在 Service Manager 中,数据仓库中存在的数据可以从各种源进行合并。 它通过 Service Manager 使用预定义和自定义的 Microsoft 联机分析处理 (OLAP) 数据多维数据集呈现。 简言之,Service Manager 中的高级分析包括发布、查看和操作多维数据集数据,通常位于 Microsoft Excel 或 Microsoft SharePoint 中。 Excel 主要用于查看和处理数据。 SharePoint 主要用作发布和共享多维数据集数据的方式。
Service Manager 包含一个 System Center 范围的数据仓库。 因此,Operations Manager、Configuration Manager 和 Service Manager 中的数据可以合并到数据仓库中,可以在其中轻松使用多个数据视图来获取可能需要的任何信息。 这也是一个接口,在这里你可以将数据从你自己的自定义来源(如 SAP 应用程序或第三方人力资源应用程序)放到同一个数据仓库中。 这种合并操作将会创建一个通用数据模型并使你能够进行丰富的分析,从而有助于构建一个在整个信息技术 (IT) 组织中可用于满足所有商业智能和报表需求的数据仓库。
如果你的数据位于通用模型中,则可以处理信息并具有适用于整个企业的通用定义和通用分类。 通过使用诸如 Excel 和 SharePoint 等标准工具来部署 OLAP 数据多维数据集,并从这些多维数据集访问信息可完成此操作。 这将使你的用户能够使用他们已知道的技能。 你可以集中控制业务逻辑的定义。 例如,你可以定义诸如事件解决时间阈值等关键性能指标,以及这些阈值的哪些值为绿色、黄色或红色。 你可以集中控制这些选项并使你的用户能够轻松使用数据,而让通用定义出现在其 Excel 报表或 SharePoint 仪表板中。
关于 Service Manager OLAP 多维数据集
联机分析处理(OLAP)多维数据集是 Service Manager 中的一项功能,它利用现有的数据仓库基础结构,为最终用户提供自助式商业智能能力。
OLAP 多维数据集是一种能够通过快速分析数据来克服关系数据库局限性的数据结构。 多维数据集可显示和汇总大量的数据,同时还向用户提供对任意数据点的可搜索访问。 这样,就可以根据需要汇总、切片和细分数据,以处理与用户感兴趣的领域相关的最广泛的问题。
拥有 OLAP 多维数据集工作知识的软件供应商或信息技术(IT)开发人员可以创建管理包,以定义基于数据仓库基础结构构建的可扩展且可自定义的 OLAP 多维数据集。 这些多维数据集存储在 SQL Server Analysis Services (SSAS) 中 诸如 Excel 和 SQL Server Reporting Services (SSRS) 等自助式商业智能工具可以针对 SSAS 中的这些多维数据集,从多个角度分析数据。
企业用来存储其所有事务和记录的数据库称为联机事务处理 (OLTP) 数据库。 这些数据库通常包含逐条输入的记录,这些记录包含大量信息,可供战略家用来对其业务做出明智决策。 但是,用于存储数据的数据库不是用于分析的数据库。 因此,从这些数据库中检索答案从时间和工作量角度而言成本高昂。 OLAP 数据库是专门设计的数据库,旨在帮助从数据中提取商业智能信息。
可将 OLAP 多维数据集视为数据仓库解决方案的最后一块拼图。 OLAP 多维数据集(也称为多维数据集或超多维数据集)是 SQL Server Analysis Services (SSAS) 中一种使用 OLAP 数据库构建的数据结构,可对数据进行近乎瞬时的分析。 在下图中显示此系统的拓扑。
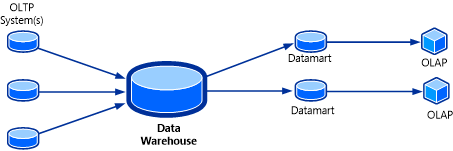
OLAP 多维数据集的有用功能在于能以聚合形式存储多维数据集中的数据。 对于用户来说,立方体似乎已经提前有了问题的答案,因为各种值都已经预先计算好。 无需查询源 OLAP 数据库,数据立方体几乎瞬间就能返回广泛问题的答案。
Service Manager OLAP 多维数据集的主要目标是让软件供应商或信息技术(IT)开发人员能够针对历史分析和趋势目的执行近乎即时的数据分析。 Service Manager 通过以下方式执行此操作:
