适用于:![]() SQL Server 2016 (13.x) 及以后版本
SQL Server 2016 (13.x) 及以后版本 ![]() Azure SQL 数据库
Azure SQL 数据库![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Microsoft Fabric 中的 SQL 数据库
Microsoft Fabric 中的 SQL 数据库
数据虚拟化 允许对外部数据运行 Transact-SQL(T-SQL)查询,而无需将其加载到数据库中。 PolyBase 是跨 SQL Server 和 Azure SQL 实现数据虚拟化的数据库引擎功能。 定义外部数据源、可选文件格式和外部表,然后使用任何其他表一样查询外部表 SELECT 。
本指南可帮助你:
- 了解您的 SQL 平台及其版本支持哪些 PolyBase 功能。
- 在查询或引入数据时,可在
OPENROWSET、外部表和BULK INSERT之间进行选择。 - 遵循常见方案的分步链接。
- 查看生产工作负荷的性能、故障排除和最佳做法。
常见用例
下表描述了可能的使用方案。
| 情景 | 使用 |
|---|---|
| 临时文件浏览 | OPENROWSET(BULK ...) |
| BI/reporting 的可重用文件查询 | 文件外部表 |
| 跨数据库查询 (SQL Server、Oracle、Teradata、MongoDB、ODBC) | 具有外部表的 PolyBase 连接器 |
| 将查询结果导出到文件 |
CREATE EXTERNAL TABLE AS SELECT (CETAS) |
| 批量引入到表中 |
BULK INSERT 或 OPENROWSET(BULK ...) 与 INSERT ... SELECT |
哪些功能可在何处使用?
下表显示了每个 SQL 平台上提供了哪些核心 PolyBase 和数据虚拟化功能。 使用此表来确定可以在平台上执行的操作,然后才能使用详细的指南。
| 功能 | SQL Server 2019 | SQL Server 2022 | SQL Server 2025 | Azure SQL 数据库 | Azure SQL 托管实例 | Microsoft Fabric 中的 SQL 数据库 |
|---|---|---|---|---|---|---|
| 外部表 | 是的 | 是的 | 是的 | 是的 | 是的 | 是的 |
| OPENROWSET (BULK) | 是 1 | 是的 | 是的 | 是的 | 是的 | 是的 |
| CETAS (导出) | 否 | 是的 | 是的 | 否 | 是的 | 否 |
| CSV/带分隔符的文件 | 是 2 | 是的 | 是的 | 是的 | 是的 | 是的 |
| Parquet 文件 | 否 | 是的 | 是的 | 是的 | 是的 | 是的 |
| Delta Lake 表 | 否 | 是的 | 是的 | 否 | 否 | 否 |
| 连接到另一个 SQL Server | 是的 | 是的 | 是的 | 否 | 否 | 否 |
| 连接到 Azure SQL 数据库或 Azure SQL 托管实例 | 是 3 | 是 3 | 是 3 | 否 | 否 | 否 |
| 连接到 Oracle/Teradata/MongoDB | 是的 | 是的 | 是的 | 否 | 否 | 否 |
| 连接到 Azure Blob 存储 | 是的 | 是的 | 是的 | 是的 | 是的 | 否 |
| 连接到 ADLS Gen2 | 否 | 是的 | 是的 | 是的 | 是的 | 否 |
| 连接到与 S3 兼容的存储 | 否 | 是的 | 是的 | 否 | 否 | 否 |
| 连接到OneLake(Fabric) | 否 | 否 | 否 | 否 | 否 | 是的 |
| 下推计算 | 是的 | 是的 | 是的 | 否 | 否 | 否 |
| 托管身份验证 | 否 | 否 | 是 4 | 是的 | 是的 | 否 |
1 SQL Server 2019 (15.x) 支持 OPENROWSET(BULK...) 本地和网络文件路径。 在 SQL Server 2022(16.x)及更高版本中,OPENROWSET(BULK...) 还支持使用FORMAT = 'PARQUET'、FORMAT = DELTA 和 FORMAT = 'CSV' 从云存储读取数据。
2 在 SQL Server 2019 (15.x)中,CSV 支持依赖于 Hadoop。 在 SQL Server 2022(16.x)及更高版本中,CSV 可以不依赖 Hadoop 而获得支持。
3 使用 SQL Server 连接器 (sqlserver://)。 数据库作用域凭据针对 Azure SQL 终结点,步骤与连接到其他 SQL Server 的步骤相同。
连接到 Azure Blob 存储(ABS)和 ADLS Gen2 支持 4 个托管标识身份验证。 需要在本地 SQL Server 上使用启用 Azure Arc 的 SQL Server 或运行在 Azure 虚拟机上的 SQL Server。 它在 Azure SQL 数据库和 Azure SQL 托管实例上本地支持。
注释
从 SQL Server 2025(17.x)开始,查询 Azure Blob 存储、ADLS Gen2 或 S3 兼容的存储上的数据文件(CSV、Parquet 和 Delta)是本机引擎功能,不再需要安装或运行 PolyBase 服务。 RDBMS 连接器(SQL Server、Oracle、Teradata、MongoDB、ODBC)仍需要安装并运行 PolyBase 服务。 SQL Server 2025 (17.x) 还增加了对这些连接器的 Linux 支持,这些连接器以前仅在 Windows 上可用。
查询外部数据
在选择特定方案之前,请了解查询外部数据的三种方法:
| 方法 | Syntax | 何时使用 | 身份验证 | 必须使用 PolyBase |
|---|---|---|---|---|
| OLE DB 即席查询 | OPENROWSET(provider, connection, query) |
