了解 IaaS 高可用性和灾难恢复解决方案
在 Azure 中,可以为 IaaS 部署多种不同的功能组合。 本部分将介绍 Azure 中 SQL Server 高可用性和灾难恢复 (HADR) 体系结构的五个常见示例。
单区域高可用性示例 1 - Always On 可用性组
如果只需要高可用性而不需要灾难恢复,则无论你在何处使用 SQL Server,配置 AG(可用性组)都是最普遍的方法之一。 下图中的示例描述了一个区域中的 AG 可能是何种形式。
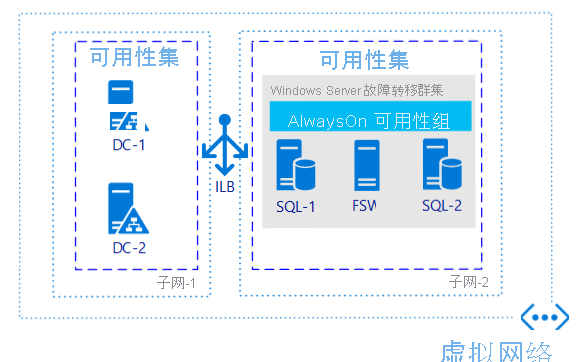
为什么要考虑这种体系结构?
此体系结构通过在不同虚拟机 (VM) 中保存多个副本来保护数据。
如果正确实现,此体系结构可满足恢复时间目标 (RTO) 和恢复点目标 (RPO),同时最大程度减少数据丢失,甚至不会产生数据丢失。
此体系结构提供了一种简单的标准化方法,供应用程序访问主要副本和次要副本(如果要使用只读副本等内容)。
此体系结构可为进行修补提供增强的可用性。
此体系结构不需要共享存储,因此相比使用故障转移群集实例 (FCI),复杂度更低。
单区域高可用性示例 2 - Always On 故障转移群集实例
在引入 AG 之前,FCI 是实现 SQL Server 高可用性的最常见方法。 不过,FCI 是在物理部署占据主导地位时设计的。 在虚拟环境中,FCI 不能像在物理硬件上那样提供很多相同的保护,因为 VM 很少出现问题。 FCI 旨在防范网卡故障或磁盘故障等情况,这两种情况都不太可能出现在 Azure 中。
尽管如此,FCI 在 Azure 中确实占有一席之地。 如果它们正常工作,并且只要你对其提供和不提供的内容有正确的预期,FCI 就是个完全可以接受的解决方案。 下图来自 Microsoft 文档,显示了使用存储空间直通时 FCI 部署的高级视图。
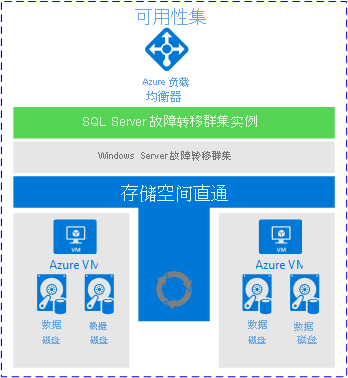
为什么要考虑这种体系结构?