- 让你能够定义管理包部署完毕后在 SSAS 中自动创建的管理包中的 OLAP 多维数据集。
- 自动维护多维数据集而无需用户干预,执行处理、分区、翻译和本地化及架构更改等任务。
- 让用户能够使用 Excel 等自助服务商业智能工具从多个角度分析数据。
- 保存生成的 Excel 报表以供将来参考。
若要查看数据仓库多维数据集在 Service Manager 控制台中的表示方式,请导航到 数据仓库 工作区,然后选择 “多维数据集”。
Service Manager OLAP 多维数据集
下图显示 SQL Server Business Intelligence Development Studio (BIDS) 中一个用于描述联机分析处理 (OLAP) 多维数据集所需的主要部分的图像。 这些部分为数据源、数据源视图、多维数据集和维度。 下列部分描述 OLAP 多维数据集部分以及用户使用它们可执行的操作。
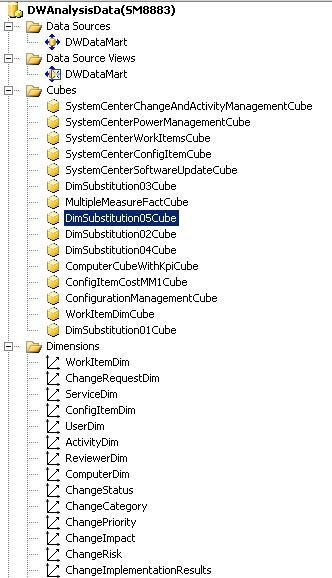
数据源
数据源是指包含在 OLAP 多维数据集中的所有数据的来源。 OLAP 多维数据集连接到数据源,以读取和处理原始数据,为相关指标执行聚合和计算。 所有 Service Manager OLAP 多维数据集的数据源是数据集市,其中包括 Operations Manager 和 Configuration Manager 的数据集市。 有关数据源的身份验证信息必须存储在 SQL Server Analysis Services (SSAS) 中,以便建立正确的权限级别。
数据源视图
数据源视图 (DSV) 是一组视图,用于表示数据源中的维度表、事实表和子维度表,例如 Service Manager 数据集市。 DSV 包含表之间的所有关系,如主键和外键。 换句话说,DSV 指定了 SSAS 数据库将如何映射到关系架构,并且它在关系数据库的顶层提供了一个抽象层。 使用此抽象层,可定义事实数据表与维度表之间的关系,即使源关系数据库中不存在任何关系。 在 DSV 中可以定义命名计算、自定义度量值和新属性,这些可能在数据仓库的维度架构中本身不存在。 例如,定义“已解决事件”布尔值的命名计算会在事件状态为已解决或已关闭时将该值计算为 true。 然后,Service Manager 可以使用命名计算来定义一个度量值,以显示有用的信息,例如已解决的事件百分比、已解决的事件总数和未解决的事件总数。
命名的计算的另一个快速示例为 ReleasesImplementedOnSchedule。 此命名的计算提供对实际结束日期早于或等于计划结束日期的版本记录数的快速运行状况检查。
OLAP 多维数据集
OLAP 多维数据集是一种能够通过快速分析数据来克服关系数据库局限性的数据结构。 OLAP 多维数据集可以显示和汇总大量数据,同时为用户提供对任何数据点的可搜索访问权限,以便根据需要汇总、切片和切切数据,以处理与用户感兴趣的领域相关的最各种问题。
维度
SSAS 中的维度引用 Service Manager 数据仓库中的维度。 在 Service Manager 中,维度大致相当于管理包类。 每个管理包类都具有一个属性列表,而每个维度则都包含一个特性列表,其中每个特性均映射到类中的一个属性。 维度允许对数据进行筛选、分组和标记。 例如,可按安装的操作系统筛选计算机并按性别或年龄对人员进行分组归类。 然后,可以采用一种格式来呈现数据,其中数据自然地分为这些层次结构和类别,以便进行更深入的分析。 维度也可能具有自然层次结构,允许用户“向下钻取”到更详细的详细信息级别。 例如,“日期”维度的层次结构可依次按年、季度、月份、星期和日向下钻取。
下图显示一个包含“日期”、“区域”和“产品”维度的 OLAP 多维数据集。
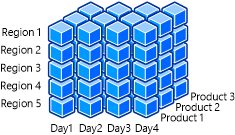
例如,Microsoft团队成员可能需要在适用版本中快速简单地汇总 Xbox One 游戏机的销售情况。 他们可以进一步深入探索,获取更加集中的时间范围内的销售数字。 业务分析师可能希望了解 Xbox One 主机的销售受到新主机设计和 Xbox One Kinect 的影响。 这将有助于其确定销售趋势正在发生什么变化以及可能需要对业务策略进行哪些修订。 通过筛选日期维度,可快速提供和使用此信息。 启用数据切片和分析功能,是因为维度已经被设计得包含客户可以轻松筛选和分组的属性和数据。
