事件的特征和生命周期
- 4 分钟
在上一单元中你学到,故障 是影响客户和最终用户的服务中断。 事件的形式多种多样,从对用户造成困扰的性能下降(“缓慢是新的性能降低表现”)到导致服务或站点在一段时间内完全不可用的系统崩溃,不一而足。
事件的特征
事件通常是意外的,似乎发生在最糟糕的时间(如凌晨 2:00,或者当你深深沉浸于重要项目中时)。 因此,人们通常会害怕并避免事件,甚至有时会淡化事件的重要性。 由于害怕受到惩罚,当组织内部压力过大时,经常会有人倾向于误报或不报告干扰事件。
至少,事件会产生计划外的工作,并且因为你大部分时间都花在计划内工作,并很好地了解你应该做的事情,你可能会认为事件是坏事。 但是,还有另一种方法可以看待它:故障/事故实际上是为了向最终用户提供你想要传递的价值而进行的投资。 无论事件的原因或影响程度如何,所有事件都有一个共同点:它们可以提供宝贵的学习体验。
应将事件视为 系统的脉搏。 与你之前所了解到的信息相比,它们会告知你更多关于系统的信息,而知晓这些信息则是一件好事。 当你有强大的监视基础,并了解有关系统中发生的事情的详细信息时,它不可避免地会生成更多的警报和事件和响应机会。 至少,事件会告诉你发生了什么,从而提高运营意识。 在上一个关于监视的模块中,我们建议这是可靠性工作的重要前兆。
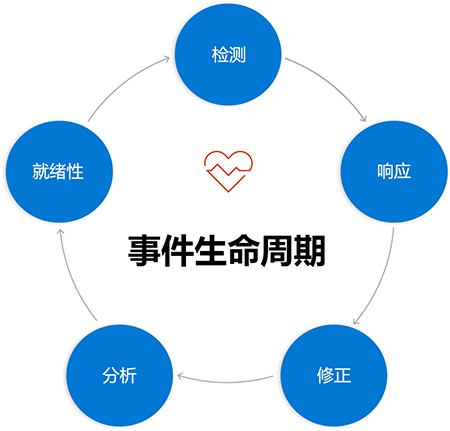
事件的生命周期
如果想要将事件响应团队的状态提升到“精英/高绩效”水平,则必须不仅要将服务中断或事件视为简单的线性时间线,而是从循环的角度进行思考。
您可以将事件的生命周期分为彼此逻辑顺序前后相随的特定阶段,形成一个周而复始的循环。 每次历经此循环时(并且你将历经多次),如果你正确处理它,那么在回到起点时,你可能会对你的系统有了更深入的见解。 通过一些有意的工作,还可以更好地准备在下次事件发生时快速有效地做出响应。
事件的阶段
事件响应过程的各个阶段看起来略有不同,具体取决于所使用的模型。 本模块涉及在响应事件时需要经历的五个阶段:
- 检测:此阶段是此学习路径中上一模块的监视知识发挥作用的地方。 监视工具从日志中收集信息,根据你配置的以客户为中心的目标分析该信息,并发送可作的警报,让你知道需要人工干预。
- 响应:此阶段是你和你的团队收到该警报后会发生什么情况。 在本模块中,我们将详细探讨此阶段,因此在短短的一刻内,将有更多关于这个想法的介绍。
- 修正:此阶段将系统还原为正常功能。 具体作方式取决于服务中断的原因。 让服务恢复正常并对客户开放是您的首要任务。 然而,完成任务后,你的工作并没有结束。
- 分析:若要从事件中获取持久价值,需要从事件中吸取教训。 此阶段是收集有关所发生的事情以及事件发生时间的信息,以及通过提出正确的问题来了解可从中学到的内容的过程。 有一个关于学习失败的整个模块,可解决此阶段问题。
- 就绪情况:应将分析阶段学到的教训合并到作实践中。 如果存在有助于防止将来出现类似中断的作项,它们也将是此阶段的一部分。
在创建事件响应计划之前,需要了解事件的特征和价值,并熟悉事件生命周期的各个阶段。 下一步是确保响应策略建立在坚实的基础之上。