列存储索引:概述
适用于: ![]() SQL Server
SQL Server ![]() Azure SQL 数据库
Azure SQL 数据库 ![]() Azure SQL 托管实例
Azure SQL 托管实例 ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() 分析平台系统 (PDW)
分析平台系统 (PDW)
列存储索引是存储和查询大型数据仓库事实数据表的标准。 此索引使用基于列的数据存储和查询处理,与面向行的传统存储相比,最多可实现 10 倍的数据仓库查询性能提升。 此外,与处理非压缩数据相比,处理压缩数据可将性能提升 10 倍。 自 SQL Server 2016 (13.x) SP1 起,列存储索引支持操作分析,即能够对事务工作负载运行高性能实时分析。
了解相关方案:
什么是列存储索引?
列存储索引是一种使用列式数据格式(称为“列存储”)存储、检索和管理数据的技术。
重要术语和概念
以下关键概念和术语与列存储索引相关联。
列存储
列存储是在逻辑上整理为包含行和列的表,实际上以列式数据格式存储的数据。
行存储
行存储是在逻辑上整理为包含行和列的表,实际上以行式数据格式存储的数据。 此格式是存储关系表数据的传统方法。 在 SQL Server 中,行存储是指基础数据存储格式为堆、聚集索引或内存优化表的表。
注意
提到列存储索引时,行存储和列存储这两个词用于强调数据存储格式。
行组
行组是同时压缩为列存储格式的一组行。 每个行组通常可包含的最大行数是 1,048,576 行。
为获得高性能和高压缩率,列存储索引先将表划分为行组,再按列式格式压缩每个行组。 行组中的行数必须足够大,以便提高压缩率,并且还要足够小,以便从内存中操作中受益。
从中删除了所有数据的行组从“压缩”状态转换为“逻辑删除”状态,并且稍后由名为 tuple-mover 的后台进程删除。 有关行组状态的详细信息,请参阅 sys.dm_db_column_store_row_group_physical_stats (Transact-SQL)。
提示
小行组过多会降低列存储索引的质量。 在 SQL Server 2017 (14.x) 之前,重新组织操作需要遵循一个内部阈值策略(确定如何移除已删除行并合并已压缩行组)来合并较小的 COMPRESSED 行组。
从 SQL Server 2019 (15.x) 开始,后台合并任务也用于合并从中删除大量行的 COMPRESSED 行组。
合并较小的行组后,索引质量应有所提高。
注意
从 SQL Server 2019 (15.x) 开始的 SQL Server、Azure SQL 数据库、Azure SQL 托管实例和 Azure Synapse Analytics 中的专用 SQL 池:元组移动器通过后台合并任务获得帮助,该任务会自动压缩较小的已存在一段时间(由内部阈值确定)的 OPEN 增量行组,或者合并已从中删除大量行的 COMPRESSED 行组。 随着时间的推移,这会提高列存储索引的质量。
列段
列段是行组内的数据列。
- 每个行组包含表中每个列的一个列段。
- 每个列段一起压缩并且存储于物理介质上。
- 每个段都有元数据可用于快速消除段,无需读取它们。
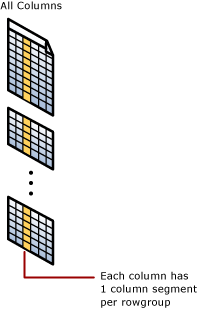
聚集列存储索引
聚集列存储索引是整个表的物理存储。
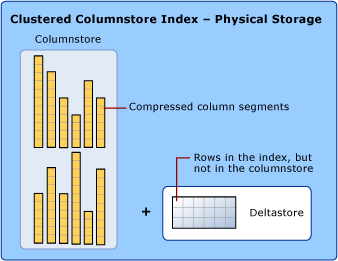
为了减少列段碎片和提升性能,列存储索引可能会将一些数据暂时存储到称为“增量存储”的聚集索引中,同时还存储已删除行的 ID 的 B 树列表。 增量存储操作在后台处理。 若要返回正确的查询结果,聚集列存储索引将合并来自列存储和增量存储的查询结果。
注意
文档在提到索引时一般使用 B 树这个术语。 在行存储索引中,数据库引擎实现了 B+ 树。 这不适用于列存储索引或内存优化表上的索引。 有关详细信息,请参阅 SQL Server 以及 Azure SQL 索引体系结构和设计指南。
增量行组
增量行组是仅用于列存储索引的聚集 B 树索引。 它提升了列存储压缩率和性能,这是通过存储行并在行数达到阈值(1,048,576 行)后将行移入列存储来实现的。
