| SH | Y | Y | Y | N | N |
| UP | Y | Y | N | N | N |
| EX | Y | N | N | N | N |
| DT | N | N | N | N | N |
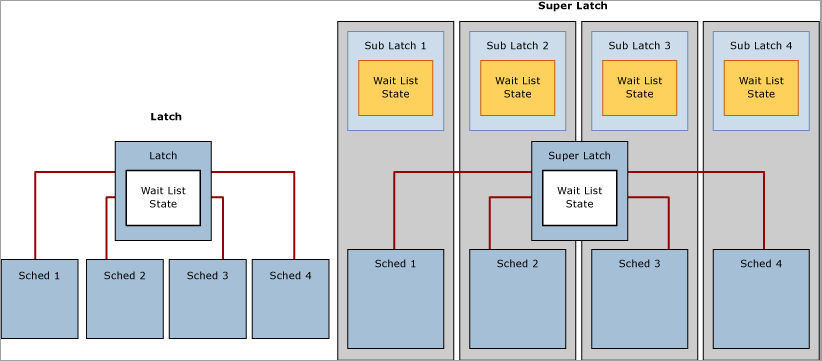
SQL Server 超级闩锁和子闩锁
随着基于 NUMA 的多插槽/多核系统的不断增加,SQL Server 2005 引入了超级闩锁,也称子闩锁,它仅在具有 32 个或更多逻辑处理器的系统上有效。 对于高并发 OLTP 工作负荷中的某些使用模式,超级闩锁可提高 SQL 引擎的效率;例如,当某些页具有繁重只读共享 (SH) 访问模式,但很少被写入时。 具有这种访问模式的页示例为 B 树(即索引)根页;SQL 引擎要求当 B 树的任何级别发生页拆分时,均在根页上保留一个共享闩锁。 在插入操作繁重的高并发 OLTP 工作负荷中,页拆分数量基本上会随吞吐量的增加而增加,这可能会降低性能。 当多个同时运行的工作线程需要 SH 闩锁时,超级闩锁可以提高访问共享页的性能。 为实现此目的,SQL Server 引擎会将此类页上的闩锁动态升级为超级闩锁。 超级闩锁将单个闩锁分区为一系列子闩锁结构,每个 CPU 内核每个分区一个子闩锁,这样一来,主闩锁就变成了代理重定向器,只读闩锁无需进行全局状态同步。 在此过程中,始终分配给特定 CPU 的工作线程只需获取分配给本地计划程序的共享 (SH) 子闩锁。
注意
文档在提到索引时一般使用 B 树这个术语。 在行存储索引中,数据库引擎实现了 B+ 树。 这不适用于列存储索引或内存优化表上的索引。 有关详细信息,请参阅 SQL Server 以及 Azure SQL 索引体系结构和设计指南。
与获取未分区的共享闩锁相比,获取兼容闩锁(例如共享超级闩锁)使用的资源更少,并且可以更好地缩放对热页的访问,因为去除全局状态同步要求后,只需访问本地 NUMA 内存,从而显著提高了性能。 相反,与获取 EX 常规闩锁相比,获取独占 (EX) 超级闩锁使用的资源更多,因为 SQL 必须向所有子闩锁发送信号。 当观察到超级闩锁使用繁重 EX 访问模式时,SQL 引擎可以在从缓冲池中删除页后,将超级闩锁降级。 下图描绘了普通闩锁和已分区的超级闩锁:
在性能监视器中,使用 SQL Server:Latches 对象和关联计数器来收集有关超级闩锁的信息,包括超级闩锁的数量、每秒超级闩锁升级数和每秒超级闩锁降级数。 有关 SQL Server:Latches 对象和关联计数器的详细信息,请参阅 SQL Server Latches 对象。
闩锁等待类型
累积等待信息由 SQL Server 跟踪,可使用动态管理视图 (DMW) sys.dm_os_wait_stats 进行访问。 SQL Server 使用由 sys.dm_os_wait_stats DMV 中的相应 wait_type 定义的三种闩锁等待类型:
缓冲区 (BUF) 闩锁:用于保证用户对象的索引页和数据页的一致性。 还可以使用它们来保护对 SQL Server 用于系统对象的数据页的访问。 例如,管理分配的页受缓冲区闩锁保护。 其中包括页可用空间 (PFS) 页、全局分配映射 (GAM) 页、共享全局分配映射 (SGAM) 页和索引分配映射 (IAM) 页。
sys.dm_os_wait_stats中缓冲区闩锁报告为 PAGELATCH_* 的wait_type。非缓冲区 (Non-BUF) 闩锁:用于保证除缓冲池页以外的任何内存中结构的一致性。 非缓冲区闩锁的任何等待事件都将以 LATCH_* 的
wait_type形式报告。IO 闩锁:缓冲区闩锁的一个子集。当受缓冲区闩锁保护的相同结构需要通过 I/O 操作加载到缓冲池时,IO 闩锁可以保证这些结构的一致性。 IO 闩锁可防止另一个线程使用不兼容的闩锁将同一页加载到缓冲池中。 与 PAGEIOLATCH_* 的
wait_type相关联。注意
如果看到大量的 PAGEIOLATCH 等待,则表明 SQL Server 正在等待 I/O 子系统。 尽管一定数量的 PAGEIOLATCH 等待是正常现象,但如果 PAGEIOLATCH 平均等待时间始终超过10 毫秒 (ms),则应调查 I/O 子系统承受压力的原因。
如果在检查 sys.dm_os_wait_stats DMV 时遇到非缓冲区闩锁,则必须检查 sys.dm_os_latch_stats,以获取非缓冲区闩锁的累积等待信息的详细分类。 所有缓冲区闩锁等待都归类为 BUFFER 闩锁类,其余类用于对非缓冲区闩锁进行分类。
SQL Server 闩锁争用的症状和原因
在繁忙的高并发系统上,由 SQL Server 中的闩锁和其他控制机制频繁访问和保护的结构上出现活跃争用是一种正常现象。 如果获取页闩锁时出现的争用和等待时间足以降低资源 (CPU) 利用率,进而造成吞吐量下降,则认为闩锁争用有问题。
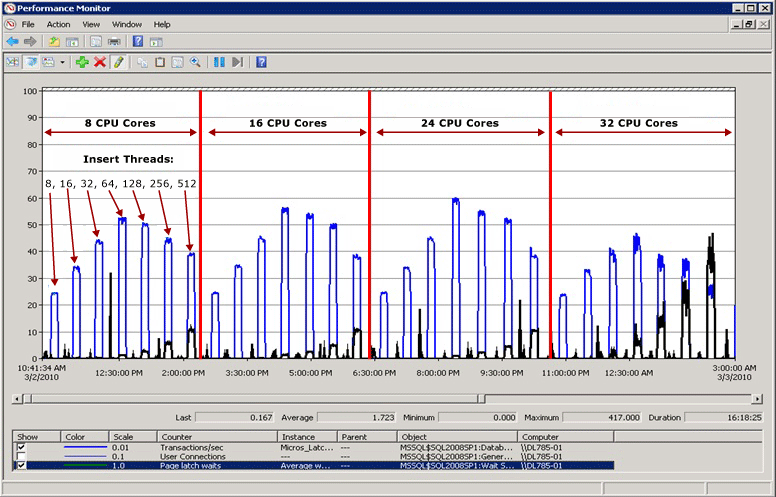
闩锁争用示例
在下图中,蓝线表示 SQL Server 中的吞吐量,以每秒事务数为单位;黑线表示页闩锁平均等待时间。 在本例中,例如在填充数据类型为 bigint 的 IDENTITY 列时,每个事务都对包含按顺序递增的前导值的聚集索引执行 INSERT 操作。 当 CPU 数量增加到 32 时,总体吞吐量明显降低,而页闩锁等待时间增加到了大约 48 毫秒(如黑线所示)。 吞吐量和页闩锁等待时间之间的这种反比关系是一种很容易诊断的常见情况。
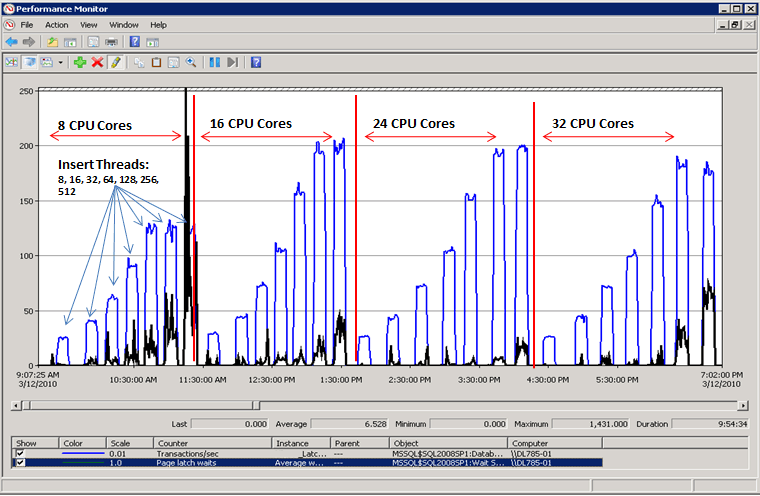
解决闩锁争用后的性能
如下图所示,页闩锁等待不再成为 SQL Server 的瓶颈,吞吐量提高了 300%(按每秒事务数衡量)。 这是通过本文后面介绍的“使用包含计算列的哈希分区”方法实现的。 此性能改进针对的是具有大量内核和高级别并发的系统。
影响闩锁争用的因素
导致 OLTP 环境性能不佳的闩锁争用通常是由与以下一个或多个因素相关的高并发引起的:
| 因子 | 详细信息 |
|---|---|
| SQL Server 使用的大量逻辑 CPU | 任何多核系统都可能出现闩锁争用。 在 SQLCAT 体验中,过多的闩锁争用会影响应用程序性能,使其超出可接受的水平,这种情况在具有 16 个以上 CPU 内核的系统上最常见,并且可能随着可用内核的增加而增加。 |
| 架构设计和访问模式 | B 树的深度、聚集索引和非聚集索引设计、每页行的大小和密度以及访问模式(读/写/删除活动)都是可能导致过多页闩锁争用的因素。 |
| 应用程序级别的高并发度 | 当应用程序层发出大量并发请求时,通常会出现过多页闩锁争用。 某些编程做法也有可能为特定页引入大量请求。 |