在 Service Manager 中,所有 OLAP 多维数据集共享一组通用维度。 所有维度均使用主数据仓库数据市场作为其来源,即使在多种数据市场方案中也是如此。 在多种数据市场方案中,这可能会导致在处理多维数据集的过程中发生维度键错误。
度量值组
度量值组与数据仓库术语中的事实数据是同一概念。 正如事实数据在数据仓库中包含数值度量值一样,度量值组包含 OLAP 多维数据集的度量值。 OLAP 多维数据集中从数据源视图中的单个事实数据表派生的所有度量值也可被视为一个度量组。 不过,可能会有这样的情况:存在多个事实数据表,OLAP 多维数据集中的度量值派生自这些事实数据表。 相同详细信息级别的度量值会被合并到一个度量值组中。 度量值组定义了哪些数据将被加载到系统中,如何加载数据,以及如何将数据绑定到多维数据集。
每个度量值组还包含一个分区列表,其在单独的、非重叠部分中存储有实际数据。 度量值组还包含聚合设计,其定义了为每个度量值组计算的预汇总数据集以提高用户查询的性能。
措施
度量值是用户想要切片、切块、聚合和分析的数值;它们是你希望使用数据仓库基础结构构建 OLAP 多维数据集的根本原因之一。 通过使用 SSAS,您可以构建 OLAP 多维数据集,这些数据集会应用业务规则和计算,以可自定义的格式格式化并显示度量值。 OLAP 多维数据集开发的大部分时间将用于确定和定义需要显示的度量值及其计算方式。
度量值是指那些通常会映射到数据仓库事实数据表中的数值列的值,但它们也可在维度和退化维度属性上进行创建。 这些度量值是 OLAP 多维数据集最为重要的值,它们用于进行分析而且是浏览 OLAP 多维数据集的最终用户最感兴趣的值。 数据仓库中存在的一个度量值示例为 ActivityTotalTimeMeasure。 ActivityTotalTimeMeasure 是 ActivityStatusDurationFact 中一个表示每项活动处于某种状态的时间的度量值。 度量值的详细信息级别由所引用的所有维度构成。 例如, ComputerHostsOperatingSystem 关系事实的详细信息级别由“计算机”和“操作系统”维度构成。
系统将在度量值上计算聚合函数以便能够对数据做进一步分析。 最常用的聚合函数是 Sum 函数。 例如,常见的 OLAP 多维数据集查询对所有 In Progress的活动的总时间进行求和。 其他常用的聚合函数包括 Min、Max 和 Count 等函数。
在 OLAP 多维数据集中处理了原始数据后,用户可使用多维表达式 (MDX) 进行更复杂的计算和查询以定义其自己的度量值表达式或计算成员。 MDX 是查询和访问存储在 OLAP 系统中的数据的行业标准。 SQL Server 未设计为使用多维数据库支持的数据模型。
向下钻取
用户向下钻取 OLAP 多维数据集中的数据时,表示该用户正在以不同的汇总级别分析数据。 数据的详细信息级别会随着用户向下钻取检查层次结构中不同级别的数据而发生变化。 当用户向下钻取时,他们从摘要信息移动到具有更窄焦点的数据。 以下是向下钻取的示例:
- 向下钻取数据以查看关于美国人口的统计信息,然后依次向下钻取数据以查看华盛顿州、西雅图大都市区、雷德蒙德市以及最后微软公司的人口统计信息。
- 向下钻取到 2015 年日历年 Xbox One 主机的销售数据,然后是年度第四季度、12 月、圣诞节前一周,最后是平安夜。
钻取
当用户钻取数据时,他们希望查看构成 OLAP 多维数据集聚合数据的所有单个事务。 换句话说,用户可以在给定度量值的最低详细信息级别检索数据。 例如,当你得到特定月份和产品类别的销售数据时,可以深入挖掘该数据,以查看包含在该数据单元格内的每个表格行的列表。
通常会将术语向下钻取和贯穿钻取相互混淆。 它们之间的主要区别在于,向下钻取是在 OLAP 多维数据集内基于预定义的数据层次结构进行操作的,例如从美国,到华盛顿,再到西雅图。 钻取则直接进入数据的最低详细信息级别并从已被聚合到单个单元格的数据源中检索一组行。
关键绩效指标
