了解转换器如何推进语言模型
使用 转换器体系结构可以实现当今使用的生成 AI 应用程序。 Transformer 是在 2017 年 Vaswani 等人撰写的《Attention is all you need》(注意力是你所需要的一切)论文中引入的。
转换器体系结构引入了大幅改进模型理解和生成文本的能力的概念。 已使用不同的转换器体系结构的适应来训练不同的模型,以针对特定的 NLP 任务进行优化。
了解转换器体系结构
原始转换器体系结构中有两个主要组件:
- 编码器:负责处理输入序列并创建捕获每个令牌上下文的表示形式。
- 解码器:通过参与编码器的表示形式并预测序列中的下一个标记来生成输出序列。
转换器体系结构中提供的最重要创新是 位置编码 和 多头关注。 体系结构的简化表示形式:
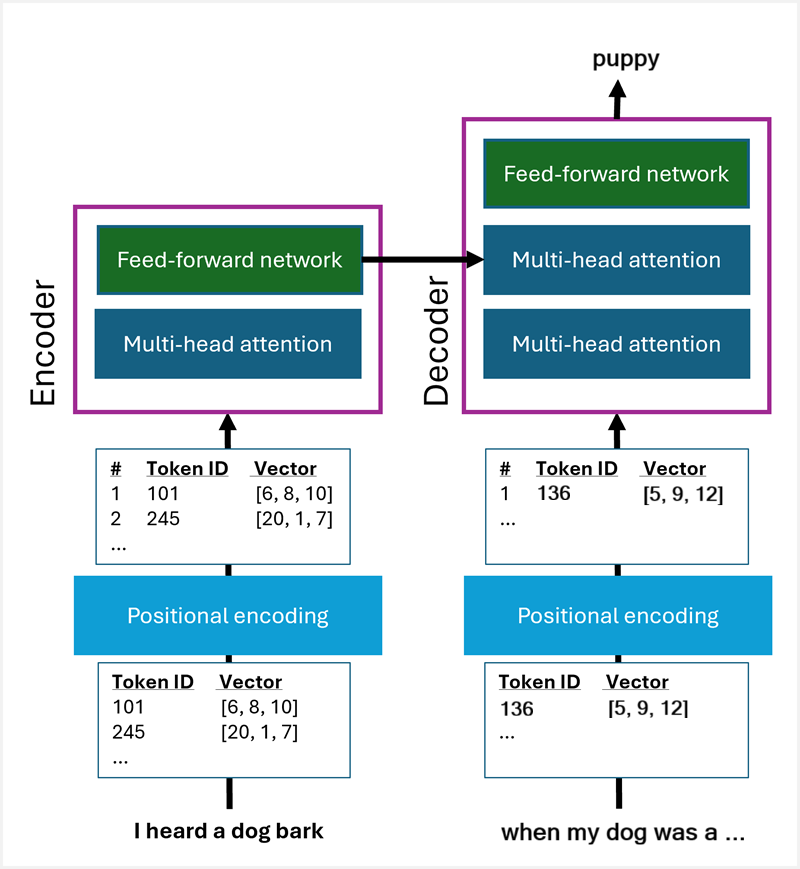
- 在 编码器 层中,输入序列首先通过位置编码进行编码,然后使用多头注意机制来构建文本的表示形式。
- 在 解码器 层中,一个(不完整)输出序列以类似的方式进行编码,首先使用位置编码,然后进行多头关注。 然后,在解码器内再次使用多头关注机制来组合编码器的输出以及作为解码器部件输入传递的编码输出序列的输出。 因此,可以生成输出。
了解位置编码
单词的位置和句子中的单词顺序对于理解文本的含义非常重要。 若要包含此信息,无需按顺序处理文本,转换器将使用 位置编码。
在转换器之前,语言模型使用单词嵌入将文本编码为矢量。 在转换器体系结构中, 位置编码 用于将文本编码为矢量。 位置编码是词嵌入向量和位置向量的总和。 通过这样做,编码的文本包括有关单词在句子中的含义 和 位置的信息。
若要对单词在句子中的位置进行编码,可以使用单个数字来表示索引值。 例如:
| 标记 | 索引值 |
|---|---|
| 这 | 0 |
| 工作 | 1 |
| - | 2 |
| 威廉 | 3 |
| 莎士比亚 | 4 |
| 启发 | 5 |
| 多 | 6 |
| 电影 | 7 |
| ... | ... |
文本或序列越长,索引值就越大。 尽管对文本中每个位置使用唯一值是一种简单的方法,但值将没有任何意义,并且不断增长的值可能会在模型训练期间产生不稳定。
了解关注
转换器用来处理文本的最重要技术是使用注意力而不是重复。 通过这种方式,转换器体系结构提供了 RNN 的替代方法。 虽然 RNN 是计算密集型的,因为它们按顺序处理单词,但转换器不会按顺序处理单词,而是使用 注意并行处理每个单词。
注意力(也称为自注意力或内注意力)是一种机制,用于将新信息映射到已学习的信息,以理解新信息所包含的内容。
Transformer 使用注意力函数,其中新字词使用位置编码进行了编码,并表示为查询。 已编码的字词的输出是具有关联值的键。
为了说明注意函数使用的三个变量:查询、键和值,让我们探索一个简化的示例。 假设在对句子Vincent van Gogh is a painter, known for his stunning and emotionally expressive artworks.进行编码时,以及对查询Vincent van Gogh进行编码时,输出可能是Vincent van Gogh作为键,painter作为关联的值。 体系结构将键和值存储在表中,然后可用于将来的解码:
| 钥匙 | 价值观 |
|---|---|
| 文森特·范高 | 画家 |
| 莎士比亚 | 剧作家 |
| 查尔斯·迪肯斯 | 作家 |
每次显示新句子时,例如 Shakespeare's work has influenced many movies, mostly thanks to his work as a ...。 模型可以通过将Shakespeare作为查询,并在键和值表中查找来完成句子。
Shakespeare 查询最接近 William Shakespeare 的键,因此相应的值 playwright 将作为输出呈现。
为了计算注意力函数,查询、键和值都编码为向量。 然后,注意函数计算查询向量和键向量之间的缩放点积。 点积用于计算表示标记的向量之间的角度,当向量更对齐时,结果越大。
softmax 函数在注意力函数中对矢量的缩放点积使用,来创建具有可能结果的概率分布。 换句话说,softmax 函数的输出包括最接近查询的键。 然后选择概率最高的键,并且关联的值是注意函数的输出。
转换器体系结构使用多头关注,这意味着令牌由注意力函数并行处理多次。 通过执行此作,可以通过多种方式多次处理单词或句子,以便从句子中提取不同类型的信息。
转换器体系结构使我们能够以更高效的方式训练模型。 注意允许模型以各种方式并行处理令牌,而不是处理句子或序列中的每个标记。 接下来,了解不同类型的语言模型如何可用于生成 AI。