| SQL Server 数据库使用的逻辑文件的布局 | 逻辑文件布局可能会影响由分配结构(例如页可用空间 (PFS) 页、全局分配映射 (GAM) 页、共享全局分配映射 (SGAM) 页和索引分配映射 (IAM) 页)引起的页闩锁争用的级别。 有关详细信息,请参阅 TempDB 监视和故障排除:分配瓶颈。 |
| I/O 子系统性能 | 大量 PAGEIOLATCH 等待表示 SQL Server 正在等待 I/O 子系统。 |
诊断 SQL Server 闩锁争用
本部分提供的信息用于诊断 SQL Server 闩锁争用,以确定它是否会给你的环境带来问题。
诊断闩锁争用的工具和方法
用于诊断闩锁争用的主要工具包括:
性能监视器,可监视 SQL Server 中的 CPU 利用率和等待时间,并确定 CPU 利用率和闩锁等待时间之间是否存在关系。
SQL Server DMV,可用于确定导致问题的闩锁的特定类型和受影响的资源。
在某些情况下,必须使用 Windows 调试工具来获取和分析 SQL Server 进程的内存转储。
注意
通常,仅在排查非缓冲区闩锁争用问题时,才需要使用此级别的高级故障排除。 你可能需要使用 Microsoft 产品支持服务来进行此类高级故障排除。
诊断闩锁争用的技术流程可以归纳为以下步骤:
确定存在可能与闩锁有关的争用。
使用附录:SQL Server 闩锁争用脚本中提供的 DMV 视图来确定闩锁类型和受影响的资源。
使用处理不同表模式的闩锁争用所述的方法之一来缓解争用。
闩锁争用指标
如前所述,仅当获取页闩锁时出现的争用和等待时间在 CPU 资源可用的情况下导致吞吐量无法提高时,才认为闩锁争用有问题。 确定可接受的争用量需要采用一种综合方法,该方法应考虑性能和吞吐量要求以及可用的 I/O 和 CPU 资源。 本部分将引导你确定闩锁争用对工作负荷的影响,如下所示:
测量代表性测试期间的总等待时间。
对其进行排序。
确定与闩锁相关的等待时间所占的比例。
累积等待信息可从 sys.dm_os_wait_stats DMV 获得。 闩锁争用最常见的类型是缓冲区闩锁争用,具体表现为 wait_type 为 PAGELATCH_* 的闩锁的等待时间增加。 非缓冲区闩锁分组在 LATCH* 等待类型下。 如下图所示,应首先使用 sys.dm_os_wait_stats DMV 来查看系统累积等待时间,以确定缓冲区闩锁或非缓冲区闩锁导致的总等待时间所占的百分比。 如果遇到非缓冲区闩锁,则还必须检查 sys.dm_os_latch_stats DMV。
下图描述了 sys.dm_os_wait_stats 和 sys.dm_os_latch_stats DMV 返回的信息之间的关系。

有关 sys.dm_os_wait_stats DMV 的详细信息,请参阅 SQL Server 帮助中的 sys.dm_os_wait_stats (Transact-SQL)。
有关 sys.dm_os_latch_stats DMV 的详细信息,请参阅 SQL Server 帮助中的 sys.dm_os_latch_stats (Transact-SQL)。
闩锁等待时间的以下度量值表明过多的闩锁争用会影响应用程序性能:
平均页闩锁等待时间随着吞吐量的增加而持续增加:如果页闩锁平均等待时间随着吞吐量的增加而持续增加,并且缓冲区闩锁平均等待时间也增加到超出预期的磁盘响应时间,则应使用
sys.dm_os_waiting_tasksDMV 检查当前的等待任务。 单独分析平均值可能会产生误导,因此,尽可能实时查看系统以了解工作负荷特征非常重要。 具体来说,应检查任何页上是否有针对 PAGELATCH_EX 和/或 PAGELATCH_SH 请求的大量等待。 请按照以下步骤诊断随吞吐量增加而增加的页闩锁平均等待时间:- 使用示例脚本查询按会话 ID 排序的 sys.dm_os_waiting_tasks 或计算一段时间内的等待数,以查看当前的等待任务并测量闩锁平均等待时间。
- 使用示例脚本查询缓冲区描述符以确定导致闩锁争用的对象,以确定发生争用的索引和基础表。
- 使用性能监视器计数器 MSSQL%InstanceName%\Wait Statistics\Page Latch Waits\Average Wait Time 或通过运行
sys.dm_os_wait_statsDMV 来测量页闩锁平均等待时间。
注意
若要计算特定等待类型(由
sys.dm_os_wait_stats返回为 wt_:type)的平均等待时间,请将总等待时间(返回为wait_time_ms)除以等待任务数(返回为waiting_tasks_count)。峰值负载时按闩锁等待类型区分的总等待时间百分比:如果闩锁平均等待时间占总等待时间的百分比随着应用程序负载的增加而增加,则闩锁争用可能会影响性能,应进行调查。
使用 SQLServer:Wait Statistics Object 性能计数器来测量页闩锁等待和非页闩锁等待。 然后将这些性能计数器的值与 CPU、I/O、内存和网络吞吐量相关性能计数器的值进行比较。 例如,每秒事务数和每秒批处理请求数是两个绝佳的资源利用率度量值。
注意
sys.dm_os_wait_statsDMV 中不包括每种等待类型的相对等待时间,因为此 DMW 测量自上次启动 SQL Server 实例或使用 DBCC SQLPERF 重置累积等待统计信息以来的等待时间。 若要计算每种等待类型的相对等待时间,请对高峰负载之前和之后的sys.dm_os_wait_stats拍摄快照,然后计算差值。 示例脚本计算一段时间内的等待数可用于此目的。使用以下命令清除
sys.dm_os_wait_statsDMV(仅适用于非生产环境):dbcc SQLPERF ('sys.dm_os_wait_stats', 'CLEAR')可以运行类似的命令来清除
sys.dm_os_latch_statsDMV:dbcc SQLPERF ('sys.dm_os_latch_stats', 'CLEAR')当应用程序负载增加并且 SQL Server 可用的 CPU 数量增加时,吞吐量不仅不增加,反而在某些情况下会减少:这在闩锁争用示例中有说明。
应用程序工作负载增加时 CUP 使用率不增加:如果在应用程序吞吐量驱动的并发性增加时,系统上的 CPU 利用率没有增加,则表明 SQL Server 正在等待,这是闩锁争用的症状。
分析根本原因。 即使上述每个条件都成立,性能问题的根本原因仍有可能在其他地方。 实际上,在大多数情况下,CPU 利用率欠佳是由其他类型的等待引起的,例如锁阻塞、与 I/O 相关的等待或与网络相关的问题。 一般来说,在继续进行更深入的分析之前,最好先解决占总等待时间最大比例的资源等待。
分析当前的等待缓冲区闩锁
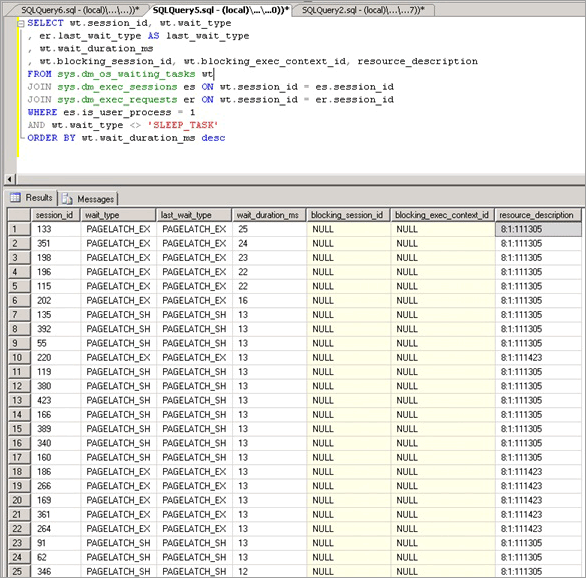
缓冲区闩锁争用表现为:wait_type 为 PAGELATCH_* 或 PAGEIOLATCH_* 的闩锁的等待时间增加,如 sys.dm_os_wait_stats DMV 中所示。 若要实时查看系统,请在系统上运行以下查询以加入 sys.dm_os_wait_stats、sys.dm_exec_sessions 和 sys.dm_exec_requests DMV。 结果可用于确定服务器上正在执行的会话的当前等待类型。
