适用于:![]() SQL Server
SQL Server ![]() Azure SQL 数据库
Azure SQL 数据库 ![]() Azure SQL 托管实例
Azure SQL 托管实例 ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW) ![]() Microsoft Fabric SQL 数据库
Microsoft Fabric SQL 数据库
每个 SQL Server 数据库都有事务日志,用于记录所有事务以及每个事务所做的数据库修改。 事务日志是数据库的关键组件,如果系统出现故障,则可能需要使用事务日志将数据库恢复到一致状态。 本指南提供有关事务日志的物理和逻辑体系结构的信息。 了解该体系结构可以提高你在管理事务日志时的效率。
事务日志逻辑体系结构
SQL Server 事务日志按逻辑运行,就好像事务日志是一串日志记录一样。 每条日志记录由一个日志序列号 (LSN) 标识。 每条新日志记录均写入日志的逻辑结尾处,并使用一个比前面记录的 LSN 更高的 LSN。 日志记录按创建的串行序列存储:如果 LSN2 大于 LSN1,则 LSN2 所标识的日志记录描述的更改发生在日志记录 LSN1 描述的更改之后。 每条日志记录都包含其所属事务的 ID。 对于每个事务,与事务相关联的所有日志记录通过使用可提高事务回滚速度的向后指针挨个链接在一个链中。
LSN 的基本结构是 [VLF ID:Log Block ID:Log Record ID]。 有关详细信息,请参阅 VLF 和日志块部分。
下面是 LSN 的示例:00000031:00000da0:0001,其中 0x31 是 VLF 的 ID,0xda0 是日志块 ID,0x1 是该日志块中的第一条日志记录。 有关 LSN 的示例,请查看 sys.dm_db_log_info DMV 的输出并检查 vlf_create_lsn 列。
数据修改的日志记录会记录所执行的逻辑操作,或者记录已修改数据的前像和后像。 前像是执行操作前的数据副本;后像是执行操作后的数据副本。
操作的恢复步骤取决于日志记录的类型:
记录逻辑操作
- 要前滚逻辑操作,请再次执行该操作。
- 要回滚逻辑操作,请执行相反的逻辑操作。
记录前像和后像
- 要前滚操作,请应用后像。
- 要回滚操作,请应用前像。
许多类型的操作都记录在事务日志中。 这些操作包括:
每个事务的开始和结束。
每次数据修改(插入、更新或删除)。 修改包括系统存储过程或数据定义语言 (DDL) 语句对包括系统表在内的任何表所做的更改。
每次分配或释放区和页。
创建或删除表或索引。
回滚操作也记录在日志中。 每个事务都在事务日志中保留空间,以确保存在足够的日志空间来支持由显式回滚语句或遇到错误引起的回滚。 保留的空间量取决于在事务中执行的操作,但通常等于用于记录每个操作的空间量。 事务完成后将释放此保留空间。
日志文件中从必须存在以确保数据库范围内成功回滚的第一条日志记录到最后写入的日志记录之间的部分称为日志的活动部分,即“活动日志”或“日志尾部”。 这是进行数据库完整恢复所需的日志部分。 永远不能截断活动日志的任何部分。 这个第一个日志记录的日志序列号 (LSN),称为最小恢复 LSN (MinLSN)。 有关事务日志支持的操作的详细信息,请参阅事务日志。
差异和日志备份将还原的数据库推到稍后的时间,该时间与一个更高的 LSN 相对应。
事务日志物理体系结构
数据库事务日志映射在一个或多个物理文件上。 从概念上讲,日志文件是一系列日志记录。 从物理上讲,日志记录序列被有效地存储在实现事务日志的物理文件集中。 每个数据库必须至少有一个日志文件。
虚拟日志文件 (VLF)
SQL Server 数据库引擎在内部将每个物理日志文件分成多个虚拟日志文件 (VLF)。 虚拟日志文件没有固定大小,且物理日志文件所包含的虚拟日志文件数不固定。 数据库引擎在创建或扩展日志文件时动态选择虚拟日志文件的大小。 数据库引擎会尝试维护一些虚拟文件。 在扩展日志文件后,虚拟文件的大小是现有日志大小和新文件增量大小之和。 管理员不能配置或设置虚拟日志文件的大小或数量。
创建虚拟日志文件
虚拟日志文件 (VLF) 的创建遵循此方法:
- 在 SQL Server 2014 (12.x) 及更高版本中,如果下一次增长少于当前日志物理大小的 1/8,则创建 1 个 VLF,补偿此增长大小。
- 如果下一次增长超过当前日志大小的 1/8,则使用 pre-2014 方法,即:
- 如果增长少于 64 MB,则创建 4 个 VLF,补偿此增长大小(例如,增长 1 MB,创建 4 个 256 KB 的 VLF)。
- 在 Azure SQL 数据库中,从 SQL Server 2022 (16.x)(所有版本)开始,逻辑略有不同。 如果增长小于或等于 64 MB,则数据库引擎只创建一个 VLF 来补偿此增长大小。
- 如果增长来自 64 MB(最多 1 GB),则创建 8 个 VLF,补偿此增长大小(例如,增长 512 MB,创建 8 个 64 MB 的 VLF)。
- 如果增长大于 1 GB,则创建 16 个 VLF,补偿此增长大小(例如,增长 8 GB,创建 16 个 512 MB 的 VLF)。
- 如果增长少于 64 MB,则创建 4 个 VLF,补偿此增长大小(例如,增长 1 MB,创建 4 个 256 KB 的 VLF)。
如果这些日志文件由于许多微小增量而增长到很大,则它们将具有很多虚拟日志文件。 这会降低数据库启动、日志备份和还原操作的速度,并导致事务副本 (replica)tion/CDC 和 Always On 重做延迟。 相反,如果日志文件设置得较大,但只有少量或仅一个增量,则它们将只包含几个非常大的虚拟日志文件。 有关如何正确估计事务日志的所需大小和自动增长设置的详细信息,请参阅管理事务日志文件的大小的“建议”部分。
建议你使用实现最佳 VLF 分发所需的增量来创建接近所需最终大小的日志文件,并具有相对较大的 growth_increment 值。
请参阅以下提示,确定当前事务日志大小的最佳 VLF 分发:
ALTER DATABASE的SIZE参数设置的大小值是指日志文件的初始大小。ALTER DATABASE的FILEGROWTH参数设置的 growth_increment 值(也称为自动增长值)是指每次需要新空间时添加到文件的空间大小。
有关 ALTER DATABASE 的 FILEGROWTH 和 SIZE 参数的详细信息,请参阅 ALTER DATABASE (Transact-SQL) 文件和文件组选项。
提示
要确定给定实例中所有数据库的当前事务日志大小的最佳 VLF 分发,以及实现所需大小需要的增长量,请参阅 GitHub 上的 Fixing-VLF 脚本。
如果 VLF 太多,会发生什么情况?
在数据库恢复过程的初始阶段,SQL Server 会发现所有事务日志文件中的所有 VLF,并生成这些 VLF 的列表。 此过程可能需要很长时间,具体取决于特定数据库中存在的 VLF 数量。 VLF 越多,过程越长。 如果遇到频繁的事务日志自动增长或小增量手动增长,数据库最终可能会出现大量 VLF。 当 VLF 数量达到数十万的范围时,你可能会遇到以下部分或大部分症状:
- 在 SQL Server 启动期间,一个或多个数据库需要很长时间才能完成恢复。
- 还原数据库需要很长时间才能完成。
- 尝试附加数据库需要很长时间才能完成。
- 尝试设置数据库镜像时,遇到错误消息 1413、1443 和 1479,表示超时。
- 尝试还原数据库时,遇到与内存相关的错误,如 701。
- 事务复制或变更数据捕获可能会出现明显延迟。
检查 SQL Server 错误日志时,你可能会注意到在数据库恢复过程的分析阶段之前花费了大量时间。 例如:
2022-05-08 14:42:38.65 spid22s Starting up database 'lot_of_vlfs'.
2022-05-08 14:46:04.76 spid22s Analysis of database 'lot_of_vlfs' (16) is 0% complete (approximately 0 seconds remain). Phase 1 of 3. This is an informational message only. No user action is required.
此外,在还原具有大量 VLF 的数据库时,SQL Server 还会记录 MSSQLSERVER_9017 错误:
Database %ls has more than %d virtual log files which is excessive. Too many virtual log files can cause long startup and backup times. Consider shrinking the log and using a different growth increment to reduce the number of virtual log files.