在增量行组达到最大行数后,它会从“开启”状态转换为“关闭”状态。 名为 tuple-mover 的后台进程会检查已关闭的行组。 如果进程找到已关闭的行组,就会压缩增量行组,并将其作为 COMPRESSED 行组存储到列存储中。
压缩增量行组后,现有的增量行组会转换为“逻辑删除”状态,以便稍后由元组移动器在没有引用该行组时将其删除。
有关行组状态的详细信息,请参阅 sys.dm_db_column_store_row_group_physical_stats (Transact-SQL)。
注意
从 SQL Server 2019 (15.x) 开始,元组移动器通过后台合并任务获得帮助,该任务会自动压缩较小的已存在一段时间(由内部阈值确定)的 OPEN 增量行组,或者合并已从中删除大量行的 COMPRESSED 行组。 随着时间的推移,这会提高列存储索引的质量。
增量存储
列存储索引可以有多个增量行组。 所有增量行组统称为“增量存储”。
在大容量加载期间,大多数行直接转到列存储,而不通过增量存储中转。 在大容量加载结束时,某些行的数量太少了,可能无法满足行组的大小下限要求(即 102,400 行)。 因此,最后行转到增量存储(而不是列存储)中。 对于少于 102,400 行的较小的大容量加载,所有行都直接转到增量存储中。
非聚集列存储索引
非聚集列存储索引和聚集列存储索引的功能相同。 不同之处在于,非聚集索引是对行存储表创建的辅助索引,而聚集列存储索引是整个表的主存储。
非聚集索引包含基础表中部分或全部行与列的副本。 索引定义为表的一个或多个列,并包含可用于筛选行的可选条件。
非聚集列存储索引支持实时运营分析,其中 OLTP 工作负载使用基础聚集索引,同时对列存储索引并发运行分析。 有关详细信息,请参阅开始使用列存储进行实时运营分析。
批模式执行
批处理模式执行是一种查询处理方法,用于同时处理多个行。 批模式执行与列存储存储格式紧密集成,并且围绕列存储存储格式进行了优化。 批处理模式执行有时亦称为基于矢量或矢量化执行。 对列存储索引执行的查询使用批处理模式执行,这通常可将查询性能提升 2 到 4 倍。 有关详细信息,请参阅查询处理体系结构指南。
为何要使用列存储索引?
列存储索引可实现极高的数据压缩级别(通常是传统方法的 10 倍),从而明显降低数据仓库存储成本。 对于分析,列存储索引实现的性能比 B 树索引高出一个量级。 列存储索引是数据仓库和分析工作负载的首选数据存储格式。 从 SQL Server 2016 (13.x) 开始,可以使用列存储索引对操作工作负荷执行实时分析。
列存储索引速度较快的原因:
列存储来自同一个域且通常相似的值,从而提高了压缩率。 最大限度地减少或消除系统中的 I/O 瓶颈,并显著降低内存占用量。
较高的压缩率通过使用更小的内存中空间提高查询性能。 反过来,由于 SQL Server 可以在内存中执行更多查询和数据操作,因此可以提升查询性能。
批处理执行可同时处理多个行,通常可将查询性能提高 2 到 4 倍。
查询通常仅从表中选择几列,这减少了从物理介质的总 I/O。
何时应使用列存储索引?
建议的用例:
使用聚集列存储索引来存储数据仓库工作负载的事实数据表和大型维度表。 这种方法最多可将查询性能和数据压缩率提高 10 倍。 有关详细信息,请参阅用于数据仓库的列存储索引。
使用非聚集列存储索引对 OLTP 工作负载执行实时分析。 有关详细信息,请参阅开始使用列存储进行实时运营分析。
有关列存储索引的更多使用方案,请参阅根据需要选择最佳列存储索引。
如何在行存储索引与列存储索引之间做出选择?
行存储索引最适合用于查找数据、搜索特定值的查询,或者针对较小范围的值执行的查询。 对事务工作负载使用行存储索引,因为它们往往大多需要进行表查找,而不是表扫描。
对于扫描大量数据(尤其是大型表中)的分析查询,列存储索引可提高性能。 对数据仓库和分析工作负载(尤其是事实数据表)使用列存储索引,因为它们往往需要进行全表扫描,而不是表查找。
有序聚集列存储索引可提高基于有序列谓词的查询性能。 有序列存储索引可以优化行组消除,即可以通过完全跳过行组来提高性能。 有关详细信息,请参阅 使用有序聚集列存储索引进行性能优化。 有关有序列存储索引可用性,请参阅 有序列索引可用性。
是否可以在同一个表中组合行存储与列存储?