组织可以使用关键绩效指标 (KPI) 度量它们朝着其目标的进展情况,从而衡量其企业及其绩效的健康状况。 KPI 是可以定义的业务指标,用于监控朝着特定的预定义目标的进展情况。 KPI 具有目标值和实际值,表示对组织成功至关重要的定量目标。 关键绩效指标 (KPI) 在记分卡上以组的形式展示,以便通过一个简要概览显示企业的整体运营状况。
KPI 的一个示例是要在 48 小时内完成所有更改请求。 KPI 可用于度量该时间范围内解决的更改请求所占的百分比。 你可以创建仪表板,以可视方式表示 KPI。 例如,你可能希望定义 KPI 目标值,以确保 75% 的更改请求在 48 小时内完成。
分区
分区是一种用于保存度量值组中的部分或全部数据的数据结构。 每个度量值组分为多个分区。 一个分区定义了加载到度量值组中的事实数据的一个子集。 SSAS 标准版仅允许每个度量值组有一个分区,而 SSAS 企业版则允许一个度量值组包含多个分区。 分区是最终用户透明的功能,但它们对 OLAP 多维数据集的性能和可伸缩性都有重大影响。 度量值组的所有分区始终存在于同一物理数据库中。
通过分区,管理员可以更好地管理 OLAP 多维数据集并提高 OLAP 多维数据集的性能。 例如,您可以删除或重新处理度量值组中某个分区的数据,而不影响该度量值组的其他部分。 当你将新数据加载到事实数据表时,只有应包含新数据的分区才会受到影响。
分区还可以提高 OLAP 多维数据集的处理和查询性能。 SSAS 可以并行处理多个分区,从而使服务器上的 CPU 和存储资源的使用效率大为提升。 在运行查询时,SSAS 也会从多个分区提取、处理和聚合数据,但仅扫描包含与查询相关的数据的分区,从而减少输入和输出总量。
分区策略的其中一个示例是,将每月的事实数据放在一个月度分区中。 在每月的月末,所有新数据均会流入一个新分区,从而获得无重叠值的数据自然分布。
聚合
OLAP 多维数据集中的聚合是预先汇总的数据集。 它们类似于具有 GROUP BY 子句的 SQL SELECT 语句。 SSAS 在回应查询时可以使用这些聚合,从而减少必需计算量并向用户快速返回答案。 OLAP 多维数据集中的内置聚合可减少 SSAS 在查询时必须执行的聚合量。 生成正确的聚合可以显著提高查询性能。 这通常是整个 OLAP 多维数据集生存期中随查询和使用变化而持续演进的过程。
通常会创建基本聚合集,它对于针对 OLAP 多维数据集的大多数查询都很有用。 在度量值组中,将为 OLAP 多维数据集的每个分区构建聚合。 在聚合构建后,在预先汇总的数据集中会包括维度的特定属性。 用户在浏览 OLAP 多维数据集时可以根据这些聚合快速查询数据。 必须仔细设计聚合,因为可能存在的聚合数很大,以至于构建所有可能存在的聚合将占用非常多的时间和存储空间。
Service Manager 在 Service Manager OLAP 多维数据集中生成和设计聚合时使用以下两个选项:
- 性能提升达到
- 基于使用情况的优化
“性能提升达到”选项定义构建聚合所占的百分比。 例如,将该选项设为默认与建议值 30%,这意味着构建的聚合可使 OLAP 多维数据集获得 30% 的估计性能提升。 但是,这并不意味着 30% 的可能数据聚合将会被构建。
“基于使用情况的优化”使 SSAS 能够记录数据请求,从而在运行查询时,该信息会提供给聚合设计流程。 然后,SSAS 会审阅数据并建议应构建哪些聚合,以带来最佳的估计性能提升。
Service Manager 多维数据集分区
多维数据集中的每个度量值组会被分成多个分区,其中一个分区将定义一部分被加载到度量值组中的事实数据。 SQL Server 上的 SQL Server Analysis Services (SSAS)标准版只允许每个度量值组一个分区,而企业版中允许多个分区。 分区对最终用户是完全透明的,但它们对性能和可扩展性会产生重要的影响。 例如,分区既可以单独处理,也可以并行处理。 它们可以有不同的聚合设计。 你可以重新处理某一分区而不会影响度量值组中的所有其他分区。 此外,SSAS 还将仅自动扫描那些包含查询所需数据的分区,这可以大大地提高查询性能。
默认情况下,系统会按小时对每个数据仓库维护作业运行执行多维数据集分区。 运行的特定进程模块名为 ManageCubePartitions。 它始终在 CreateMartPartitions 步骤之后运行。 此依赖关系数据存储在 infra.moduletriggercondition 表中。