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc
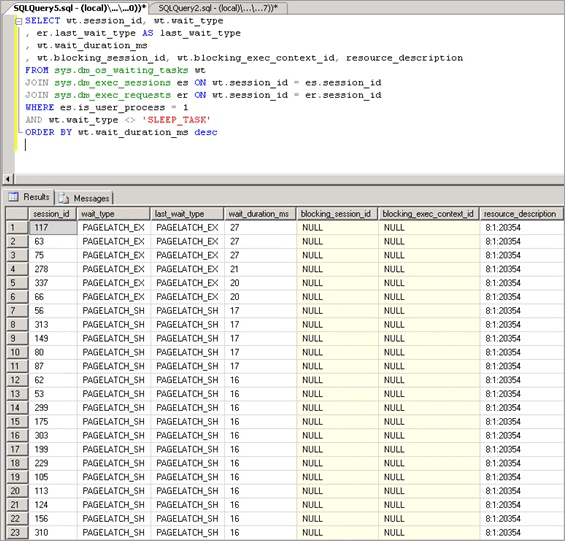
此查询公开的统计信息如下:
| 统计信息 | 说明 |
|---|---|
| Session_id | 与任务关联的会话的 ID。 |
| Wait_type | SQL Server 在引擎中记录的等待类型,正是它导致当前请求无法执行。 |
| Last_wait_type | 如果此请求先前已经阻塞,则此列返回上次等待的类型。 不可为 null。 |
| Wait_duration_ms | 自启动 SQL Server 实例或重置累积等待统计信息以来,等待此等待类型所用的总等待时间(以毫秒为单位)。 |
| Blocking_session_id | 正在阻塞请求的会话的 ID。 |
| Blocking_exec_context_id | 与任务关联的执行上下文的 ID。 |
| Resource_description | resource_description 列按以下格式列出正在等待的确切页面:<database_id>:<file_id>:<page_id> |
以下查询将返回所有非缓冲区闩锁的信息:
select * from sys.dm_os_latch_stats where latch_class <> 'BUFFER' order by wait_time_ms desc;

此查询公开的统计信息如下:
| 统计信息 | 说明 |
|---|---|
| latch_class | SQL Server 在引擎中记录的闩锁类型,正是它导致当前请求无法执行。 |
| waiting_requests_count | 自 SQL Server 重启后,此类中闩锁的等待数。 此计数器在闩锁等待启动时递增。 |
| wait_time_ms | 等待此闩锁类型所用的总等待时间(以毫秒为单位)。 |
| max_wait_time_ms | 任何请求等待此闩锁类型所用的最长时间(以毫秒为单位)。 |
注意
此 DMV 返回的值是自上次重启数据库引擎或重置 DMV 以来的累积值。 使用 sys.dm_os_sys_info 中的 sqlserver_start_time 列查找上次数据库引擎启动时间。 在运行了很长时间的系统上,这意味着某些统计信息(如 max_wait_time_ms)用处不大。 可以使用以下命令重置此 DMV 的等待统计信息:
DBCC SQLPERF ('sys.dm_os_latch_stats', CLEAR);
SQL Server 闩锁争用场景
我们观察到以下场景会导致过多的闩锁争用。
最后一页/尾页插入争用
OLTP 的常见做法是在标识或日期列上创建聚集索引。 这有助于保持良好的索引物理组织,从而极大地提高读取和写入索引的性能。 但是,这种架构设计可能会导致闩锁争用。 此问题最常见于包含小行的大型表,以及对包含按顺序递增的前导键列(如升序整数或日期时间键)的索引进行插入。 在此场景中,应用程序很少执行更新或删除操作,但存档操作除外。
在下面的示例中,线程 1 和线程 2 都希望插入一条记录,该记录将存储在第 299 页。 从逻辑锁定的角度来看,这没有任何问题,因为系统将使用行级锁,并且可以同时保留同一页上两条记录的独占锁。 但是,为了确保物理内存的完整性,一次只有一个线程能获取独占闩锁,因此,对该页的访问将被串行化,以防止丢失内存中的更新。 在本例中,线程 1 获取独占闩锁;线程 2 等待,这会在等待统计信息中为此资源注册 PAGELATCH_EX 等待。 这通过 wait_type DMV 中的 sys.dm_os_waiting_tasks 值显示。
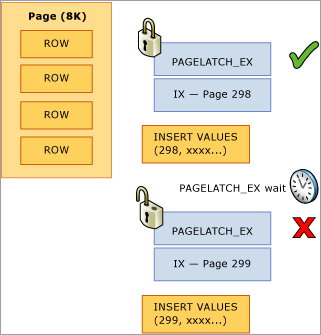
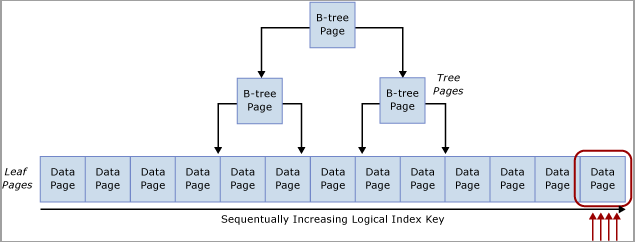
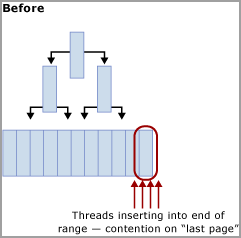
该争用通常称为“最后一页插入”争用,因为它发生在 B 树的最右侧,如下图所示:
此类闩锁争用可以解释如下。 向索引插入新行时,SQL Server 将使用以下算法执行修改:
遍历 B 树,找到正确的页来保存新记录。
使用 PAGELATCH_EX 锁住该页,防止其他线程对它进行修改,并在所有非叶页上获取共享闩锁 (PAGELATCH_SH)。
注意
在某些情况下,SQL 引擎还需要在 B 树非叶页上获取 EX 闩锁。 例如,进行页拆分时,需要以独占方式锁住 (PAGELATCH_EX) 任何将直接受到影响的页。
记录已修改该行的日志条目。
将该行添加到页并将页标记为脏。
解锁所有页。
如果表索引基于按顺序递增的键,则每个新插入都将进入 B 树末尾的同一页,直至该页变满。 在高并发情况下,这可能会导致 B 树的最右侧发生争用,并且可能发生在聚集索引和非聚集索引上。 受此类争用影响的表主要接受 INSERT,而有问题索引的页通常相对密集(例如,行大小约为 165 字节(包括行开销)等于约 49 行/页)。 在此插入密集型示例中,预计会发生 PAGELATCH_EX/PAGELATCH_SH 等待,这是典型的观察结果。 若要检查页闩锁等待与树页闩锁等待,请使用 sys.dm_db_index_operational_stats DMV。
下表总结了针对此类闩锁争用观察到的主要因素:
| 因子 | 典型观察结果 |
|---|---|
| SQL Server 使用的逻辑 CPU | 此类闩锁争用主要发生在具有 16 个以上 CPU 内核的系统上,最常发生在具有 32 个以上 CPU 内核的系统上。 |
| 架构设计和访问模式 | 使用按顺序递增的标识值作为事务数据表索引中的前导列。 索引的主键递增,并且插入率较高。 索引至少有一个按顺序递增的列值。 行大小通常较小,每页包含多行。 |
| 观察到的等待类型 | 许多线程争夺同一资源时,按等待持续时间排序的查询 sys.dm_os_waiting_tasks 返回的 sys.dm_os_waiting_tasks DMV 中出现与同一 resource_description 关联的独占 (EX) 或共享 (SH) 闩锁等待。 |
| 要考虑的设计因素 | 如果可以保证始终在 B 树上均匀分布插入,请考虑按非顺序索引缓解策略中所述更改索引列的顺序。 如果使用哈希分区缓解策略,则无法将分区用于任何其他目的,例如滑动窗口存档。 使用哈希分区缓解策略可能会导致应用程序使用的 SELECT 查询出现分区消除问题。 |
具有非聚集索引和随机插入的小型表(队列表)上的闩锁争用
