了解性能和安全性
Azure 生态系统为 Azure 虚拟机上的 SQL Server 实例提供了多种性能和安全选项。 每个选项都提供了多种功能,例如满足工作负载的容量和性能要求的不同磁盘类型。
存储注意事项
无论是在本地实例还是安装在 Azure VM 上,SQL Server 都要求有良好的存储性能,这样才能提供可靠的应用程序性能。 Azure 提供了多种存储解决方案来满足你的工作负载的需求。 尽管 Azure 提供多种类型的存储(Blob、文件、队列和表),但在大多数情况下,SQL Server 工作负载将使用 Azure 托管磁盘。 例外情况是,故障转移群集实例可在文件存储上构建,而备份将使用 Blob 存储。 Azure 托管磁盘充当向 Azure VM 提供的块级别存储设备。 托管磁盘提供诸多好处,包括 99.999% 的可用性、可缩放的部署(每个订阅每个区域可具有多个 50,000 个 VM 磁盘),还有与可用性集和可用性区域的集成,在出现故障时提供更高级别的复原能力。
Azure 托管磁盘都提供两种类型的加密。 Azure 服务器端加密由存储服务提供,它充当存储服务提供的静态加密。 Azure 磁盘加密在 Windows 上使用 BitLocker,在 Linux 上使用 DM-Crypt,来在 VM 内部提供 OS 和数据磁盘加密。 这两种技术都与 Azure Key Vault 集成,让你能够自带加密密钥。
每个 VM 将至少有两个与之关联的磁盘:
操作系统磁盘:每个虚拟机都将需要包含引导卷的操作系统磁盘。 如果是 Windows 平台虚拟机,则此磁盘将为 C: 驱动器;而在 Linux 上,它为 /dev/sda1。 操作系统将自动安装到操作系统磁盘上。
临时磁盘:每个虚拟机都将包含一个用于临时存储的磁盘。 此存储旨在用于无需持久化的数据,例如页面文件或交换文件。 由于磁盘是临时的,因此不得用它来存储任何关键信息(例如数据库或事务日志文件),理由是在虚拟机维护或重启期间,这些信息将丢失。 该驱动器作为 D:\ 装载在 Windows 上,作为 /dev/sdb1 装载在 Linux 上。
此外,你可以(也应该)向运行 SQL Server 的 Azure VM 添加额外的数据磁盘。
- 数据磁盘:“数据磁盘”这一术语是在 Azure 门户中使用的,但实际上,它们只是指添加到 VM 的额外托管磁盘。 可使用 Windows 上的存储空间或 Linux 上的逻辑卷管理将这些磁盘放入池中,从而增加可用的 IOPs 和存储容量。
此外,每个磁盘可归入以下几种类型之一:
| 功能 | 超级磁盘 | 高级 SSD | 标准 SSD | 标准 HDD |
|---|---|---|---|---|
| 磁盘类型 | SSD | SSD | SSD | HDD |
| 最适用于 | IO 密集型工作负载 | 性能敏感型工作负载 | 轻型工作负载 | 备份,非关键型工作负载 |
| 最大磁盘大小 | 65,536 GiB | 32,767 GiB | 32,767 GiB | 32,767 GiB |
| 最大吞吐量 | 2,000 MB/秒 | 900 MB/秒 | 750 MB/秒 | 500 MB/秒 |
| 最大 IOPS | 160,000 | 20,000 | 6,000 | 2,000 |
Azure 上的 SQL Server 最佳做法推荐将高级磁盘加入池中来提高 IOPs 和存储容量。 数据文件应在 Azure 磁盘上以读取缓存的方式存储在其自己的池中。
事务日志文件不会从此缓存中受益,因此这些文件应放入其自己的池中,不进行缓存。 TempDB 可选择性地放入其自己的池中,也可使用 VM 的临时磁盘,后者提供低延迟,原因是它物理附加到正在运行 VM 的物理服务器上。 配置恰当的高级 SSD 将实现单位数毫秒级的延迟。 对于需要比这还低的延迟的任务关键型工作负载,应考虑使用超级 SSD。