负责处理分区的主要动态链接库 (DLL) 位于 PartitionUtil 类中的仓库实用工具 DLL Microsoft.EnterpriseManagement.Warehouse.Utility 中。 具体而言,类中有一个处理所有分区维护的 ManagePartitions() 方法。 数据仓库维护 DLL Microsoft.EnterpriseManagement.Warehouse.Maintenance 和数据仓库联机分析处理 (OLAP) DLL Microsoft.EnterpriseManagement.Warehouse.Olap 在维护和多维数据集部署期间,都会调用 Microsoft.EnterpriseManagement.Warehouse.Utility 来处理分区。 这就是实际分区处理在公共仓库实用工具 DLL 中进行的原因,这样可避免重复逻辑或代码。
多维数据集分区维护执行下列任务:
- 创建分区
- 删除分区
- 更新分区边界
若要执行此操作,应读取结构化查询语言 (SQL) 表 etl.TablePartition 以确定已为度量值组创建的所有事实分区。 将出现以下操作:
- 为多维数据集中的每个度量值组启动多维数据集处理
- 从度量值组的 etl.TablePartition 表中获取所有分区
- 删除度量值组中存在的所有分区(etl.TablePartition 表中缺少的分区除外)
- 将任何已创建的并且仅存在于 etl.TablePartition 表中的新分区添加进去。
- 通过将各个分区与 etl.TablePartition 表中的 RangeStartDate 和 RangeEndDate 进行匹配来更新任何可能已发生变化的分区
请记住下列关于处理多维数据集的事项:
- 只有以事实为目标的度量值组在 SQL Server 标准版中包含多个分区。 默认情况下,所有度量值组和维度都仅包含一个分区。 因此,分区没有任何边界条件。
- 分区边界由基于日期关键字的查询绑定进行定义,这些关键字与 etl.TablePartition 表中的对应事实分区的日期关键字相符。
Service Manager OLAP 多维数据集部署
联机分析处理(OLAP)多维数据集部署使用 Service Manager 部署基础结构在 SQL Server Analysis Services (SSAS) 数据库中创建 OLAP 多维数据集。
若要进行汇总,可部署的元素会为 Deployer 返回一个资源集合,其中的资源经过序列化并可用于在 SSAS 数据库中创建 OLAP 多维数据集。 对于 OLAP 多维数据集,可部署对象的名称为 CubeDeployable(针对 SystemCenterCube 元素)和 CubeExtensionDeployable(针对 CubeExtension 元素)。 这两个元素的 Deployer 均为 CubeDeployer。
DWStagingAndConfig 数据库中的 dbo.Selector 表包含的条目适用于 SystemCenterCube 和 CubeExtension 这两个管理包元素。 使用 MPSync 作业将管理包导入数据仓库后,如果管理包元素需要进行额外的部署处理,则部署引擎会使用此元数据。
部署将使用分析管理对象 (AMO) 应用程序编程接口 (API) 在 SSAS 数据库中创建和修改所有多维数据集组件。 具体而言,使用断开连接模式下的 AMO,因为 CubeDeployable 元素不会与 SSAS 数据库建立连接。 在断开模式中使用 AMO 使你可以创建 AMO 对象的整个树,而无需建立到服务器的连接。 然后,Service Manager 将对象的层次结构序列化为流资源,并将其附加到传回部署基础结构的部署器对象。 Deployer 对象随后将进行反序列化、建立与 SSAD 数据库的连接,以及通过向服务器发送相应的请求来创建对象。