需要快速的一次性查询,而无需持久对象,或需要Microsoft Entra ID 身份验证 | SQL 身份验证、Windows 身份验证、Microsoft Entra ID (MSOLEDBSQL) | 否 |
| 归档临时查询 | OPENROWSET(BULK ...) |
在创建表之前,需要快速浏览文件数据或测试架构 | SAS 令牌、访问密钥、托管标识、Microsoft Entra ID | 支持 Azure SQL 数据库和 Azure SQL 托管实例. 对于 SQL Server 实例,否 |
| 持久数据连接器 |
CREATE EXTERNAL TABLE 与 sqlserver://、 oracle://、 teradata://等 |
需要重复访问、管理、统计和下推计算以进行生产 | 仅 SQL 身份验证 | 是的 |
SQL Server 2019(15.x)和 SQL Server 2022(16.x)中的云文件访问需要 PolyBase 服务。 SQL Server 2025 (17.x) 和更高版本对没有 PolyBase 的 CSV、Parquet 和 Delta 具有本机支持。
决策指南
| 情景 | 建议 |
|---|---|
| 我需要 Microsoft Entra ID 身份验证用于远程 SQL,或避免 PolyBase 服务 | 使用OPENROWSET(MSOLEDBSQL, ...)(临时,无持久性对象) |
| 我需要对远程数据库进行持久表、统计信息或下推计算 | 使用 CREATE EXTERNAL TABLE 和 PolyBase 连接器(sqlserver://、oracle://、teradata://、mongodb://、odbc://)。
OPENROWSET
不支持连接器 |
| 我正在探索新文件或测试架构 | 使用 OPENROWSET(BULK ...) (快速迭代,无持久性对象) |
| 我正在将文件数据导入到带有转换的表中 | 从INSERT ... SELECT从OPENROWSET(BULK ...) |
| 我需要对许多用户或应用程序进行治理或共享访问 | 使用 CREATE EXTERNAL TABLE 以便集中权限和元数据 |
| 我在 Fabric 中的 SQL 数据库中工作 | 为临时 OneLake 查询使用OPENROWSET(BULK ...)或为可重用访问选择外部表;对于外部存储,请使用 OneLake 快捷方式。 |
选择场景
了解这三种方法后,请使用以下指南之一来实现特定的用例。
查询文件(Parquet、CSV 或 Delta)
如果数据位于 Azure Blob 存储、ADLS Gen2、S3 兼容的存储或 OneLake 上的 Parquet、CSV 或 Delta 文件中,请按照以下指南之一操作:
| 情景 | 推荐指南 | Platforms |
|---|---|---|
| 在 Parquet 或 CSV 文件上进行快速即席查询 | 使用 OPENROWSET。 不需要外部表 |
SQL Server 2022 (16.x) 及更高版本、Azure SQL 数据库、Azure SQL 托管实例、Fabric 中的 SQL 数据库 |
| 对具有持久性架构的 Parquet 文件的重复查询 | 通过 Parquet 创建外部表 | SQL Server 2022 (16.x) 及更高版本、Azure SQL 数据库、Azure SQL 托管实例、Fabric 中的 SQL 数据库 |
| 使用外部表查询 CSV 文件 | 使用带分隔符文本的文件格式创建外部表 | SQL Server 2019 (15.x) 及更高版本、Azure SQL 数据库、Azure SQL 托管实例、Fabric 中的 SQL 数据库 |
| 查询 Delta Lake 表 | 创建外部表 FILE_FORMAT = DeltaLakeFileFormat |
SQL Server 2022 (16.x) 及更高版本 |
| 将查询结果导出 到 Parquet 或 CSV 文件(CETAS) | 使用 CREATE EXTERNAL TABLE AS SELECT |
SQL Server 2022 (16.x) 及更高版本 Azure SQL 托管实例 |
还可以按照以下分步教程之一操作:
| 教程 | 说明 |
|---|---|
| SQL Server 2022 中的 PolyBase 入门 | 涵盖 OPENROWSET 的 Parquet、CSV、外部表和文件夹浏览。 |
| 使用 PolyBase 在 S3 兼容对象存储中虚拟化 parquet 文件 | SQL Server 2022(16.x)及更高版本的教程。 |
| 使用 PolyBase 虚拟化 CSV 文件 | SQL Server 2022(16.x)及更高版本的教程。 |
| 使用 PolyBase 虚拟化 Delta 表 | SQL Server 2022(16.x)及更高版本的教程。 |
| 使用 Azure SQL 数据库进行数据虚拟化(预览版) | 适用于 Parquet 和 CSV 的 Azure SQL 数据库指南。 |
| Azure SQL 托管实例的数据虚拟化 | 适用于 Parquet、CSV 和 CETAS 的 Azure SQL 托管实例指南。 |
| Fabric 中 SQL 数据库中的数据虚拟化 | Fabric 中 SQL 数据库的 OneLake 文件指南。 |
连接到另一个 SQL Server 实例、Azure SQL 数据库或 SQL 托管实例
在 SQL Server 2019(15.x)及更高版本中,PolyBase 可以在不使用链接服务器的情况下查询其他 SQL Server 实例、Azure SQL 数据库或 Azure SQL 托管实例中的表。
重要
Fabric 中的 SQL 数据库中不支持连接器 sqlserver:// 。 PolyBase RDBMS 连接器通过 CREATE DATABASE SCOPED CREDENTIAL 使用 SQL 身份验证,并且不支持 Microsoft Entra ID、托管标识或服务主体身份验证。 由于 Fabric 中的 SQL 数据库需要Microsoft Entra 身份验证,因此无法使用 PolyBase 连接到该数据库。