有关详细信息,请参阅 MSSQLSERVER_9017。
修复包含大量 VLF 的数据库
要将 VLF 总数保持在合理的数量(例如最多几千个),可以通过执行以下步骤来重置事务日志文件以包含少量的 VLF:
手动收缩事务日志文件。
使用以下 T-SQL 脚本在一个步骤中手动将文件增长到所需的大小:
ALTER DATABASE <database name> MODIFY FILE (NAME='Logical file name of transaction log', SIZE = <required size>);注意
你也可以使用数据库属性页在 SQL Server Management Studio 中执行此步骤。
使用更少的 VLF 设置事务日志文件的新布局后,查看并对事务日志的自动增长设置进行必要的更改。 此设置验证可确保日志文件将来避免遇到相同问题。
在执行上述任何操作之前,确保你具有有效的可还原备份,以防以后遇到问题。
要确定给定实例中所有数据库的当前事务日志大小的最佳 VLF 分发,以及实现所需大小需要的增长量,你可以使用以下 GitHub 脚本来修复 VLF。
日志块
每个 VLF 都包含一个或多个日志块。 每个日志块都包含日志记录(在 4 字节边界处对齐)。 日志块的大小可变,且始终是 512 个字节的整数倍数(SQL Server 支持的最小扇区大小),最大大小为 60 KB。 日志块是用于事务日志记录的 I/O 的基本单位。
总之,日志块是日志记录容器,在将日志记录写入磁盘时用作事务日志记录的基本单位。
VLF 中的每个日志块都通过块偏移量唯一寻址。 第一个块始终具有一个块偏移量,该偏移量指向 VLF 中的前 8 KB。
通常,VLF 始终填满日志块。 VLF 中的最后一个日志块可能为空(例如,不包含任何日志记录)。 如果要写入的日志记录不适合当前日志块,且 VLF 上剩余的空间不足以保存此日志记录,则会发生这种情况。 在这种情况下,将创建一个可填充 VLF 的空日志块。 日志记录将插入到下一个 VLF 上的第一个块。
事务日志的循环性质
事务日志是一种回绕的文件。 例如,假设有一个数据库,它包含一个分成四个 VLF 的物理日志文件。 当创建数据库时,逻辑日志文件从物理日志文件的始端开始。 新日志记录被添加到逻辑日志的末端,然后向物理日志的末端扩张。 日志截断将释放记录全部在最小恢复日志序列号 (MinLSN) 之前出现的所有虚拟日志。 MinLSN 是成功进行数据库范围内回滚所需的最早日志记录的日志序列号。 示例数据库中的事务日志的外观与下图所示相似。
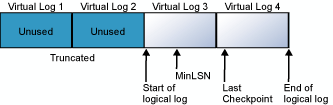
当逻辑日志的末端到达物理日志文件的末端时,新的日志记录将回绕到物理日志文件的始端。
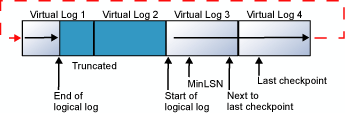
这个循环不断重复,只要逻辑日志的末端不到达逻辑日志的始端。 如果经常截断旧的日志记录,始终为到下一个检查点前创建的所有新日志记录保留足够的空间,则日志永远不会填满。 但是,如果逻辑日志的末端真的到达了逻辑日志的始端,将发生以下两种情况之一:
如果对日志启用了
FILEGROWTH设置且磁盘上有可用空间,则文件按 growth_increment 参数指定的数量增大,并且新的日志记录将添加到扩展。 有关FILEGROWTH设置的详细信息,请参阅 ALTER DATABASE (Transact-SQL) 文件和文件组选项。如果未启用
FILEGROWTH设置,或保存日志文件的磁盘的可用空间比 growth_increment 中指定的数量少,则会出现 9002 错误。 有关详细信息,请参阅解决事务日志已满的问题(SQL Server 错误 9002)。
如果日志包含多个物理日志文件,则逻辑日志在回绕到首个物理日志文件始端之前,将沿着所有物理日志文件移动。
重要
有关事务日志大小管理的详细信息,请参阅管理事务日志文件的大小。
日志截断