当 SQL 表用作临时队列(例如,在异步消息传送系统中),通常会看到这种情况。
在此场景中,独占 (EX) 和共享 (SH) 闩锁争用可能会在以下情况下发生:
- 在高并发条件下进行插入、选择、更新或删除操作。
- 行大小相对较小(导致页密集)。
- 表中的行数相对较少,导致 B 树较浅,即索引深度为 2 或 3。
注意
在这种访问模式下,如果数据操作语言 (DML) 的频率和系统的并发性足够高,那么即使是深度较大的 B 树也会出现争用。 如果系统可使用 16 个或更多 CPU 内核,随着并发性的增加,闩锁争用的级别可能会明显增加。
即使在 B 树中进行随机访问,例如当非顺序列是聚集索引中的前导键时,也有可能发生闩锁争用。 以下屏幕截图来自遇到此类闩锁争用的系统。 在此示例中,行大小较小和 B 树相对较浅导致页密度变高,从而引起争用。 随着并发性的增加,即使在 B 树中进行随机插入,页上也会发生闩锁争用,因为 GUID 是索引中的前导列。
在下面的屏幕截图中,缓冲区数据页和页可用空间 (PFS) 页上均发生了等待。 有关 PFS 页闩锁争用的详细信息,请参阅 SQLSkills 上的以下第三方博客文章:建立基准:SSD 上的多个数据文件。 即使增加数据文件的数量,闩锁争用在缓冲区数据页上也很普遍。
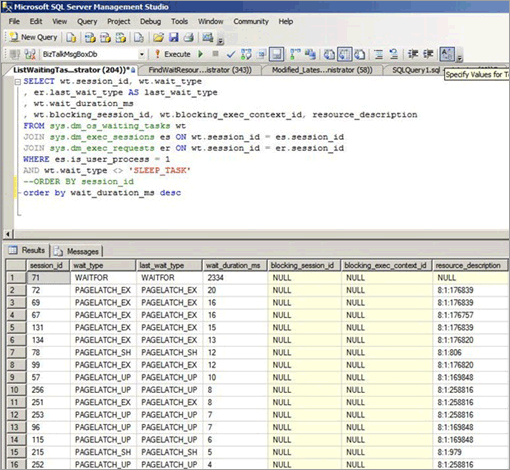
下表总结了针对此类闩锁争用观察到的主要因素:
| 因子 | 典型观察结果 |
|---|---|
| SQL Server 使用的逻辑 CPU | 闩锁争用主要发生在具有 16 个以上 CPU 内核的计算机上。 |
| 架构设计和访问模式 | 针对小型表的插入/选择/更新/删除访问模式的比率很高。 浅 B 树(索引深度为 2 或 3)。 行大小较小(每页有很多条记录)。 |
| 并发级别 | 仅在应用程序层发出大量并发请求时,才发生闩锁争用。 |
| 观察到的等待类型 | 由于进行了根拆分,观察到缓冲区闩锁(PAGELATCH_EX 和 PAGELATCH_SH)等待和非缓冲区闩锁 ACCESS_METHODS_HOBT_VIRTUAL_ROOT 等待。 PFS 页上也有 PAGELATCH_UP 等待。 有关非缓冲区闩锁等待的详细信息,请参阅 SQL Server 帮助中的 sys.dm_os_latch_stats (Transact-SQL)。 |
浅 B 树与跨索引随机插入的组合很容易导致 B 树中发生页拆分。 为了执行页拆分,SQL Server 必须在所有级别获取共享 (SH) 闩锁,然后在 B 树中与页拆分有关的页上获取独占 (EX) 闩锁。 当并发性很高并且不断插入和删除数据时,也有可能发生 B 树根拆分。 在这种情况下,其他插入可能必须等待在 B 树上获取的任何非缓冲区闩锁。 这将表现为在 sys.dm_os_latch_stats DMV 中观察到大量 ACCESS_METHODS_HOBT_VIRTUAL_ROOT 闩锁类型等待。
可以修改以下脚本,为受影响的表上的索引确定 B 树的深度。
select o.name as [table],
i.name as [index],
indexProperty(object_id(o.name), i.name, 'indexDepth')
+ indexProperty(object_id(o.name), i.name, 'isClustered') as depth, --clustered index depth reported doesn't count leaf level
i.[rows] as [rows],
i.origFillFactor as [fillFactor],
case (indexProperty(object_id(o.name), i.name, 'isClustered'))
when 1 then 'clustered'
when 0 then 'nonclustered'
else 'statistic'
end as type
from sysIndexes i
join sysObjects o on o.id = i.id
where o.type = 'u'
and indexProperty(object_id(o.name), i.name, 'isHypothetical') = 0 --filter out hypothetical indexes
and indexProperty(object_id(o.name), i.name, 'isStatistics') = 0 --filter out statistics
order by o.name;
页可用空间 (PFS) 页上的闩锁争用
PFS 表示页可用空间,SQL Server 为每个数据库文件中的每 8088 页(从 PageID = 1 开始)分配一个 PFS 页。 PFS 页中的每个字节记录的信息包括:页上有多少可用空间,是否分配了可用空间,以及该页是否存储虚影记录。 PFS 页包含当插入或更新操作需要新页时可分配的页的相关信息。 在许多情况下,包括进行分配或取消分配时,必须更新 PFS 页。 由于需要使用更新 (UP) 闩锁来保护 PFS 页,因此,当文件组中的数据文件相对较少,而 CPU 内核数很多时,就会在 PFS 页上发生闩锁争用。 解决此问题的一种简单方法是增加每个文件组的文件数。
警告
增加每个文件组的文件数可能会对某些负载(例如,将内存溢出到磁盘的具有许多大型排序操作的负载)的性能产生不利影响。
如果在 tempdb 中的 PFS 或 SGAM 页上观察到许多 PAGELATCH_UP 等待,请完成以下步骤消除此瓶颈:
向 tempdb 添加数据文件,使 tempdb 数据文件数等于服务器中的处理器内核数。
启用 SQL Server 跟踪标志 1118。
有关系统页上的争用导致的分配瓶颈的详细信息,请参阅博客文章什么是分配瓶颈?。
tempdb 上的表值函数和闩锁争用
除了分配争用之外,还有其他一些因素可能导致 tempdb 上发生闩锁争用,例如在查询中大量使用 TVF。
处理不同表模式的闩锁争用
以下各部分介绍了可用于解决性能问题的方法,这些问题均与闩锁争用过多有关。
使用非顺序前导索引键
处理闩锁争用的方法之一是将有序索引键替换为无序键,以便在索引范围内均匀分配插入内容。
通常,可以通过在索引中创建一个按比例分布工作负荷的前导列来实现此目的。 下面介绍了两个选项:
选项:使用表中的列在索引键范围内分布值
评估工作负荷的自然值,该值可用于在键范围内分布插入。 以 ATM 银行业务场景为例,因为一个客户一次只能使用一个 ATM,所以 ATM_ID 可能是将插入项分布到交易表以进行取款的理想选择。 同样,在销售点系统中,Checkout_ID 或 Store ID 可能是自然值,可用于在键范围内分布插入。 此方法需要结合使用前导键列(已标识列的值或该值的某个哈希)和一个或多个附加列来创建组合索引键,以提供唯一性。 在大多数情况下,值的哈希效果最佳,因为太多非重复值会导致物理组织不良。 例如,在销售点系统中,可以根据 Store ID 创建哈希作为模数,该模数与 CPU 内核数一致。 此方法会导致表中的范围相对较少,但是,通过这种方式分布插入足以避免闩锁争用问题。 下图演示了此方法。