| 步骤 | 怎么办 |
|---|---|
| 1. 安装 PolyBase | 在 Windows 上安装 PolyBase 或在 Linux 上安装 PolyBase |
| 2.创建凭据 |
CREATE DATABASE SCOPED CREDENTIAL 使用指定的登录名 |
| 3.创建外部数据源 | CREATE EXTERNAL DATA SOURCE ... WITH (LOCATION = 'sqlserver://<server>') |
| 4.创建外部表 | CREATE EXTERNAL TABLE ... WITH (LOCATION = '<db>.<schema>.<table>') |
| 5. 查询 | SELECT * FROM <external_table> |
小窍门
SQL Server 连接器 (sqlserver://) 也适用于 Azure SQL 数据库和 Azure SQL 托管实例。 使用相同的步骤,然后将 LOCATION 设置为 Azure SQL 终结点(例如 sqlserver://myserver.database.windows.net)。
有关详细指南,请参阅 配置 PolyBase 以访问 SQL Server 中的外部数据。
连接到 Oracle、Teradata 或 MongoDB
SQL Server 2019 (15.x) 及更高版本可以通过 PolyBase ODBC 连接器查询 Oracle、Teradata、MongoDB 和 Cosmos DB。
| 数据源 | 指南 | 要求 |
|---|---|---|
| Oracle | 配置 PolyBase 以访问 Oracle 中的外部数据 | SQL Server 2019 (15.x) 及更高版本、Oracle 客户端驱动程序 |
| Teradata | 配置 PolyBase 以访问 Teradata 中的外部数据 | SQL Server 2019 (15.x) 及更高版本 Teradata ODBC 驱动程序 |
| MongoDB /Cosmos DB | 配置 PolyBase 以访问 MongoDB 中的外部数据 | SQL Server 2019 (15.x) 及更高版本 MongoDB ODBC 驱动程序 |
| 任何 ODBC 数据源 | 配置 PolyBase 以使用 ODBC 泛型类型访问外部数据 | SQL Server 2019 (15.x) 及更高版本 (Windows) (从 SQL Server 2025 开始的 Linux(17.x) |
连接到 Azure Blob 存储或 ADLS Gen2
| SQL 平台 | 身份验证选项 | 指南 |
|---|---|---|
| SQL Server 2022 (16.x) 及更高版本 | SAS 令牌、访问密钥、托管标识(从 SQL Server 2025(17.x)开始) | 配置 PolyBase 以访问 Azure Blob 存储中的外部数据 |
| SQL Server 2019 (15.x) | 访问密钥(通过 Hadoop 连接器) | 配置 PolyBase 以访问 Azure Blob 存储中的外部数据 |
| Azure SQL 数据库 | SAS 令牌、托管身份、Microsoft Entra 直连 | 使用 Azure SQL 数据库进行数据虚拟化(预览版) |
| Azure SQL 托管实例 | SAS 令牌,托管标识 | Azure SQL 托管实例的数据虚拟化 |
在 SQL Server 2022(16.x)中,URI 前缀已更改。 从 SQL Server 2019(15.x)或早期版本迁移时:
-
Azure Blob 存储:将
wasb[s]://更改为abs:// -
ADLS Gen2:将
abfs[s]://更改为adls://
有关详细信息,请参阅 配置 PolyBase 以访问 Azure Blob 存储中的外部数据。
连接到与 S3 兼容的对象存储
SQL Server 2022 (16.x) 及更高版本支持 S3 兼容的存储,例如 Amazon S3、MinIO 和 Ceph。
有关详细信息,请参阅配置 PolyBase 以访问 S3 兼容的对象存储中的外部数据。
使用 CREATE EXTERNAL TABLE AS SELECT 导出数据(CETAS)
CETAS 将查询结果导出到 Azure Blob 存储、ADLS Gen2 或 S3 兼容的存储中的外部文件(Parquet 或 CSV)。
| SQL 平台 | 支持 | 导出格式 | 备注 |
|---|---|---|---|
| SQL Server 2022 (16.x) 及更高版本 | 是的 | Parquet、CSV | 需要 服务器配置:允许 polybase 导出 |
| Azure SQL 托管实例 | 是的 | Parquet、CSV | 默认禁用 |
| Azure SQL 数据库 | 否 | 没有 | 不可用 |
| Fabric 中的 SQL 数据库 | 否 | 没有 | 不可用 |
有关 Transact-SQL 参考,请参阅 CREATE EXTERNAL TABLE AS SELECT(CETAS)。
快速入门示例
示例 1:Parquet 文件的即席查询(OPENROWSET)
不需要外部表。 适用于 Fabric 中的 SQL Server 2022(16.x)及更高版本、Azure SQL 数据库、Azure SQL 托管实例和 SQL 数据库。
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
示例 2:Azure Blob 存储中基于 CSV 的外部表
此示例适用于所有支持 PolyBase 的 SQL 平台。