日志截断主要用于阻止日志填充。 日志截断从 SQL Server 数据库的逻辑事务日志中删除非活动的虚拟日志文件,释放逻辑日志中的空间以便物理事务日志重用这些空间。 如果事务日志从不截断,它最终将填满分配给物理日志文件的所有磁盘空间。 但是,在截断日志前,必须执行检查点操作。 检查点将当前内存中已修改的页(称为“脏页”)和事务日志信息从内存写入磁盘。 执行检查点时,事务日志的不活动部分将标记为可重用。 此后,日志截断可以释放非活动部分。 有关检查点的详细信息,请参阅数据库检查点 (SQL Server)。
下列各图显示了截断前后的事务日志。 第一个图显示了从未截断的事务日志。 当前,逻辑日志使用四个虚拟日志文件。 逻辑日志开始于第一个逻辑日志文件的前面,并结束于虚拟日志 4。 MinLSN 记录位于虚拟日志 3 中。 虚拟日志 1 和虚拟日志 2 仅包含不活动的日志记录。 这些记录可以截断。 虚拟日志 5 仍未使用,不属于当前逻辑日志。
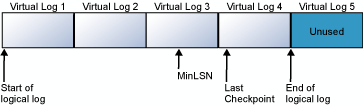
第二个图显示了日志截断后的情形。 已释放虚拟日志 1 和虚拟日志 2 以供重新使用。 现在,逻辑日志开始于虚拟日志 3 的开头。 虚拟日志 5 仍未使用,它不属于当前逻辑日志。
除非由于某些原因导致延迟,否则将在以下事件后自动发生日志截断:
- 简单恢复模式下,在检查点之后发生。
- 完整恢复模式或大容量日志恢复模式下,在日志备份之后发生(如果自上次备份后出现检查点)。
日志截断可能会由于多种因素而延迟。 如果日志截断延迟的时间较长,则事务日志可能会填满磁盘空间。 有关信息,请参阅可能延迟日志截断的因素和解决事务日志已满的问题(SQL Server 错误 9002)。
预写事务日志
本节说明预写事务日志在将数据修改记录到磁盘的过程中所起的作用。 SQL Server 使用预写日志 (WAL) 算法,这可确保在将关联的日志记录写入磁盘之前不会将数据修改写入磁盘。 这维护了事务的 ACID 属性。
有关 WAL 的详细信息,请参阅 SQL Server I/O 基础知识。
要了解预写日志记录相对于事务日志的工作方式,了解如何将修改的数据写入磁盘很重要。 SQL Server 维护一个缓冲区缓存(也称为缓冲池),在必须检索数据时从其中读取数据页。 在缓冲区缓存中修改页后,不会将其立即写回磁盘;而是将其标记为“脏”。 在将数据页物理写入磁盘之前,可以将其逻辑写入多次。 对于每次逻辑写入,都会在记录修改的日志缓存中插入一条事务日志记录。 在将关联的脏页从缓冲区缓存中删除并写入磁盘之前,必须将这条些日志记录写入磁盘。 检查点进程定期在缓冲区高速缓存中扫描包含来自指定数据库的页的缓冲区,然后将所有脏页写入磁盘。 CHECKPOINT 可创建一个检查点,在该点保证全部脏页都已写入磁盘,从而在以后的恢复过程中节省时间。
将修改后的数据页从高速缓冲存储器写入磁盘的操作称为刷新页。 SQL Server 具有一个逻辑,它可以在写入关联的日志记录前防止刷新脏页。 日志记录将在刷新日志缓冲区时写入磁盘。 只要事务提交或日志缓冲区已满,就会发生这种情况。
事务日志备份
本节介绍了有关如何备份和还原(应用)事务日志的概念。 在完整恢复模式和批量日志恢复模式下,执行例行事务日志备份(“日志备份”)对于恢复数据十分必要。 可以在任何完整备份运行的时候备份日志。 有关恢复模型的详细信息,请参阅 SQL Server 数据库的备份和还原。
在创建第一个日志备份之前,必须先创建完整备份(如数据库备份或一组文件备份中的第一个备份)。 仅使用文件备份还原数据库会较复杂。 因此,建议你尽可能从完整数据库备份开始。 此后,必须定期备份事务日志。 这不仅能最小化工作丢失风险,还有助于事务日志的截断。 通常,事务日志在每次常规日志备份之后截断。
重要
建议经常进行日志备份,其频率应足够支持业务需求,尤其是对损坏的日志存储可能导致的数据丢失的容忍程度。