安全注意事项
Azure 遵守多个行业法规和标准,使你能够使用在虚拟机中运行的 SQL Server 构建合规的解决方案。
Microsoft Defender for SQL
Azure Defender for SQL 支持 Azure 安全中心安全功能,例如漏洞评估和安全警报。
Azure Defender for SQL 可用于识别和缓解SQL Server 实例和数据库中的潜在漏洞。 漏洞评估功能可以检测 SQL Server 环境中的潜在风险,并帮助你缓解这些风险。 你可以通过该功能了解你的安全状态和解决安全问题的可行措施。
Azure 安全中心
Azure 安全中心是一种统一的安全管理系统,可评估和提供改进数据环境的多个安全方面的机会。 Azure 安全中心提供了所有混合云资产的安全运行状况的全面认识。
性能注意事项
Azure 虚拟机 (VM) 上还提供了大多数现有的本地 SQL Server 性能功能。 提供的选项包括数据压缩,该功能可以提高 I/O 密集型工作负载的性能,同时减小数据库的大小。 同样,表和索引分区可以提高大型表的查询性能,同时提高性能和可伸缩性。
表分区
表分区提供了许多好处,但通常只有在表变得足够大而开始影响查询性能时才考虑这种策略。 确定哪些表是表分区的候选表是一种很好的做法,可以减少中断和干预。 使用分区列筛选数据时,仅访问数据的子集,而不是访问整个表。 同样,分区表上的维护操作可缩短维护持续时间,例如,压缩特定分区中的特定数据,或者重新构建索引的特定分区。
定义表分区时需要执行四个主要步骤:
- 创建文件组,定义创建分区时涉及的文件。
- 创建分区功能,根据指定列定义分区规则。
- 创建分区方案,定义每个分区的文件组。
- 要分区的表。
下面的示例演示如何为 2021 年 1 月 1 日至 2021 年 12 月 1 日这一时间段创建分区功能,以及如何在不同文件组之间分布分区。
-- Partition function
CREATE PARTITION FUNCTION PartitionByMonth (datetime2)
AS RANGE RIGHT
-- The boundary values defined is the first day of each month, where the table will be partitioned into 13 partitions
FOR VALUES ('20210101', '20210201', '20210301',
'20210401', '20210501', '20210601', '20210701',
'20210801', '20210901', '20211001', '20211101',
'20211201');
-- The partition scheme below will use the partition function created above, and assign each partition to a specific filegroup.
CREATE PARTITION SCHEME PartitionByMonthSch
AS PARTITION PartitionByMonth
TO (FILEGROUP1, FILEGROUP2, FILEGROUP3, FILEGROUP4,
FILEGROUP5, FILEGROUP6, FILEGROUP7, FILEGROUP8,
FILEGROUP9, FILEGROUP10, FILEGROUP11, FILEGROUP12);