步骤 1:创建数据库主密钥(DMK)。 此步骤是必需的,因为凭据存储 SAS 令牌机密。 但是,如果使用托管标识或Microsoft Entra 身份验证,则可以执行此步骤。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';步骤 2:使用 SAS 令牌创建凭据。 省略前导
?。CREATE DATABASE SCOPED CREDENTIAL MyStorageCred WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<your_SAS_token>'; -- omit the leading '?'步骤 3:创建外部数据源。
CREATE EXTERNAL DATA SOURCE MyAzureStorage WITH ( LOCATION = 'abs://mycontainer@mystorageaccount.blob.core.windows.net', CREDENTIAL = MyStorageCred );步骤 4:为 CSV 创建文件格式。
CREATE EXTERNAL FILE FORMAT CsvFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ',', STRING_DELIMITER = '"', FIRST_ROW = 2 ) );步骤 5:创建外部表。
CREATE EXTERNAL TABLE dbo.SalesExternal ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer NVARCHAR (100) ) WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/data/sales/', FILE_FORMAT = CsvFormat );步骤 6:查询外部表。
SELECT * FROM dbo.SalesExternal WHERE OrderDate >= '2025-01-01';
示例 3:查询另一个 SQL Server 中的表
此示例适用于 SQL Server 2019(15.x)及更高版本。
步骤 1:创建数据库主密钥(由于凭据存储密码而必需)。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';步骤 2:为远程 SQL Server 实例创建凭据。
CREATE DATABASE SCOPED CREDENTIAL RemoteSqlCred WITH IDENTITY = 'remote_user', SECRET = '<password>';步骤 3:创建外部数据源。
CREATE EXTERNAL DATA SOURCE RemoteSqlServer WITH ( LOCATION = 'sqlserver://remote-server.contoso.com', PUSHDOWN = ON, CREDENTIAL = RemoteSqlCred );步骤 4:创建外部表(由三部分构成的名称)。
LOCATIONCREATE EXTERNAL TABLE dbo.RemoteCustomers ( CustomerId INT, CustomerName NVARCHAR (200) COLLATE SQL_Latin1_General_CP1_CI_AS ) WITH ( DATA_SOURCE = RemoteSqlServer, LOCATION = 'SalesDB.dbo.Customers' );步骤 5:跨服务器查询。
SELECT c.CustomerName, s.Amount FROM dbo.RemoteCustomers AS c INNER JOIN dbo.LocalSales AS s ON c.CustomerId = s.CustomerId;
示例 4:使用 CETAS 将结果导出到 Parquet
适用于 SQL Server 2022(16.x)及更高版本 Azure SQL 托管实例。
步骤 1:启用 CETAS(仅限 SQL Server)。
EXECUTE sp_configure 'allow polybase export', 1; RECONFIGURE;步骤 2:创建凭据和数据源(从前面的示例中重复使用)。
步骤 3:为 Parquet 导出创建文件格式。
CREATE EXTERNAL FILE FORMAT ParquetFormat WITH ( FORMAT_TYPE = PARQUET );步骤 4:导出查询结果。
CREATE EXTERNAL TABLE dbo.Sales2025Export WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/exports/sales_2025.parquet', FILE_FORMAT = ParquetFormat ) AS SELECT * FROM Sales.Orders WHERE OrderDate >= '2025-01-01';
PolyBase 的 T-SQL 构建基块
在实现任何方案之前,请了解 PolyBase 使用的核心 T-SQL 对象及其组合方式:
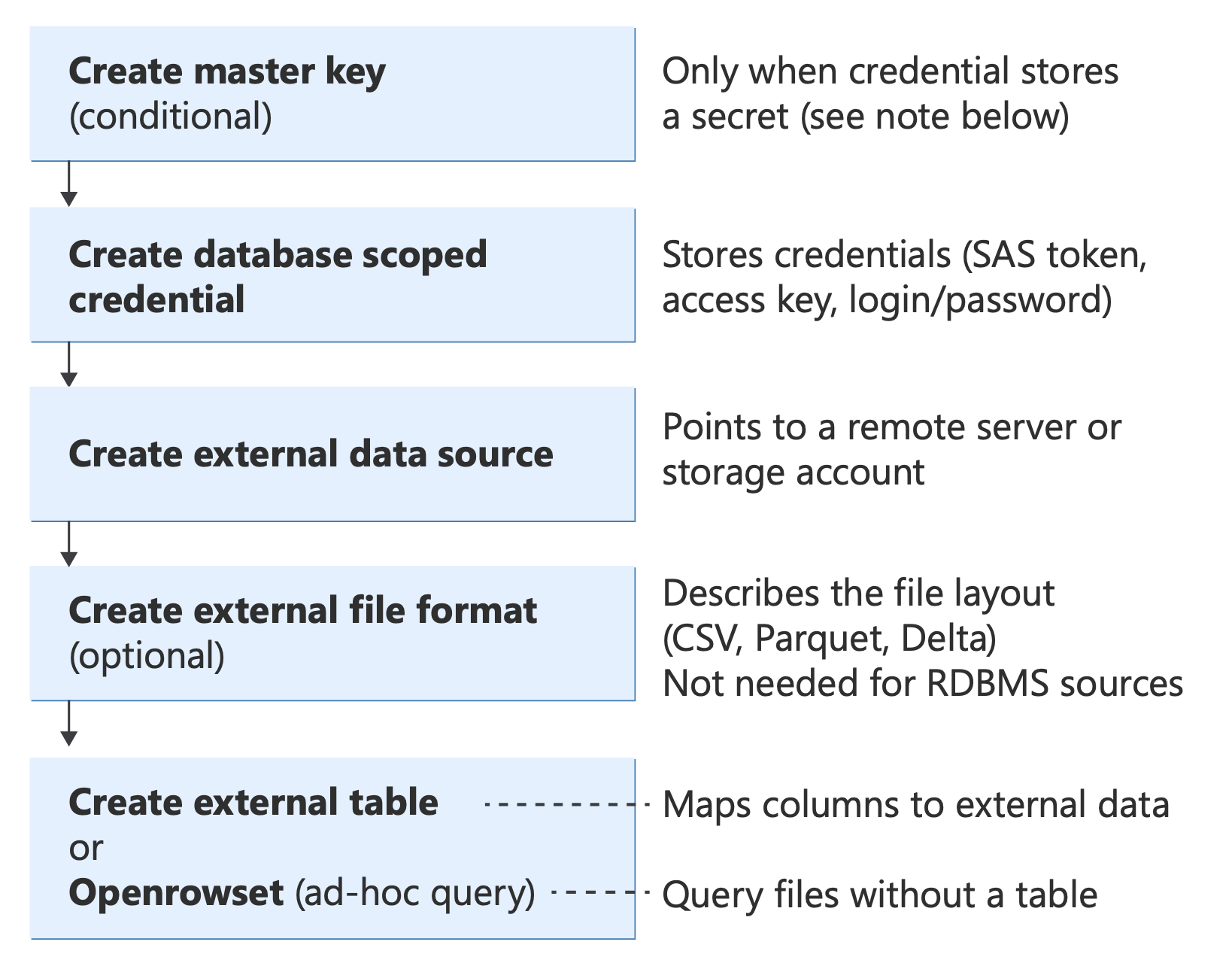
显示 PolyBase T-SQL 对象及其关系的关系图,从身份验证(数据库主密钥、凭据)到数据源和文件格式到查询方法(外部表、OPENROWSET、BULK INSERT、CETAS)。
有关这些 T-SQL 语句的信息,请参阅:
有关所有对象的完整 Transact-SQL 引用,请参阅 PolyBase Transact-SQL 参考。
重要
检查外部文件格式的数据类型映射。 使用 PolyBase 创建外部文件格式或查询文件时 OPENROWSET,会自动将源数据类型(Parquet、CSV、Delta、Oracle、Teradata、MongoDB)映射到 SQL Server 数据类型。 不匹配的类型可能会导致无提示截断、精度丢失或查询错误。 例如,Parquet DECIMAL(38,18) 映射到 DECIMAL(18,0). 在定义外部表列或 WITH 子句之前,请查看映射表。 有关完整参考,请参阅 PolyBase 的类型映射。