是的。 自 SQL Server 2016 (13.x) 起,可以对行存储表创建可更新的非聚集列存储索引。 列存储索引存储选定列的副本,所以需要为此数据留出额外空间,但选定数据可实现平均 10 倍的压缩率。 可以同时对列存储索引和行存储索引上的事务运行分析。 列存储随行存储表中的数据更改一起更新,因此这两个索引处理的是相同数据。
自 SQL Server 2016 (13.x) 起,可以对列存储索引创建一个或多个非聚集行存储索引,并对基础列存储执行高效表查找。 其他选项也可供使用。 例如,可以通过在行存储表中使用 UNIQUE 约束来强制主键约束。 由于非唯一值无法插入到行存储表中,因此 SQL Server 无法将值插入列存储。
有序列存储索引
通过启用高效的分段消除,有序聚集列存储索引(CCI)通过跳过与查询谓词不匹配的大量有序数据来提供更快的性能。 由于需要执行数据排序操作,将数据载入有序 CCI 表所需的时间可能比载入无序 CCI 表更长,但之后,查询可以使用有序 CCI 更快地运行。
- 有关使用有序聚集列存储索引的SQL 数据库引擎中优化数据仓库工作负荷的详细信息,请参阅使用有序聚集列存储索引进行性能优化。
- 有关何时使用哪种类型的列存储索引的详细信息,请参阅 根据需要选择最佳列存储索引。
有序列存储索引可用性
SQL Server 2022(16.x)首次引入 ![]() 的有序列存储索引可在以下平台中使用。
的有序列存储索引可在以下平台中使用。
| 平台 | 有序 聚集 列存储索引 | 已排序 的非聚集 列存储索引 |
|---|---|---|
| Azure SQL 数据库 | 是 | 是 |
| SQL Server 2022 (16.x) | 是 | 否 |
| Azure SQL 托管实例 | 是 | 是 |
| Azure Synapse Analytics 中的专用 SQL 池 | 是 | 否 |
元数据
列存储索引中的所有列在元数据中作为包含性列存储。 列存储索引中没有任何键列。
相关任务
所有关系表(除非指定为非聚集列存储索引)使用行存储作为基础数据格式。 如果不指定 WITH CLUSTERED COLUMNSTORE INDEX 选项,则 CREATE TABLE 将创建行存储表。
使用 CREATE TABLE 语句创建表时,可通过指定 WITH CLUSTERED COLUMNSTORE INDEX 选项,将表创建为列存储。 如果你已有一个行存储表并想要将其转换为列存储,可以使用 CREATE COLUMNSTORE INDEX 语句。
| 任务 | 参考文章 | 备注 |
|---|---|---|
| 将表创建为列存储。 | CREATE TABLE (Transact-SQL) | 从 SQL Server 2016 (13.x) 开始,可以将表创建为聚集列存储索引。 无需先创建行存储表,再将它转换为列存储。 |
| 创建具有列存储索引的内存优化表。 | CREATE TABLE (Transact-SQL) | 从 SQL Server 2016 (13.x) 开始,你可以创建具有列存储索引的内存优化表。 也可以在创建表后使用 ALTER TABLE ADD INDEX 语法添加列存储索引。 |
| 将行存储表转换为列存储。 | CREATE COLUMNSTORE INDEX (Transact-SQL) | 将现有堆或 B 树转换为列存储。 示例演示了如何在执行此转换时处理现有的索引以及索引的名称。 |
| 将列存储表转换为行存储。 | CREATE CLUSTERED INDEX (Transact-SQL) 或将列存储表转换回行存储堆 | 通常不需要这样转换,但有时需要。 示例演示如何将列存储转换为堆或聚集索引。 |
| 在行存储表中创建列存储索引。 | CREATE COLUMNSTORE INDEX (Transact-SQL) | 一个行存储表可以有一个列存储索引。 从 SQL Server 2016 (13.x) 开始,列存储索引可以包含筛选条件。 示例演示了基本语法。 |
| 为操作分析创建高性能索引。 | 开始使用列存储进行实时运营分析 | 介绍如何创建互补性列存储索引和 B 树索引,以便 OLTP 查询使用 B 树索引,分析查询使用列存储索引。 |
| 为数据仓库创建高性能列存储索引。 | 用于数据仓库的列存储索引 | 介绍如何使用列存储表上的 B 树索引来创建高性能数据仓库查询。 |
| 使用 B 树索引对列存储索引强制实施主键约束。 | 用于数据仓库的列存储索引 | 演示如何合并 B 树和列存储索引,以便对列存储索引强制实施主键约束。 |
| 删除列存储索引。 | DROP INDEX (Transact-SQL) | 使用 B 树索引所用的标准 DROP INDEX 语法删除列存储索引。 删除聚集列存储索引会将列存储表转换为堆。 |
| 从列存储索引中删除行。 | DELETE (Transact-SQL) | 使用 DELETE (Transact-SQL) 删除行。 “列存储”行:SQL Server 将行标记为已在逻辑上删除,但在重新生成索引前未回收行的物理存储。 “增量存储”行:SQL Server 在逻辑上和实际上都删除了行。 |
| 更新列存储索引中的行。 | UPDATE (Transact-SQL) | 使用 UPDATE (Transact-SQL) 更新行。 “列存储”行:SQL Server 将它标记为已逻辑删除,然后将更新的行插入增量存储中。 “增量存储”行:SQL Server 在增量存储中更新行。 |
| 将数据加载到列存储索引中。 | 列存储索引数据加载 | |
| 强制增量存储中的所有行进入列存储。 | ALTER INDEX (Transact-SQL) ... REBUILD 优化索引维护以提高查询性能并减少资源消耗 |
结合使用 ALTER INDEX 和 REBUILD 选项,以强制所有行都转入列存储。 |
| 对列存储索引进行碎片整理。 | ALTER INDEX (Transact-SQL) | ALTER INDEX ... REORGANIZE 联机对列存储索引进行碎片整理。 |
| 合并具有列存储索引的表。 | MERGE (Transact-SQL) |