适当的日志备份频率取决于你对工作丢失风险的容忍程度与所能存储、管理和潜在还原的日志备份数量之间的平衡。 实现恢复策略时,请考虑必需的恢复时间目标 (RTO) 和恢复点目标 (RPO),特别是日志备份频率。 每 15 到 30 分钟进行一次日志备份可能就已足够。 但是如果你的业务要求将工作丢失的风险最小化,请考虑进行更频繁的日志备份。 频繁的日志备份还有增加日志截断频率的优点,其结果是日志文件较小。
要限制需要还原的日志备份的数量,必须定期备份数据。 例如,可以制定这样一个计划:每周进行一次完整数据库备份,每天进行若干次差异数据库备份。
实现恢复策略时,请考虑所需 RTO 和 RPO,尤其是完整和差异的数据库备份频率。
有关事务日志备份的详细信息,请参阅事务日志备份 (SQL Server)。
日志链
日志备份的连续序列称为“日志链”。 日志链从数据库的完整备份开始。 通常,仅当第一次备份数据库时,或者将恢复模式从简单恢复模式切换到完整恢复模式或大容量日志恢复模式之后,才会开始一个新的日志链。 除非在创建完整数据库备份时选择覆盖现有备份集,否则现有的日志链将保持不变。 在该日志链保持不变的情况下,便可从介质集中的任何完整数据库备份还原数据库,然后再还原相应恢复点之前的所有后续日志备份。 恢复点可以是上次日志备份的结尾,也可以是任何日志备份中的特定恢复点。 有关详细信息,请参阅事务日志备份 (SQL Server)。
若要将数据库还原到故障点,必须保证日志链是完整的。 也就是说,事务日志备份的连续序列必须能够延续到故障点。 此日志序列的开始位置取决于你所还原的数据备份类型:数据库备份、部分备份或文件备份。 对于数据库备份或部分备份,日志备份序列必须从数据库备份或部分备份的结尾处开始延续。 对于一组文件备份,日志备份序列必须从整组文件备份的开头开始延续。 有关详细信息,请参阅应用事务日志备份 (SQL Server)。
还原日志备份
还原日志备份将前滚事务日志中记录的更改,使数据库恢复到开始执行日志备份操作时的准确状态。 还原数据库时,必须还原在所还原完整数据库备份之后创建的日志备份,或者从你还原的第一个文件备份的开始处进行还原。 通常情况下,在还原最新数据或差异备份后,必须还原一系列日志备份直到到达恢复点。 然后恢复数据库。 这将回滚所有在恢复开始时未完成的事务并使数据库联机。 恢复数据库后,不能再还原任何备份。 有关详细信息,请参阅应用事务日志备份 (SQL Server)。
检查点和日志的活动部分
检查点将脏数据页从当前数据库的缓冲区高速缓存刷新到磁盘上。 这最大限度地减少了数据库完整恢复时必须处理的活动日志部分。 在完整恢复时,需执行下列操作:
- 前滚系统停止之前尚未刷新到磁盘上的日志记录修改信息。
- 回滚与未完成的事务(如没有 COMMIT 或 ROLLBACK 日志记录的事务)关联的所有修改。
检查点操作
检查点在数据库中执行下列过程:
将记录写入标记检查点起点的日志文件。
将为检查点记录的信息存储在检查点日志记录链内。
检查点中记录的一条信息是第一条日志记录的日志序列号 (LSN),该 LSN 必须存在才能进行成功的数据库范围的回滚。 该 LSN 称为“最小恢复 LSN”(“MinLSN”)。 MinLSN 是下列各项中的最小者:
- 检查点起点的 LSN。
- 最早的活动事务起点的 LSN。
- 尚未传递给分发数据库的最早的复制事务起点的 LSN。
检查点记录还包含所有已修改数据库的活动事务的列表。
如果数据库使用简单恢复模式,则标记在 MinLSN 前重用的空间。
将所有脏日志和数据页写入磁盘。
将标记检查点结束的记录写入日志文件。
将这条链起点的 LSN 写入数据库引导页。
导致检查点的活动
下列情况下将出现检查点:
- 显式执行 CHECKPOINT 语句。 用于连接的当前数据库中出现检查点。
- 在数据库中执行了最小日志记录操作,例如,在使用大容量日志恢复模式的数据库中执行大容量复制操作。
- 已经使用 ALTER DATABASE 添加或删除了数据库文件。
- 通过 SHUTDOWN 语句或通过停止 SQL Server (MSSQLSERVER) 服务停止了 SQL Server 实例。 任一操作都会在 SQL Server 实例的每个数据库中生成一个检查点。