何时需要 CREATE MASTER KEY?
数据库主密钥(DMK)是使用 CREATE MASTER KEY 语法创建的。 DMK 对数据库范围凭据中存储的机密进行加密。 仅当凭据包含机密值(即存储密码、令牌或访问密钥时)时才需要它。
DMK 是必需的 (凭据存储机密):
身份验证类型 IDENTITY值有秘密 DMK SAS 令牌 'SHARED ACCESS SIGNATURE'是的 必需 S3 访问密钥 'S3 ACCESS KEY'是的 必需 SQL 登录名/基本身份验证 '<username>'是的 必需 存储帐户访问密钥 '<storage_account_name>'是的 必需 DMK 不是必需的 (没有存储机密):
身份验证类型 IDENTITY值含有机密 DMK 托管的标识 'Managed Identity'否 不是必需 Microsoft Entra ID 'User Identity'或'Managed Identity'否 不是必需
小窍门
如果在 CREATE DATABASE SCOPED CREDENTIAL 语句中没有机密,就不需要 DMK。 托管身份和Microsoft Entra ID身份验证将信任委托给平台。 数据库不存储密码或令牌。
示例:
在此示例查询中,DMK 是必需的(凭据存储 SAS 令牌)。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';
CREATE DATABASE SCOPED CREDENTIAL SasCred
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = '<your_SAS_token>';
在此示例查询中,数据库主密钥 (DMK) 不是必需的(托管身份,无需使用秘密)。
CREATE DATABASE SCOPED CREDENTIAL ManagedIdentityCred
WITH IDENTITY = 'Managed Identity';
在此示例查询中,DMK 不是必需的(Microsoft Entra pass-through,无秘密)。
CREATE DATABASE SCOPED CREDENTIAL EntraIdCred
WITH IDENTITY = 'User Identity';
使用 OPENROWSET 和外部表进行远程数据访问
SQL Server 提供了三种不同的方法来查询远程数据。 了解语法、身份验证和体系结构的差异时,可以选择正确的方法。
| 方法 | Syntax | 连接到 | 身份验证 | PolyBase 服务 | Platforms |
|---|---|---|---|---|---|
| OLE DB 查询 | OPENROWSET(provider, connection, query) |
通过 MSOLEDBSQL、SQLOLEDB 或其他提供程序使用的任何 OLE DB 源 | SQL 身份验证、Windows 身份验证、Microsoft Entra ID (MSOLEDBSQL) | 否 | SQL Server (所有受支持的版本) |
| 文件查询 | OPENROWSET(BULK ...) |
本地磁盘、网络或云上的文件(Azure Blob、ADLS、S3、OneLake) | SAS 令牌、访问密钥、托管标识、Microsoft Entra ID | 是适用于云*;不用于本地 | SQL Server 2005;SQL Server 2022(16.x)及更高版本(云):Azure SQL |
| PolyBase 连接器 |
CREATE EXTERNAL TABLE与CREATE EXTERNAL DATA SOURCE使用sqlserver://、oracle://、teradata://、mongodb://、odbc:// |
远程 SQL Server、Oracle、Teradata、MongoDB、ODBC 源 | 仅 SQL 身份验证 | 是的 | SQL Server 2019 (15.x) 及更高版本 (Windows):SQL Server 2025 (17.x) 及更高版本 (Linux) |
SQL Server 2019(15.x)和 SQL Server 2022(16.x)中的云文件访问需要 PolyBase 服务。 SQL Server 2025 (17.x) 及更高版本具有本机云文件支持,不再需要用于 CSV、Parquet 或 Delta 的 PolyBase。
何时使用每个方法
将 OLE DB OPENROWSET 用于:
- 无需创建永久性对象的快速一次性即席查询
- Microsoft Entra ID 或托管身份验证(通过 MSOLEDBSQL)
- 避免 PolyBase 服务依赖项
- 使用 OLE DB 提供程序连接到任何数据源
将 文件 OPENROWSET(BULK) 用于:
- 临时文件浏览和架构发现
- 在提交表定义之前进行快速转换和预览
- 直接内联灵活列转换(类型转换、筛选、计算列)
- 不经常更改且不需要持久元数据的数据
将 PolyBase 连接器与 CREATE EXTERNAL TABLE 配合使用 ,以便:
- 多个用户或应用程序访问的持久、可重用表定义
- 需要统计信息和查询计划优化的生产工作负荷
- 将下推计算应用到远程数据源(将筛选器推送到 Oracle、SQL Server 等)
- 共享治理和安全性(创建后,用户只需要
SELECT权限) - 将 SQL 身份验证提供给远程源时
OPENROWSET (OLE DB) - 临时远程查询(不需要 PolyBase 服务)
OPENROWSET 的 OLE DB 形式通过 OLE DB 提供程序连接到远程数据源,执行透传查询,并将结果作为数据行集返回。 它是链接服务器的一次性临时替代方法。 不会创建持久性元数据。 此语法不需要 PolyBase 服务,也不支持云文件或外部数据源。