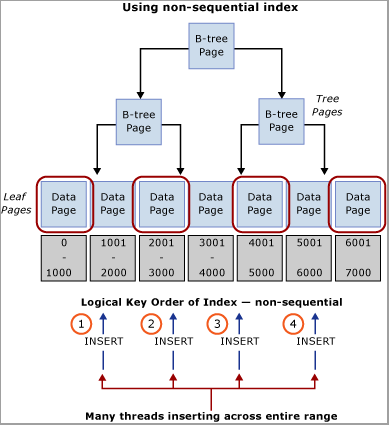
重要
此模式与传统的索引编制最佳做法相矛盾。 尽管此方法有助于确保插入项在 B 树上均匀分布,但也可能需要在应用程序级别进行架构更改。 此外,此模式可能会对需要利用聚集索引进行范围扫描的查询性能产生负面影响。 你需要对工作负荷模式进行一些分析,以确定这种设计方法是否有效。 如果能够牺牲一些顺序扫描性能来提高插入吞吐量和缩放性,则应实施此模式。
此模式是在性能实验室参与期间实施的,它解决了具有 32 个物理 CPU 内核的系统上的闩锁争用问题。 该表用于存储交易结束时的期末余额;每笔业务交易均在表中插入一次。
原始表定义
使用原始表定义时,在聚集索引 pk_table1 上观察到过多闩锁争用:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (TransactionID, UserID);
go
注意
表定义中的对象名称已从原始值更改为其他值。
重新排序的索引定义
通过使用 UserID 作为主键中的前导列对索引的键列进行重新排序,在页之间提供了几乎随机的插入分布。 由于并非所有用户都同时在线,因此产生的分布不是 100% 随机的,但是这种分布随机程度足以缓解过多闩锁争用问题。 对索引定义重新排序时需要注意,针对该表的所有 select 查询都必须修改为同时使用 UserID 和 TransactionID 作为相等谓词。
重要
在生产环境中运行之前,请确保在测试环境中全面测试所有更改。
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (UserID, TransactionID);
go
使用哈希值作为主键中的前导列
以下表定义可用于生成与 CPU 数量一致的模数,使用按顺序递增的值 TransactionID 生成 HashValue,以确保在 B 树上均匀分布:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
-- Consider using bulk loading techniques to speed it up
ALTER TABLE table1
ADD [HashValue] AS (CONVERT([tinyint], abs([TransactionID])%(32))) PERSISTED NOT NULL
alter table table1
add constraint pk_table1
primary key clustered (HashValue, TransactionID, UserID);
go
选项:使用 GUID 作为索引的前导键列
如果没有自然分隔符,则可以将 GUID 列用作索引的前导键列,以确保插入的均匀分布。 虽然“使用 GUID 作为索引键中的前导列”方法允许将分区用于其他功能,但这种方法也有可能带来更多页拆分、不良物理组织和低页密度等潜在弊端。
注意
使用 GUID 作为索引的前导键列是一个备受争议的话题。 本文不对此方法的优缺点进行深入讨论。
使用包含计算列的哈希分区
SQL Server 中的表分区可用于减轻过多闩锁争用。 在已分区表中创建一个包含计算列的哈希分区方案是一种常见方法,可通过以下步骤完成:
创建新文件组或使用现有文件组来保存分区。
如果使用新的文件组,请在 LUN 上均衡各个文件,并注意使用最佳布局。 如果访问模式涉及较高的插入率,请确保创建与 SQL Server 计算机上的物理 CPU 内核数相同的文件数。
使用 CREATE PARTITION FUNCTION 命令将表划分为 X 个分区,其中 X 是 SQL Server 计算机上的物理 CPU 内核数。 (最多 32 个分区)
注意
分区数与 CPU 内核数无需始终 1:1。 在许多情况下,分区数可以小于 CPU 内核数。 分区越多会导致查询开销越多,因为查询必须搜索所有分区,在这种情况下,减少分区是有益处的。 在针对具有实际客户工作负荷的 64 和 128 个逻辑 CPU 系统的 SQLCAT 测试中,32 个分区就足以解决闩锁争用过多的问题并达到扩展目标。 最终,理想的分区数应通过测试确定。
使用 CREATE PARTITION SCHEME 命令:
- 将分区函数绑定到文件组。
- 将类型为 tinyint 或 smallint 的哈希列添加到表中。
- 计算良好的哈希分布。 例如,将 hashbytes 与模数或 binary_checksum 一起使用。
可根据实现目的自定义以下示例脚本:
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
该脚本可用于对因最后一页/尾页插入争用出现问题的表进行哈希分区。 此方法通过对表进行分区,并使用哈希值取模运算在表分区之间分布插入,消除了最后一页的争用。
包含计算列的哈希分区的作用
如下图所示,此方法通过在哈希函数上重新生成索引,并创建与 SQL Server 计算机上的物理 CPU 内核相同数量的分区,消除了最后一页的争用。 插入项仍将进入逻辑范围的末尾(按顺序递增的值),但哈希值取模运算可确保跨不同的 B 树拆分插入,从而减轻瓶颈。 下图对此进行了说明:
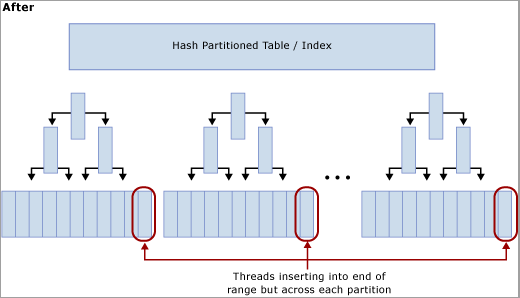
使用哈希分区时的权衡取舍
虽然哈希分区可以消除插入争用,但在决定是否使用此方法时,需要权衡以下几点:
在大多数情况下,需要修改 select 查询以在谓词中包含哈希分区,这会生成在发出这些查询时不提供分区消除的查询计划。 以下屏幕截图显示了一个在实施哈希分区后不提供分区消除的错误计划。

它导致无法对其他特定查询(例如基于范围的报表)消除分区。
将哈希分区表联接到另一个表时,若要实现分区消除,需在同一个键上对第二个表进行哈希分区,并且哈希键应成为联接条件的一部分。
哈希分区导致无法将分区用于其他管理功能,例如滑动窗口存档和分区切换功能。
哈希分区是一种缓解过多闩锁争用的有效策略,因为它确实通过减轻插入争用提高了系统总吞吐量。 由于涉及一些权衡取舍,对于某些访问模式,它可能不是最佳解决方案。
闩锁争用解决方法汇总
以下两部分概述了可用于解决过多闩锁争用的方法:
非顺序键/索引
优点:
- 允许使用其他分区功能,例如使用滑动窗口方案和分区切换功能来存档数据。
缺点:
- 在选择键/索引以确保始终尽可能均匀地分布插入时,可能会遇到一些挑战。
- 作为前导列的 GUID 可用于确保均匀分布,但要注意,它可能会导致页拆分操作过多。