FCI 仍是一个热门的可用性解决方案。
随着 Azure 共享磁盘等功能的出现,共享存储的情况正在改进。
此体系结构可满足 HA 的大多数 RTO 和 RPO(但没有处理 DR)。
此体系结构为应用程序访问 SQL Server 的群集实例提供了一种简单的标准化方法。
此体系结构可为进行修补提供增强的可用性。
灾难恢复示例 1 - 多区域或混合 Always On 可用性组
如果你要使用 AG,一种选择是在多个 Azure 区域配置 AG ,或可将其配置为混合体系结构。 这意味着包含副本的所有节点都会参与同一个 WSFC。 这假定网络连接良好,特别是在使用混合配置的情况下。 最需要考虑的因素之一是 WSFC 的见证资源。 该体系结构要求 AD DS 和 DNS 在每个区域都可用,如果是混合解决方案,可能还要求在本地可用。 下图显示了使用 Windows Server 在两个位置配置的单个 AG 的形式。
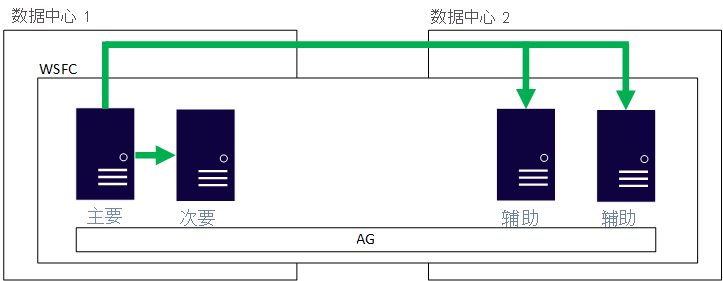
为什么要考虑这种体系结构?
此体系结构是一个成熟的解决方案;它与如今在 AG 拓扑中拥有两个数据中心没有什么不同。
此体系结构适用于 SQL Server Standard Edition 和 SQL Server Enterprise Edition。
AG 自然地通过额外的数据副本提供冗余。
此体系结构利用一项可同时提供 HA 和 D/R 的功能
灾难恢复示例 2 - 分布式可用性组
分布式 AG 是 SQL Server 2016 中引入的 Enterprise Edition 专属功能。 它不同于传统 AG。 分布式 AG 由多个 AG 组成,而不是像前面示例中描述的那样,一个基础 WSFC 中的所有节点都包含参与一个 AG 的副本。 包含读写数据库的主要副本称为全局主要副本。 第二个 AG 的主要副本称为转发器,它使该 AG 的次要副本保持同步。本质上,这是 AG 的一个 AG。
此体系结构可简化仲裁等内容的处理,因为每个群集都将维护自己的仲裁,这意味着它还具有自己的见证。 无论是将 Azure 用于所有资源,还是使用混合体系结构,分布式 AG 都适用。
下图显示了一个分布式 AG 配置示例。 这里有两个 WSFC。 假设每个 WSFC 都位于不同的 Azure 区域,一个位于本地,另一个位于 Azure 中。 每个 WSFC 都有一个具有两个副本的 AG。 AG 1 中的全局主要副本使 AG 1 的次要副本保持同步,转发器(它也是 AG 2 的主要副本)也是如此。 该副本使 AG 2 的次要副本保持同步。
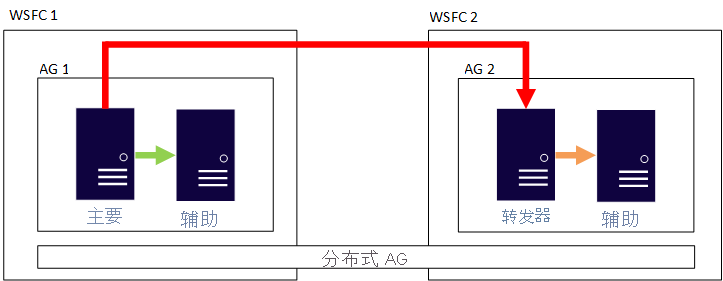
为什么要考虑这种体系结构?
如果所有节点都失去通信,此体系结构会将 WSFC 作为单一故障点分离出来
在此体系结构中,一个主要副本并未同步所有次要副本。
此体系结构可以从一个位置故障回复到另一个位置。
灾难恢复示例 3 - 日志传送
日志传送是最早用于为 SQL Server 配置灾难恢复的 HADR 方法之一。 如上所述,度量单位是事务日志备份。 除非计划切换到热备用状态以确保数据不会丢失,否则很可能会丢失数据。 进行灾难恢复时,最好每次都假设会丢失一些数据(即使很少)。 下图来自 Microsoft 文档,显示了日志传送拓扑示例。
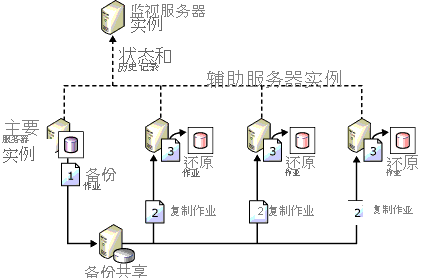
为什么要考虑这种体系结构?