此示例查询通过 OLE DB(而不是 PolyBase)连接到远程 SQL Server。
SELECT *
FROM OPENROWSET (
'MSOLEDBSQL',
'Server=remote-server;Database=AdventureWorks;Trusted_Connection=yes;',
'SELECT TOP 10 * FROM AdventureWorks.Sales.SalesOrderHeader'
);
OPENROWSET(BULK) - 基于文件的查询(PolyBase)
OPENROWSET 的 BULK 形式直接从文件读取数据。 在 SQL Server 2019(15.x)和早期版本中,它从本地或 UNC 文件路径读取,并需要格式化文件。 在 SQL Server 2022(16.x)及更高版本中,可以使用DATA_SOURCE和FORMAT参数从云存储中读取数据。 此方法是用于数据虚拟化的 PolyBase 集成版本。
在 PolyBase 和数据虚拟化背景下,本指南中提到OPENROWSET时,是指使用OPENROWSET(BULK ...)语法,并通过FORMAT子句来查询外部文件。
示例:
此示例查询从 Azure Blob 存储(SQL Server 2022 及更高版本)读取 Parquet 文件。
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'data/sales/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET'
) AS [result];
此示例查询使用内联路径(Azure SQL 数据库、Azure SQL 托管实例)读取 Parquet 文件。
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
何时使用 OPENROWSET 还是外部表之间的比较
和 OPENROWSET(BULK ...) 外部表都允许使用 T-SQL 查询外部数据,但它们专为不同的用例而设计。 下表总结了有助于确定哪种方法适合你的方案的关键差异。
| 能力 | OPENROWSET(BULK ...) |
外部表 |
|---|---|---|
| Purpose | 即席探索和一次性查询 | 持久、可重用的表定义 |
| 存储在数据库中的元数据 | 否。 查询运行后不会保存任何内容 | 是的。 表定义、数据源和文件格式存储为数据库对象 |
| 架构定义 | 从文件(Parquet)自动推断或通过WITH子句进行内联指定 |
显式地在语句 CREATE EXTERNAL TABLE 中定义 |
| 权限 | 需要 ADMINISTER BULK OPERATIONS 或 ADMINISTER DATABASE BULK OPERATIONS |
创建后,对表的标准 SELECT 权限就足够了 |
| 计算列 | 是的。 在 SELECT 列表中添加表达式和计算列;元数据函数(如 filename() 和 filepath() 此处仅可用)。 |
否。 固定列列表;在读取外部表的视图或查询中执行转换 |
| 统计 | Azure SQL:通过sys.sp_create_openrowset_statistics 手动创建单列统计信息;SQL Server 2022(16.x)及更高版本:自动为谓词创建统计信息(SQL Server 不支持手动创建统计信息)。 请参阅 OPENROWSET 手动统计信息。 |
在所有平台上提供全面 CREATE STATISTICS 支持,同时在 SQL Server 2022(16.x)及更高版本中实现自动创建。 请参阅 「创建外部表手动统计信息」。 |
| 下推 | 有限的支持。 引擎可能会将过滤器下推到文件扫描,但不支持下推到远程 RDBMS 源 | 是的。 支持 RDBMS 连接器的下推计算(SQL Server、Oracle、Teradata、MongoDB) |
| 最适用于 | 数据探索、架构发现、原型查询、一次性数据加载、灵活转换 | 生产工作负荷、重复查询、跨用户、仪表板和报告共享访问权限 |
需要灵活性时使用 OPENROWSET
用于 OPENROWSET 浏览文件、测试不同的架构或添加计算列和转换,而无需创建任何持久性对象。 例如,可以将文件路径提取为列、内联转换数据类型,或筛选单个查询中的计算表达式。
此示例查询包括计算列和转换:
SELECT result.filename() AS [FileName],
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
CAST (OrderDate AS DATE) AS OrderDate,
Amount,
OrderDate
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025';
小窍门
Azure SQL 数据库、Azure SQL 托管实例和 SQL Server 2022(16.x)及更高版本中提供了这些 filepath() 和 filename() 函数。 它们允许您过滤文件路径的各个部分(分区消除),并将源文件名称作为一列公开,而这在外部表中是无法直接做到的。
需要持久性和治理时使用外部表
当多个用户或应用程序需要重复查询相同的外部数据时,请使用外部表。 定义架构、数据源和凭据一次,并将其存储在数据库中。 使用者只需 SELECT 对表具有权限。
外部表还支持 统计信息,查询优化器使用该统计信息来生成更好的执行计划。 可以手动创建统计信息,或者让引擎自动创建统计信息(SQL Server 2022 (16.x) 及更高版本)。
此示例查询为更好的查询计划创建外部表的统计信息。
CREATE STATISTICS Stats_OrderDate
ON dbo.SalesExternal(OrderDate)
WITH FULLSCAN;
有关这两种方法的统计信息的详细信息,请参阅 PolyBase 性能注意事项 - 统计信息。
BULK INSERT 与 OPENROWSET(BULK):我应该使用哪一个?