- 跨 B 树的随机插入可能会导致页拆分操作过多,并导致非叶页上发生闩锁争用。
包含计算列的哈希分区
优点:
- 对于插入是透明的。
缺点:
- 不能将分区用于预期的管理功能,例如使用分区切换选项存档数据。
- 对于包括单个选择/更新和基于范围的选择/更新的查询以及执行联接的查询,可能会导致分区消除问题。
- 添加持久化计算列是一项脱机操作。
提示
有关其他方法,请参阅博客文章 PAGELATCH_EX 等待和大量插入。
演练:诊断闩锁争用
以下演练演示了诊断 SQL Server 闩锁争用和处理不同表模式的闩锁争用中所述的工具和方法,以解决现实场景中的问题。 此场景描述了一个客户参与执行负载测试的销售点系统,该系统模拟了将近 8,000 家商店对 SQL Server 应用程序执行交易的情况,该应用程序在具有 256 GB 内存和 32 个物理内核的 8 插槽系统上运行。
下图详细描述了用于测试销售点系统的硬件:

症状:热闩锁
在本例中,我们观察到 PAGELATCH_EX 等待时间很长,我们通常将等待时间长定义为平均超过 1 毫秒。 在本例中,我们观察到等待时间一直超过 20 毫秒。
一旦确定闩锁争用是有问题的,我们便着手确定是什么导致闩锁争用。
找出导致闩锁争用的对象
以下脚本使用 resource_description 列找出导致 PAGELATCH_EX 争用的索引:
注意
该脚本返回的 resource_description 列以 <DatabaseID,FileID,PageID> 的格式提供资源描述,其中,与 DatabaseID 关联的数据库名称可以通过将 DatabaseID 的值传递给 DB_NAME () 函数来确定。
SELECT wt.session_id, wt.wait_type, wt.wait_duration_ms
, s.name AS schema_name
, o.name AS object_name
, i.name AS index_name
FROM sys.dm_os_buffer_descriptors bd
JOIN (
SELECT *
--resource_description
, CHARINDEX(':', resource_description) AS file_index
, CHARINDEX(':', resource_description, CHARINDEX(':', resource_description)+1) AS page_index
, resource_description AS rd
FROM sys.dm_os_waiting_tasks wt
WHERE wait_type LIKE 'PAGELATCH%'
) AS wt
ON bd.database_id = SUBSTRING(wt.rd, 0, wt.file_index)
AND bd.file_id = SUBSTRING(wt.rd, wt.file_index+1, 1) --wt.page_index)
AND bd.page_id = SUBSTRING(wt.rd, wt.page_index+1, LEN(wt.rd))
JOIN sys.allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id
order by wt.wait_duration_ms desc;
如下所示,争用发生在表 LATCHTEST 和索引名称 CIX_LATCHTEST 上。 请注意,名称已更改为匿名工作负荷。

有关更高级的脚本,该脚本可重复轮询并使用临时表来确定可配置时间段内的总等待时间,请参阅附录中的查询缓冲区描述符以确定导致闩锁争用的对象。
找出导致闩锁争用的对象的替代方法
有时查询 sys.dm_os_buffer_descriptors 可能不切实际。 随着系统内存以及缓冲池可用内存的增加,运行此 DMV 所需的时间也会增加。 在 256 GB 系统上,运行此 DMV 可能需要 10 分钟或更长时间。 下面概述了一种替代方法,并以我们在实验室中运行过的不同工作负荷对其进行了说明:
使用附录脚本查询按等待持续时间排序的 sys.dm_os_waiting_tasks,查询当前的等待任务。
标识观察到护航效应的键页,当多个线程在同一页上争用时会发生这种情况。 在此示例中,执行插入的线程在 B 树的尾页上进行争用,并且一直等到可以获取 EX 闩锁为止。 这由第一个查询中的 resource_description 指示,在本例中为 8:1:111305。
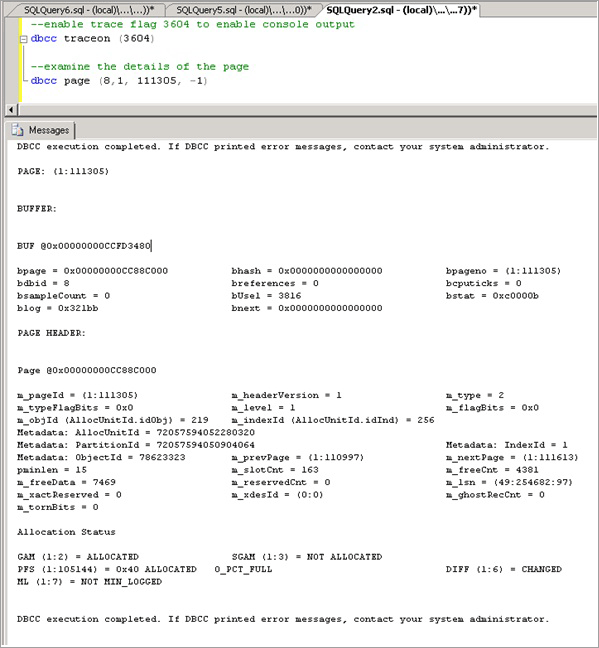
启用跟踪标志 3604,该标志使用以下语法通过 DBCC PAGE 公开有关该页的详细信息,并用括号中的值替换通过 resource_description 获得的值:
--enable trace flag 3604 to enable console output dbcc traceon (3604); --examine the details of the page dbcc page (8,1, 111305, -1);检查 DBCC 输出。 应该有一个关联的 Metadata ObjectID,在本例中为“78623323”。
现在,可以运行以下命令来确定引起争用的对象的名称,该名称应为 LATCHTEST。
注意
确保你在正确的数据库上下文中,否则查询将返回 NULL。
--get object name select OBJECT_NAME (78623323);
摘要和结果
通过使用上述方法,我们可以确认争用发生在表中具有按顺序递增的键值的聚集索引上,该索引迄今为止获得了最多插入。 对于具有按顺序递增的键值(例如日期时间、标识或应用程序生成的 transactionID)的索引,此类争用并不罕见。
为了解决此问题,我们使用了包含计算列的哈希分区,并观察到性能提升了 690%。 下表总结了实施包含计算列的哈希分区之前和之后的应用程序性能。 消除闩锁争用瓶颈后,和我们预期的一样,CPU 利用率的提升与吞吐量的提升基本一致:
| 量化指标 | 进行哈希分区之前 | 进行哈希分区之后 |
|---|---|---|
| Business Transactions/Sec | 36 | 249 |
| Average Page Latch Wait Time | 36 毫秒 | 0.6 毫秒 |
| Latch Waits/Sec | 9,562 | 2,873 |
| SQL Processor Time | 24% | 78% |
| SQL Batch Requests/sec | 12,368 | 47,045 |
从上表可以看出,正确识别并解决由过多页闩锁争用引起的性能问题可能会对应用程序的整体性能产生积极影响。
附录:备用技术