- SQL Server 实例在每个数据库内定期生成自动检查点,以减少实例恢复数据库所需的时间。
- 进行了数据库备份。
- 执行了需要关闭数据库的活动。 当 AUTO_CLOSE 选项为 ON 且与数据库的最后一个用户连接关闭时,可能会发生这种情况。 另一个示例是当进行需要重新启动数据库的数据库选项更改时的情况。
自动检查点
SQL Server 数据库引擎生成自动检查点。 自动检查点之间的间隔基于使用的日志空间量以及自上一个检查点以来经历的时间。 如果只在数据库中进行了很少的修改,自动检查点之间的时间间隔可能变化很大并且很长。 如果修改了大量数据,自动检查点也会经常出现。
使用“恢复间隔”服务器配置选项为服务器实例上的所有数据库计算自动检查点之间的间隔。 此选项指定数据库引擎在系统重新启动时恢复数据库所用的最长时间。 数据库引擎将估计在执行恢复操作期间自己在“恢复间隔”内能够处理多少条日志记录。
自动检查点之间的间隔也取决于恢复模式:
如果数据库使用的是完整恢复模式或批量日志恢复模式,则每当日志记录数达到数据库引擎估计在“恢复间隔”选项中指定的时间内可以处理的数量时,便会生成一个自动检查点。
如果数据库使用的是简单恢复模式,只要日志记录数达到下面两个值中较小的那个值,就会生成自动检查点:
- 日志已满 70%。
- 日志记录数达到数据库引擎估计在“恢复间隔”选项指定的时间内能够处理的记录数。
有关设置恢复间隔的信息,请参阅配置恢复间隔(分钟)(服务器配置选项)。
提示
-k SQL Server 高级设置选项使数据库管理员能够根据某些类型检查点的 I/O 子系统的吞吐量来限制检查点 I/O 行为。 -k 设置选项适用于自动检查点和任何其他未调控的检查点。
如果数据库使用的是简单恢复模式,自动检查点将截断事务日志中没有使用的部分。 但是,如果数据库使用的完整恢复模式或大容量日志恢复模式,自动检查点则不会截断日志。 有关详细信息,请参阅事务日志。
现在,CHECKPOINT 语句提供了一个可选的 checkpoint_duration 参数,它指定完成检查点所需的秒数。 有关详细信息,请参阅 CHECKPOINT。
活动日志
日志文件中从 MinLSN 到最后写入的日志记录这一部分称为日志的活动部分,或者称为活动日志。 这是进行数据库完整恢复所需的日志部分。 永远不能截断活动日志的任何部分。 所有的日志记录都必须从 MinLSN 之前的日志部分截断。
下图显示了具有两个活动事务的结束事务日志的简化版本。 检查点记录已压缩成单个记录。

LSN 148 是事务日志中的最后一条记录。 在处理 LSN 147 处记录的检查点时,Tran 1 已经提交,而 Tran 2 是唯一的活动事务。 这就使 Tran 2 的第一条日志记录成为执行最后一个检查点时处于活动状态的事务的最旧日志记录。 这使 LSN 142(Tran 2 的开始事务记录)成为 MinLSN。
长时间运行的事务
活动日志必须包括所有未提交事务的每一部分。 如果应用程序开始执行一个事务但未提交或回滚,将会阻止数据库引擎推进 MinLSN。 这种情况可能会导致以下两种问题:
- 如果系统在事务执行了许多未提交的修改后关闭,以后重新启动时,恢复阶段所用的时间将比“恢复间隔”选项指定的时间长得多。
- 因为不能截断 MinLSN 之后的日志部分,日志可能变得很大。 即使数据库使用的是简单恢复模式,这种情况也有可能出现,在简单恢复模式下,每次执行自动检查点操作时都会截断事务日志。
使用加速数据库恢复(从 SQL Server 2019 (15.x) 开始和 Azure SQL 数据库中提供的功能)可以避免恢复长时间运行的事务以及本文所述的问题。
复制事务
日志读取器代理监视已为事务复制配置的每个数据库的事务日志,并将已设复制标记的事务从事务日志复制到分发数据库中。 活动日志必须包含标记为要复制但尚未传递给分发数据库的所有事务。 如果不及时复制这些事务,它们可能会阻止截断日志。 有关详细信息,请参阅 事务复制。