两个BULK INSERT和OPENROWSET(BULK ...)都使用相同的基础大容量加载引擎将数据从文件导入到SQL Server。 但是,它们在语法、灵活性和可以对结果执行的操作方面有所不同。 下表对主要差异进行了汇总:
注释
BULK INSERT 在 Fabric 中的 SQL 数据库中不可用。 对于 Fabric,请对 OneLake 使用 OPENROWSET(BULK ...) 。
| 能力 | BULK INSERT |
OPENROWSET(BULK ...) |
|---|---|---|
| 基本用途 | 将数据直接从文件加载到 目标表中 | 返回由行集,这行集您可以在SELECT或INSERT ... SELECT语句中使用 |
| 使用模式 | 独立语句: BULK INSERT <table> FROM '<file>' |
必须在查询中使用: SELECT * FROM OPENROWSET(BULK ...)INSERT INTO <table> SELECT * FROM OPENROWSET(BULK ...) |
| 需要目标表? | 是的。 始终直接写入数据表 | 否。 您可以从中SELECT,无需插入到任何位置,也可以插入到任何表或临时表中。 |
| 加载期间的列转换 | 有限的支持。 数据直接从文件流向表(映射由格式文件或列顺序控制) | 完全支持。 您可以在 SELECT 中添加表达式、CAST、WHERE 筛选器、JOIN 其他表和计算列。 |
| 表格提示 | 该WITH子句包括对BATCHSIZE、CHECK_CONSTRAINTS、FIRE_TRIGGERS、KEEPIDENTITY、KEEPNULLS、TABLOCK等内容的支持,以及更多。 |
支持通过 INSERT ... SELECT * FROM OPENROWSET(BULK ...) WITH (TABLOCK, IGNORE_CONSTRAINTS, ...) 语法来提供表提示 |
| 大型对象 (LOB) 单值导入 | 不支持 | 是的。 支持SINGLE_BLOB、SINGLE_CLOB、SINGLE_NCLOB将整个文件导入为一个 varbinary(max)、 varchar(max)或 nvarchar(max)值 |
| 格式化文件 | 是的。 支持通过 (XML 和非 XML) | 是的。 支持 (XML 和非 XML) |
| 云文件访问 (Azure Blob 存储、ADLS Gen2、S3) | 是的。 支持通过 DATA_SOURCE 参数 (SQL Server 2017 (14.x) 及更高版本 Azure SQL) |
是的。 支持通过 DATA_SOURCE 参数或内联 URL 和 FORMAT 子句 (SQL Server 2022 (16.x) 及更高版本 Azure SQL) |
| Parquet 或 Delta 文件 | 不支持。 仅限于 CSV/分隔符文本 | 是的。 支持 FORMAT = 'PARQUET' 或 FORMAT = 'DELTA' (SQL Server 2022 (16.x) 及更高版本(Azure SQL) |
| 所需权限 |
ADMINISTER BULK OPERATIONS或者ADMINISTER DATABASE BULK OPERATIONS,在目标表上加INSERT |
ADMINISTER BULK OPERATIONS 或 ADMINISTER DATABASE BULK OPERATIONS |
| 最小日志记录 | 是的。 在简单或大容量日志恢复模式下,支持使用TABLOCK |
是的。 在与 INSERT ... SELECT 和 TABLOCK 一起使用时受支持 |
何时选择 BULK INSERT
当您需要进行简单的文件到表加载时,并且在导入过程中不需要转换、筛选或联接数据,请使用BULK INSERT。 它对 CSV 或其他带分隔符的文件使用更简单的语法:
此示例查询将 CSV 文件直接从 Azure Blob 存储加载到表中。
BULK INSERT Sales.Invoices
FROM 'invoices/inv-2025-01.csv'
WITH (
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
);
此示例查询加载本地文件,并使用格式文件进行列映射。
BULK INSERT dbo.Products
FROM 'C:\Data\products.csv'
WITH (
FORMATFILE = 'C:\Data\products.fmt',
FIRSTROW = 2,
TABLOCK
);
何时选择 OPENROWSET(BULK)
需要以下一个或多个条件时使用 OPENROWSET(BULK ...) :
- 无需先创建表即可查询或预览文件数据。
- 在导入过程中转换、筛选或联接数据。
-
加载 Parquet 或 Delta 文件(仅
OPENROWSET支持这些格式)。 -
将整个文件导入为单个 LOB 值 (
SINGLE_BLOB, ,SINGLE_CLOBSINGLE_NCLOB)。
此示例查询从 Azure Blob 存储预览 CSV 文件,而无需在任意位置插入数据。
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ','
) AS src;
此示例查询使用转换和筛选插入数据。
INSERT INTO Sales.Invoices (InvoiceDate, Amount, Customer)
SELECT CAST (InvoiceDate AS DATE),
Amount * 1.1, -- Apply a 10% markup
UPPER(Customer)
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2
) WITH (
InvoiceDate VARCHAR (10),
Amount DECIMAL (18, 2),
Customer VARCHAR (100)
) AS src
WHERE Amount IS NOT NULL;
此示例查询加载 Parquet 文件(不能使用BULK INSERT)。
INSERT INTO Sales.Invoices
SELECT *
FROM OPENROWSET (
BULK 'data/invoices/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET') AS src;
此示例查询将整个 XML 文件导入为单个 varbinary(max) 值。
INSERT INTO dbo.XmlDocuments (DocContent)