避免过多页闩锁争用的一种可行策略是用 CHAR 列填充行,以确保每一行都占据整页。 当整体数据大小较小并且你需要解决由以下因素组合引起的 EX 页闩锁争用时,可以使用此策略:
- 行大小较小
- 浅 B 树
- 随机插入、选择、更新和删除操作率较高的访问模式
- 小型表,例如临时队列表
通过填充行来占据整页,你需要使用 SQL 来分配更多页,使更多页可供插入并减少 EX 页闩锁争用。
填充行以确保每一行都占据整页
可使用与下面类似的脚本填充行以占据整页:
ALTER TABLE mytable ADD Padding CHAR(5000) NOT NULL DEFAULT ('X');
注意
尽可能使用强制每页一行的最小字符,以减少填充值的额外 CPU 需求以及记录该行所需的额外空间。 在高性能系统中,每一个字节都很重要。
此方法的完整说明如下:在实践中,SQLCAT 仅在单个性能服务中包含 10000 行的小型表上使用过此方法。 对于大型表,此方法会增加 SQL Server 的内存压力,并且可能导致非叶页上发生非缓冲区闩锁争用,因此该方法的应用受到限制。 额外的内存压力可能是应用此技术的重要限制因素。 随着新式服务器中可用内存量的增加,OLTP 工作负荷的大部分工作集通常都保存在内存中。 当数据集增加到内存无法容纳的大小时,性能就会显著下降。 因此,此方法仅适用于小型表。 在大型表的最后一页/尾页插入争用等场景中,SQLCAT 不会使用此方法。
重要
采用此策略可能会导致大量 ACCESS_METHODS_HOBT_VIRTUAL_ROOT 闩锁类型等待,因为此策略可能导致在 B 树的非叶级别发生大量页拆分。 如果发生这种情况,SQL Server 必须在所有级别获取共享 (SH) 闩锁,然后在 B 树中可能进行页拆分的页上获取独占 (EX) 闩锁。 填充行之后,检查 sys.dm_os_latch_stats DMV,看是否有大量 ACCESS_METHODS_HOBT_VIRTUAL_ROOT 闩锁类型等待。
附录:SQL Server 闩锁争用脚本
本部分包含可用于帮助诊断和解决闩锁争用问题的脚本。
查询按会话 ID 排序的 sys.dm_os_waiting_tasks
以下示例脚本将查询 sys.dm_os_waiting_tasks 并返回按会话 ID 排序的闩锁等待:
-- WAITING TASKS ordered by session_id
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id,
resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY session_id;
查询按等待持续时间排序的 sys.dm_os_waiting_tasks
以下示例脚本将查询 sys.dm_os_waiting_tasks 并返回按等待时间排序的闩锁等待:
-- WAITING TASKS ordered by wait_duration_ms
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc;
计算一段时间内的等待数
以下脚本计算并返回一段时间内的闩锁等待数。
/* Snapshot the current wait stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
use tempdb
go
declare @current_snap_time datetime;
declare @previous_snap_time datetime;
set @current_snap_time = GETDATE();
if not exists(select name from tempdb.sys.sysobjects where name like '#_wait_stats%')
create table #_wait_stats
(
wait_type varchar(128)
,waiting_tasks_count bigint
,wait_time_ms bigint
,avg_wait_time_ms int
,max_wait_time_ms bigint
,signal_wait_time_ms bigint
,avg_signal_wait_time int
,snap_time datetime
);
insert into #_wait_stats (
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,snap_time
)
select
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,getdate()
from sys.dm_os_wait_stats;
--get the previous collection point
select top 1 @previous_snap_time = snap_time from #_wait_stats
where snap_time < (select max(snap_time) from #_wait_stats)
order by snap_time desc;
--get delta in the wait stats
select top 10
s.wait_type
, (e.waiting_tasks_count - s.waiting_tasks_count) as [waiting_tasks_count]
, (e.wait_time_ms - s.wait_time_ms) as [wait_time_ms]
, (e.wait_time_ms - s.wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_wait_time_ms]
, (e.max_wait_time_ms) as [max_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms) as [signal_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_signal_time_ms]
, s.snap_time as [start_time]
, e.snap_time as [end_time]
, DATEDIFF(ss, s.snap_time, e.snap_time) as [seconds_in_sample]
from #_wait_stats e
inner join (
select * from #_wait_stats
where snap_time = @previous_snap_time
) s on (s.wait_type = e.wait_type)
where
e.snap_time = @current_snap_time
