使用文本转语音 API
与 Azure AI 语音转文本 API 类似,Azure AI 语音服务提供其他 REST API 用于语音合成:
- 文本转语音 API,这是执行语音合成的主要方式。
- 批处理合成 API,旨在支持将大量文本转换为音频的批处理操作(例如,从源文本生成音频书籍)。
可以在文本转语音 REST API 文档中详细了解 REST API。 在实践中,大多数启用了语音的交互式应用程序会通过(编程)特定于语言的 SDK 来使用 Azure AI 语音服务。
使用 Azure AI 语音 SDK
与语音识别一样,在实践中,大多数启用了语音的交互式应用程序是通过 Azure AI 语音 SDK 构建的。
用于实现语音合成的模式类似于语音识别的模式:
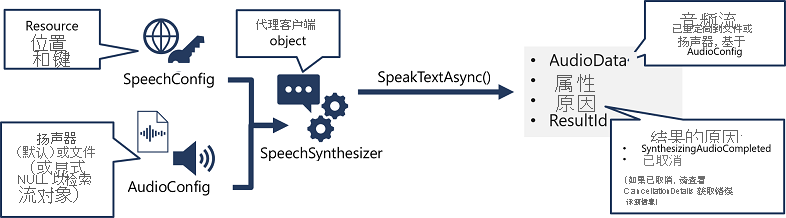
- 使用 SpeechConfig 对象封装连接到 Azure AI 语音资源所需的信息。 具体来说,就是它的位置和键。
- (可选)使用 AudioConfig 为要合成的语音定义输出设备。 默认情况下,这是默认系统扬声器,但也可以指定音频文件,或是通过将此值显式设置为 null 值,可以处理直接返回的音频流对象。
- 使用 SpeechConfig 和 AudioConfig 创建 SpeechSynthesizer 对象。 此对象是文本转语音 API 的代理客户端。
- 使用 SpeechSynthesizer 对象的方法调用基础 API 函数。 例如,SpeakTextAsync() 方法使用 Azure AI 语音服务将文本转换为口述音频。
- 处理来自 Azure AI 语音服务的响应。 如果采用 SpeakTextAsync 方法,则结果为带有以下属性的 SpeechSynthesisResult 对象:
- AudioData
- 属性
- 原因
- ResultId
成功合成语音后,Reason 属性设置为 SynthesizingAudioCompleted 枚举,AudioData 属性包含音频流(根据 AudioConfig,可能已自动发送到扬声器或文件)。