只有主对象可序列化。 在 AMO 中,主对象被视为以整个实体而非另一个对象的一部分代表整个对象的类。 例如,主要对象包括服务器、多维数据集和维度,它们都是独立实体。 但是,DimensionAttribute 不是主要对象,因为它只能作为 Dimension 父主对象的一部分创建。 因此,DimensionAttribute 是一个次要对象。 OLAP 多维数据集设计注重于创建多维数据集所需的所有主对象,以及任何从属次要对象。 在 SSAS 数据库中创建对象之前,这些主要对象将被序列化,并最终被反序列化。
覆盖主对象的资源必须按特定的顺序创建,部署才能成功完成并满足 OLAP 多维数据集元素的依赖关系要求。 下列两个列表分别阐明了 SystemCenterCube 和 CubeExtension 元素的部署顺序:
- DataSourceView 元素
- 维度元素
- 日期维度元素
- 多维数据集元素
- DataSourceView 元素
- 多维数据集元素
Service Manager OLAP 多维数据集处理
当联机分析处理 (OLAP) 多维数据集已部署且其所有分区已创建后,即可对其进行处理以便查看。 处理多维数据集是提取、转换和加载 (ETL) 运行后的最终步骤。 按如下所述执行这些步骤:
- 提取:从源系统中提取数据
- 转换:应用函数,使数据符合标准维度架构
- 加载:将数据加载到数据市场以供使用
- 过程:将数据从数据集市加载到 OLAP 多维数据集中以供浏览
为多维数据集计算所有聚合以及将这些聚合和数据加载到多维数据集中时会处理 OLAP 多维数据集。 系统会读取维度和事实数据表,同时还会计算数据并将其加载到多维数据集中。 在设计 OLAP 多维数据集时,请务必要慎重考虑处理,因为处理可能会对可能存有数百万条记录的生产环境产生很大的影响。 此类环境中所有分区的完整过程可能需要数天到甚至数周的时间,这可能会使 Service Manager 基础结构和多维数据集对最终用户不可用。 一项建议是禁用任何未使用的多维数据集的处理计划,以减少系统开销。
OLAP 多维数据集处理包括两个独立的任务:
- 维度处理
- 分区处理
每个 OLAP 多维数据集在 Service Manager 控制台中都有相应的处理作业,并在用户可配置的计划上运行。 下列部分中描述了各种类型的处理任务。
维度处理
每当一个新的维度添加到 SQL Server Analysis Server (SSAS) 数据库中时,都必须对该维度运行完整的过程以使之处于完全处理状态。 但是,在处理维度后,无法保证在处理针对同一维度的另一个多维数据集时会再次处理该维度。 通过不自动重新处理维度,可防止 Service Manager 为每个多维数据集重新处理每个维度。 如果最近处理维度,则尤其如此,因为不太可能存在尚未处理的新数据。 为了优化处理效率,在 Microsoft.SystemCenter.Datawarehouse.OLAP.Base 管理包中定义了一个名为 Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval 的单例类。 下面是此类的一个示例:
<!-- This singleton class defines the minimum interval of time in minutes that must elapse before a shared dimension is reprocessed. -->
<ClassType ID="Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval" Accessibility="Public" Abstract="false" Base="AdminItem!System.AdminItem" Singleton="true">
<Property ID="IntervalInMinutes" Type="int" Required="true" DefaultValue="60"/>
</ClassType>
此 Singleton 类包含一个用于描述维度处理频率的属性 IntervalInMinutes。 默认情况下此属性设置为 60 分钟。 例如,如果维度在下午 3:05 处理,而针对同一维度的另一个多维数据集在下午 3:45 处理,则不会重新处理该维度。 这种方法的一个缺陷就是增加了维度键错误发生的可能性。 重试机制负责处理维度键错误,以先重新处理维度,随后处理多维数据集分区。 有关处理失败的详细信息,请参阅“调试和故障排除的常见问题”部分。