and s.snap_time = @previous_snap_time
and e.wait_time_ms > 0
and (e.waiting_tasks_count - s.waiting_tasks_count) > 0
and e.wait_type NOT IN ('LAZYWRITER_SLEEP', 'SQLTRACE_BUFFER_FLUSH'
, 'SOS_SCHEDULER_YIELD','DBMIRRORING_CMD', 'BROKER_TASK_STOP'
, 'CLR_AUTO_EVENT', 'BROKER_RECEIVE_WAITFOR', 'WAITFOR'
, 'SLEEP_TASK', 'REQUEST_FOR_DEADLOCK_SEARCH', 'XE_TIMER_EVENT'
, 'FT_IFTS_SCHEDULER_IDLE_WAIT', 'BROKER_TO_FLUSH', 'XE_DISPATCHER_WAIT'
, 'SQLTRACE_INCREMENTAL_FLUSH_SLEEP')
order by (e.wait_time_ms - s.wait_time_ms) desc ;
--clean up table
delete from #_wait_stats
where snap_time = @previous_snap_time;
查询缓冲区描述符以确定导致闩锁争用的对象
以下脚本查询缓冲区描述符,以确定哪些对象与最长闩锁等待时间关联。
IF EXISTS (SELECT * FROM tempdb.sys.objects WHERE [name] like '#WaitResources%') DROP TABLE #WaitResources;
CREATE TABLE #WaitResources (session_id INT, wait_type NVARCHAR(1000), wait_duration_ms INT,
resource_description sysname NULL, db_name NVARCHAR(1000), schema_name NVARCHAR(1000),
object_name NVARCHAR(1000), index_name NVARCHAR(1000));
GO
declare @WaitDelay varchar(16), @Counter INT, @MaxCount INT, @Counter2 INT
SELECT @Counter = 0, @MaxCount = 600, @WaitDelay = '00:00:00.100'-- 600x.1=60 seconds
SET NOCOUNT ON;
WHILE @Counter < @MaxCount
BEGIN
INSERT INTO #WaitResources(session_id, wait_type, wait_duration_ms, resource_description)--, db_name, schema_name, object_name, index_name)
SELECT wt.session_id,
wt.wait_type,
wt.wait_duration_ms,
wt.resource_description
FROM sys.dm_os_waiting_tasks wt
WHERE wt.wait_type LIKE 'PAGELATCH%' AND wt.session_id <> @@SPID
--select * from sys.dm_os_buffer_descriptors
SET @Counter = @Counter + 1;
WAITFOR DELAY @WaitDelay;
END;
--select * from #WaitResources;
update #WaitResources
set db_name = DB_NAME(bd.database_id),
schema_name = s.name,
object_name = o.name,
index_name = i.name
FROM #WaitResources wt
JOIN sys.dm_os_buffer_descriptors bd
ON bd.database_id = SUBSTRING(wt.resource_description, 0, CHARINDEX(':', wt.resource_description))
AND bd.file_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description) + 1, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) - CHARINDEX(':', wt.resource_description) - 1)
AND bd.page_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) + 1, LEN(wt.resource_description) + 1)
--AND wt.file_index > 0 AND wt.page_index > 0
JOIN sys.allocation_units au ON bd.allocation_unit_id = AU.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id;
select * from #WaitResources order by wait_duration_ms desc;
GO
/*
--Other views of the same information
SELECT wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY wait_type, db_name, schema_name, object_name, index_name;
SELECT session_id, wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY session_id, wait_type, db_name, schema_name, object_name, index_name;
*/
--SELECT * FROM #WaitResources
--DROP TABLE #WaitResources;
哈希分区脚本
使用包含计算列的哈希分区中介绍了此脚本的用法,应根据实现目的对其进行自定义。
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
后续步骤
有关性能监视工具的详细信息,请参阅性能监视和优化工具。