-- Creates a partitioned table called Order that applies PartitionByMonthSch partition scheme to partition the OrderDate column
CREATE TABLE Order ([Id] int PRIMARY KEY, OrderDate datetime2)
ON PartitionByMonthSch (OrderDate) ;
GO
数据压缩
SQL Server 提供用于压缩数据的不同选项。 虽然 SQL Server 仍将压缩的数据存储在 8 KB 页上,但是在压缩数据时,可以在给定页上存储更多数据行,从而使查询读取的页更少。 读取较少的页有两个好处:减少执行的物理 IO 量,并允许在缓冲池中存储更多的行,从而更有效地利用内存。 建议在适当情况下启用数据库页压缩。
压缩的折衷之处在于,它确实只需要少量的 CPU 开销,但是在大多数情况下,存储 IO 的好处远远超过任何其他处理器的使用。
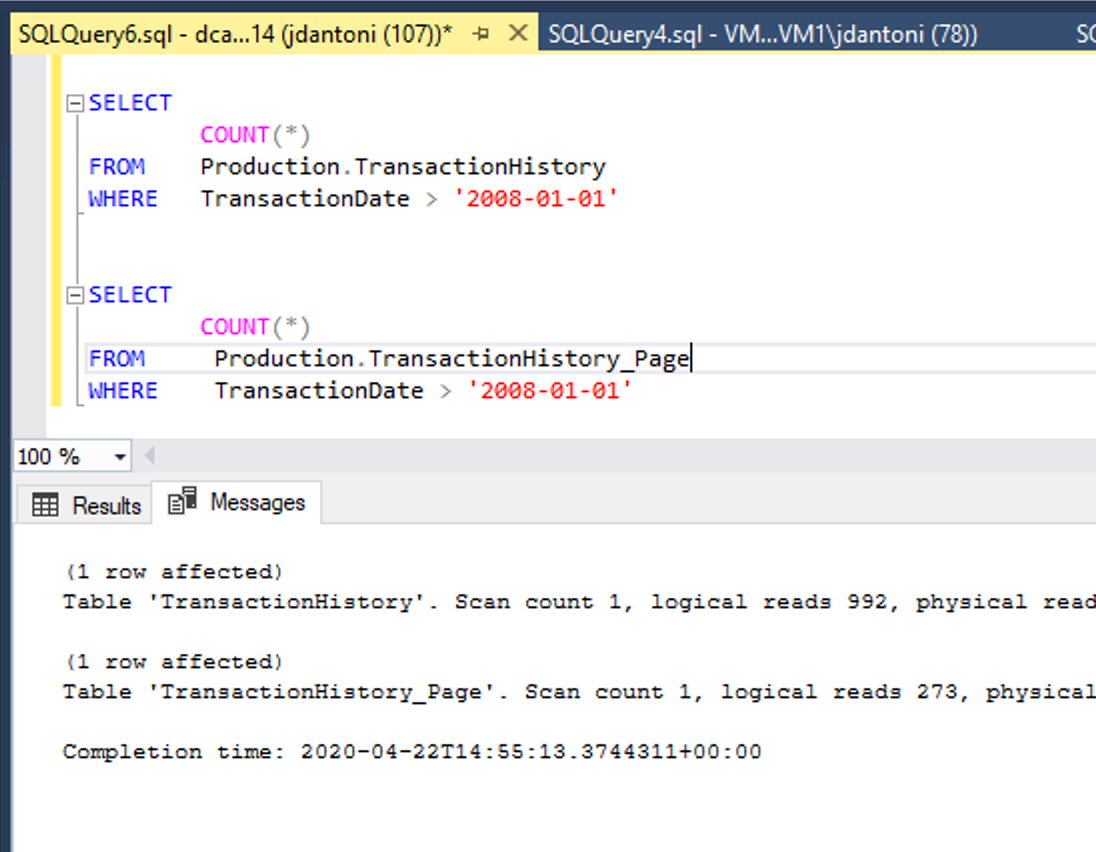
上图显示了这种性能优势。 这些表具有相同的基础索引。唯一的区别在于 Production.TransactionHistory_Page 表上的聚集索引和非聚集索引是页压缩的。 与使用未压缩对象的查询相比,针对页压缩对象的查询执行的逻辑读取要少 72%。
压缩是在 SQL Server 的对象级别上实现的。 每个索引或表都可以单独压缩,可以选择压缩已分区表或索引中的分区。 可以使用 sp_estimate_data_compression_savings 系统存储过程来评估将节省的空间量。 在 SQL Server 2019 之前,此过程不支持列存储索引或列存储存档压缩。
行压缩 - 行压缩是相当基础的,不会产生太多开销。但是,它无法提供与页压缩所能提供的相同的压缩量(通过所需存储空间减少的百分比来衡量)。 行压缩基本上将每列中的每个值存储在存储该值所需的最小空间量的行中。 它对数值数据类型(例如整数、浮点数和十进制)使用可变长度存储格式,并使用可变长度格式存储固定长度的字符串。
页压缩:页压缩是行压缩的超集,因为在应用页压缩之前,所有页将首先进行行压缩。 然后对数据应用一种称为前缀和字典压缩的技术的组合。 前缀压缩可消除单列中的冗余数据,并将指针存储回页眉。 在该步骤之后,字典压缩会搜索页面上重复的值,并将其替换为指针,从而进一步减少存储量。 数据中的冗余越多,压缩数据时节省的空间就越大。
列存储存档压缩:列存储对象始终是压缩的,但是可以使用存档压缩对其进行进一步压缩,存档压缩对数据使用 Microsoft XPRESS 压缩算法。 此类压缩最适用于不经常读取但出于监管或业务原因需要保留的数据。 虽然进一步压缩了这些数据,但解压缩的 CPU 开销往往会超过 IO 减少所带来的所有性能提升。
附加选项
下面的列表包含生产工作负载要考虑的其他 SQL Server 功能和操作:
- 启用备份压缩
- 对数据文件启用即时文件初始化
- 限制数据库自动增长
- 为数据库禁用自动收缩/自动关闭
- 将所有数据库(包括系统数据库)转移到数据磁盘
- 将 SQL Server 错误日志和跟踪文件目录移到数据磁盘
- 设置 SQL Server 最大内存限制
- 启用锁定内存页
- 启用针对 OLTP 繁重环境的临时工作负载优化
- 启用查询存储。
- 计划 SQL Server 代理作业以运行 DBCC CHECKDB、索引重新编制、索引重新生成和更新统计信息作业
- 监视和管理事务日志文件的运行状况和大小
有关性能最佳做法的详细信息,请参阅 Azure VM 上的 SQL Server 的最佳做法。