使用 Azure Data Lake 设计数据集成解决方案
数据湖是采用其自然格式(通常为 Blob 或文件)存储的数据存储库。 Azure Data Lake Storage 是适用于 Azure 内置的大数据分析的全面、可缩放且经济高效的数据湖解决方案。 Azure Data Lake Storage 将文件系统与存储平台相结合,可帮助快速识别数据见解。 该解决方案基于 Azure Blob 存储功能,为分析工作负载提供优化。 这种集成实现了 Azure 存储的分析性能、高可用性、安全性和持久性功能。
备注
该服务的当前实现是 Azure Data Lake Storage Gen2。
有关 Azure Data Lake Storage 的注意事项
为了更好地了解 Azure Data Lake Storage,让我们来看一下以下特征。
- Azure Data Lake Storage 可以使用数据的原生格式存储任何类型的数据。 Azure Data Lake Storage 支持任何数据格式和海量数据,可以处理结构化、半结构化和非结构化数据。
- 该解决方案主要设计用于与 Hadoop 以及所有使用 Hadoop 分布式文件系统 (HDFS) 作为数据访问层的框架协同工作。 使用 HDFS 作为数据访问层的数据分析框架可直接进行访问。
- Azure Data Lake Storage 支持高吞吐量,可以实现输入和输出密集型分析和数据移动。
- Azure Data Lake Storage 访问控制模型支持 Azure 基于角色的访问控制 (RBAC) 和用于 UNIX 的可移植操作系统接口 (POSIX) 访问控制列表 (ACL)。
- Azure Data Lake Storage 利用 Azure Blob 复制模型。 这些模型使用本地冗余存储 (LRS) 在一个数据中心提供数据冗余。
- Azure Data Lake Storage 提供海量存储并接受多种数据类型进行分析。
- Azure Data Lake Storage 按 Azure Blob 存储级别定价。
Azure Data Lake Storage 的工作原理
需要执行三个重要步骤才能使用 Azure Data Lake Storage:
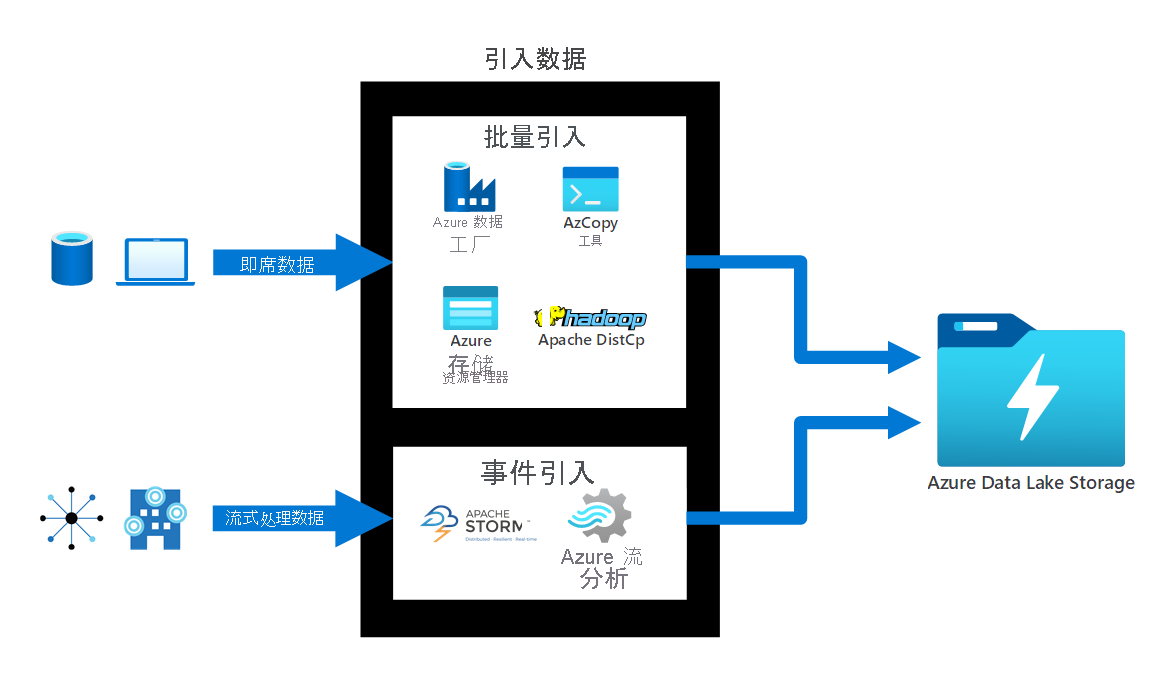
引入数据。 Azure Data Lake Storage 提供了许多不同的数据引入方法:
- 对于计划外数据,可以使用 AzCopy、Azure CLI、PowerShell 和 Azure 存储资源管理器等工具。
- 对于关系数据,可使用 Azure 数据工厂服务。 可以从任何源(例如 Azure Cosmos DB、SQL 数据库、Azure SQL 托管实例等)传输数据。
- 对于流式处理数据,可以使用 Azure HDInsight 上的 Apache Storm、Azure 流分析等工具。
下图显示如何在 Azure Data Lake Storage 中批量引入或者非计划引入计划外数据和流数据。