日志传送是一项可靠的功能,已经存在 20 多年了
日志传送基于备份和还原,因此易于部署和管理。
日志传送可以容忍不可靠的网络。
日志传送可满足 DR 的大多数 RTO 和 RPO 目标。
日志传送是保护 FCI 的好办法。
灾难恢复示例 4 - Azure Site Recovery
对于不想实现基于 SQL Server 的灾难解决方案的人来说,Azure Site Recovery 是个可能的选择。 但大部分数据专业人员更喜欢以数据库为中心的方法,因为这种方法通常 RPO 较短。
下图来自 Microsoft 文档。 显示了在 Azure 门户中为 Azure Site Recovery 配置复制的位置。
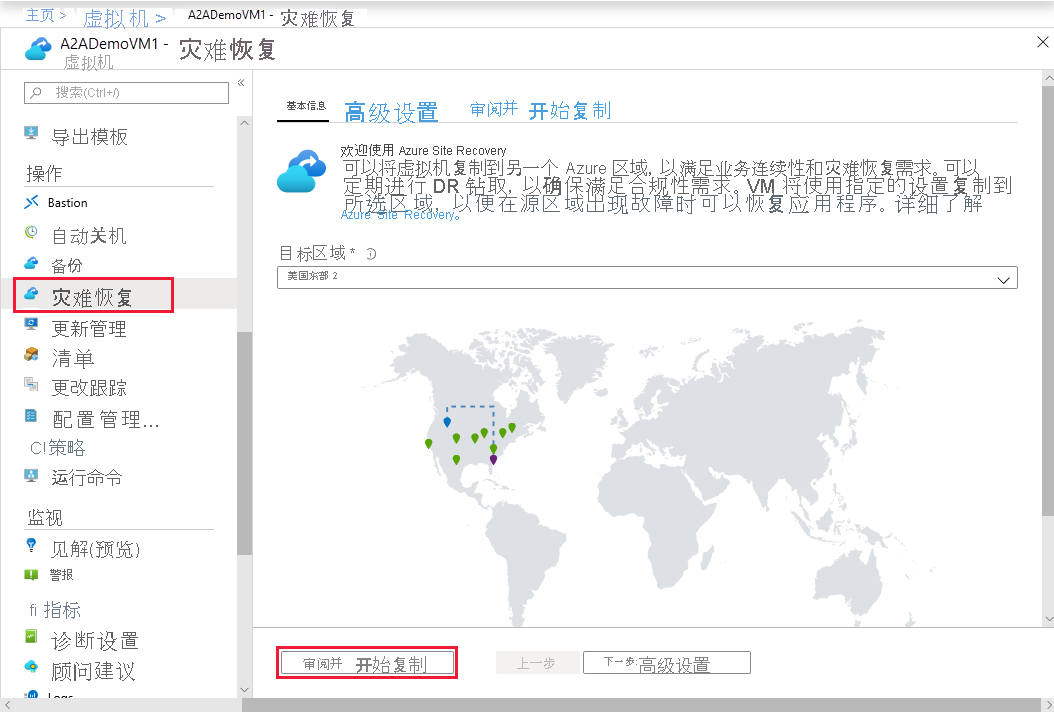
为什么要考虑这种体系结构?
Azure Site Recovery 不仅仅可以用于 SQL Server。
Azure Site Recovery 可以满足 RTO 和可能的 RPO。
Azure Site Recovery 作为 Azure 平台的一部分提供。