一个维度经过完全处理后,将会通过 ProcessUpdate 执行增量处理。 执行 ProcessFull 的唯一其他时间就是当维度架构发生变化时,因为这会导致维度恢复到未处理状态。 请记住,如果对某个维度执行 ProcessFull 操作,则所有受影响的多维数据集及其分区将处于未处理状态,并且必须在下次计划的运行中对其进行完全处理。
分区处理
必须仔细考虑分区处理,因为重新处理大型分区速度较慢,并且它会在托管 SSAS 的服务器上消耗许多 CPU 资源。 分区处理通常都会比维度处理花费更多的时间。 与维度处理不同的是,处理分区不会对其他对象产生任何副作用。 在 System Center - Service Manager OLAP 多维数据集上执行的唯一两种处理类型是 ProcessFull 和 ProcessAdd。
类似于维度,要在 OLAP 多维数据集中创建新分区,必须执行这个分区的 ProcessFull 任务,以使其达到可以被查询的状态。 由于 ProcessFull 任务的运行成本高昂,因此只有在必要时才可执行 ProcessFull 任务;例如,创建分区或行已被更新时。 在已添加行且未更新行的场景中,Service Manager 可以执行 ProcessAdd 任务。 为此,Service Manager 使用水印和其他元数据。 具体来说就是查询 etl.cubepartition 表和 etl.tablepartition 表来确定要执行哪种类型的处理。
下图说明了 Service Manager 如何根据水印数据确定要执行的处理类型。
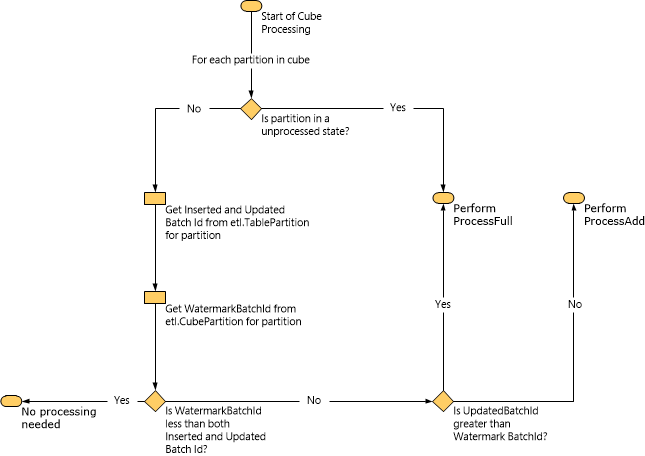
执行 ProcessAdd 任务时,Service Manager 使用水印限制查询的范围。 例如,InsertedBatchId 值为 100 且 WatermarkBatchId 值为 50,则查询将仅从 InsertedBatchId 大于 50 但小于 100 的数据市场中加载数据。
最后,请务必注意,Service Manager 不支持使用 SSAS 或 Business Intelligence Development Studio 手动处理 OLAP 多维数据集。 使用 System Center - Service Manager 提供的方法(包括 Service Manager 控制台和 Service Manager cmdlet)之外的方法处理多维数据集不会更新水印表。 因此,可能会出现数据完整性问题。 如果您意外手动重新处理了多维数据集,一个可能的解决方法是以同样方式手动撤销 OLAP 多维数据集的处理。 然后,下次 Service Manager 处理多维数据集时,它会自动执行 ProcessFull 任务,因为分区将处于未处理状态。 这将会正确地更新所有水印和元数据,因此任何可能的数据完整性问题都将得以解决。
维护 Service Manager OLAP 多维数据集
下列部分中的信息描述了适用于联机分析处理 (OLAP) 多维数据集的最佳维护方案。
定期重新处理 Analysis Services 维度
SQL Server Analysis Services (SSAS) 最佳实践建议应定期全面处理 SSAS 维度。 完全处理维度可重新构建索引并优化多维数据的数据存储,这有助于提升会随着时间推移而逐步降级的查询和多维数据集性能。 这类似于定期对计算机上的硬盘进行碎片整理。
不过,完全处理 SSAS 维度的缺陷在于所有受影响的 OLAP 多维数据集都会变成未处理状态,因此必须同时对这些多维数据集进行完全处理以使其恢复到可查询状态。 Service Manager 不会显式完全处理 SSAS 维度。 因此,你必须确定何时执行此维护任务。
套接字内存注意事项
如果在一台服务器上运行所有的数据仓库提取、转换和加载 (ETL) 操作及 OLAP 多维数据集功能,请仔细考虑操作系统、数据仓库和 SSAS 的内存需求,以确保服务器能够处理可并发运行的所有数据密集型操作。 这一点尤其重要,因为处理 OLAP 多维数据集是一项占用大量内存的操作。