访问存储的数据。 访问数据最简单的方法是使用 Azure 存储资源管理器。 存储资源管理器是具有图形用户界面 (GUI) 的独立应用程序,用于访问 Azure Data Lake Storage 数据。 还可以使用 PowerShell、Azure CLI、HDFS CLI 或其他编程语言 SDK 来访问数据。
配置访问控制。 通过实现授权机制,控制谁可以访问 Azure data Lake Storage 中存储的数据。 可以选择 Azure RBAC 或 ACL。
业务场景
Tailwind Traders 拥有多种数据源,包括网站、销售点 (POS) 系统、社交媒体网站和物联网 (IoT) 设备。 该公司对使用 Azure 分析其所有业务数据十分感兴趣。 你的任务是提供有关 Azure 如何增强其现有 BI 系统的指导。 你需要向团队建议 Azure 存储功能如何为公司的 BI 解决方案增加价值。 为了满足数据要求,你计划推荐 Azure Data Lake Storage。 Data Lake Storage 提供一个存储库,你可以在着眼于高性能大数据分析的情况下,在其中上传并存储海量非结构化数据。
让我们回顾一下 Azure Data Lake Storage 如何成为满足组织大数据需求的正确选择。
| 方案 | 解决方案 |
|---|---|
| 在云中提供数据仓库来管理大量数据。 | Azure Data Lake Storage 在 Azure 平台上的虚拟硬件上运行。 存储具有可缩放性、快速性和可靠性,而不会产生巨额费用。 它可以将存储成本与计算成本分开。 随着数据量的增长,只有存储需求会发生变化。 |
| 支持各种数据类型集合,如 JSON 文件、CSV、日志文件或其他各种格式。 | Azure Data Lake Storage 通过将所有数据格式(包括原始数据)存储在单个位置,为组织实现数据民主化。 消除数据孤岛后,用户可以使用 Azure 数据资源管理器等工具来访问和使用其存储帐户中的每一个数据项。 |
| 启用实时数据引入和存储。 | Azure Data Lake Storage 可以直接从 Azure HDInsight 上的 Apache Storm 实例、Azure IoT 中心、Azure 事件中心或 Azure 流分析引入实时数据。 它还可以处理半结构化数据,让你将所有实时数据引入存储帐户中。 |
选择 Azure Blob 存储或 Azure Data Lake 时的注意事项
下表比较了使用 Azure Blob 存储与 Azure Data Lake 的存储解决方案条件。 审查标准,考虑哪种解决方案最适合 Tailwind Traders。
| 比较 | Azure Data Lake | Azure Blob 存储 |
|---|---|---|
| 数据类型 | 适合存储大量文本数据 | 适合存储非结构化非文本数据,例如照片、视频及备份 |
| 异地冗余 | 必须手动配置数据复制 | 默认提供异地冗余存储 |
| 命名空间 | 支持分层命名空间 | 支持平面命名空间 |
| Hadoop 兼容性 | Hadoop 服务可以使用存储在 Azure Data Lake 中的数据 | 使用 Azure Blob Filesystem Driver,应用程序和框架可以访问 Azure Blob 存储中的数据 |
| 安全性 | 支持精细访问 | 不支持精细访问 |