SELECT BulkColumn
FROM OPENROWSET (
BULK 'C:\Data\catalog.xml',
SINGLE_BLOB
) AS x;
小窍门
一种方法是首先在OPENROWSET(BULK ...)SELECT中探讨和验证文件数据,如果不需要转换,则切换到BULK INSERT进行最终生产负载。 如果需要 Parquet 或 Delta 支持或内联筛选,请保持使用OPENROWSET。
有关详细信息,请参阅以下相关指南:
- 使用 BULK INSERT 或 OPENROWSET(BULK...)将数据导入 SQL Server:包含安全注意事项的详细对比指南。
-
批量导入和导出数据(SQL Server):所有大容量数据移动方法(bcp、、
BULK INSERT)OPENROWSET的概述。 - BULK INSERT (Transact-SQL):完整的 T-SQL 参考。
- OPENROWSET BULK (Transact-SQL):完整的 T-SQL 参考。
- 批量访问 Azure Blob 存储中的数据的示例:将这两种方法与 Azure 存储配合使用的并行示例。
-
使用 OPENROWSET 大容量行集提供程序(SQL Server)批量导入大型对象数据:
SINGLE_BLOB和SINGLE_CLOBSINGLE_NCLOB示例。 - 使用格式化文件批量导入数据(SQL Server):使用这两种方法格式化文件使用情况。
有用的元数据函数
当你使用OPENROWSET或外部表查询外部文件时,可以使用多个内置函数和过程来检查文件元数据、发现架构并实现分区感知查询。
filepath() 和 filename()
filepath()和filename()函数返回结果集中每一行的文件路径或文件名的部分。 它们特别适用于:
分区消除:筛选文件夹段(例如年/月/日分区),以便引擎仅读取匹配的文件,而不是扫描所有内容。
公开源元数据:将原始文件名或路径作为列包含在查询结果中,这有助于审核或调试。
| 功能 | 退货 | 示例 |
|---|---|---|
filename() |
每个行的源文件的文件名(包括扩展名) | sales_2025_01.parquet |
filepath(N) |
路径中通配符 () 中的*BULK个文件夹段,其中 N 从 1 开始 |
对于路径 sales/2025/01/*.parquet, filepath(1) 返回 2025, filepath(2) 返回 01 |
适用于:Azure SQL 数据库、Azure SQL 托管实例、SQL Server 2022(16.x)及更高版本(Fabric 中的 SQL 数据库)。
此示例查询用于 filepath() 分区消除和 filename() 标识源文件。 它只读取文件夹下 /2025/ 的文件,并且仅读取子文件夹下 /06/ 的文件。
SELECT result.filename() AS SourceFile,
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
*
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025'
AND result.filepath(2) = '06';
小窍门
将filepath()筛选器放在WHERE子句中,而不是放在子查询或 CTE 中。 当筛选器位于 WHERE 子句中时,查询引擎可以在文件扫描级别进行分区消除,从而大大减少输入/输出操作。
sp_describe_first_result_set - 识别 OPENROWSET 列类型
与 Parquet 文件一起使用 OPENROWSET 时,引擎会自动推断列数据类型(架构推理)。 推断的类型可能大于所需。 例如,字符列通常被推断为 varchar(8000), 因为 Parquet 元数据不包含最大长度。 此选项可能会降低性能并消耗更多内存。
使用 sp_describe_first_result_set 在最终确定查询 之前 检查推断的架构。 看到推断的类型后,请在子句中 WITH 指定更窄的类型以提高性能。
步骤 1:检查推断的架构。
EXECUTE sp_describe_first_result_set N' SELECT * FROM OPENROWSET( BULK ''abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet'', FORMAT = ''PARQUET'' ) AS result';输出显示每个列的名称、推断的数据类型、最大长度、精度和小数位。 如果看到 varchar(8000) 而 varchar(100) 已经足够,请将其覆盖:
步骤 2:使用显式类型来提高性能。
SELECT TOP 100 * FROM OPENROWSET ( BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet', FORMAT = 'PARQUET' ) WITH ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer VARCHAR (100) -- much narrower than the inferred varchar(8000) ) AS result;
模式推断仅适用于 Parquet 文件。 对于 CSV 文件,始终在 WITH 子句(用于 OPENROWSET)或 CREATE EXTERNAL TABLE 语句中指定列定义。
sp_describe_first_result_set 是一般 SQL Server 和 Azure SQL 过程,但对于 OPENROWSET 查询尤其有用。 有关更多信息,请参阅 sp_describe_first_result_set。
性能、故障排除和最佳做法
实现数据虚拟化后,请使用以下指南优化性能、诊断问题并确保生产就绪性:
| 面积 | 文章 | 详细信息 |
|---|---|---|
| PolyBase 性能 | SQL Server 的 PolyBase 中的性能注意事项 | 统计信息、下推、并行度和内存管理 |
| 下推计算 | PolyBase 中的下推计算 | 指定哪些操作推送到远程源 |
| 如何判断是否发生了下推 | 如何判断是否发生了外推 | 查询计划和动态管理视图 |
| 故障排除 | 监视 PolyBase 并对其进行故障排除 | 常见错误和解决方案 |
| Kerberos 连接 | PolyBase Kerberos 连接故障排除 | |
| 常见问题 | PolyBase 常见问题解答 | |
| 错误和解决方案 | PolyBase 错误和可能的解决方案 |