创建 Kafka 和 Spark 体系结构
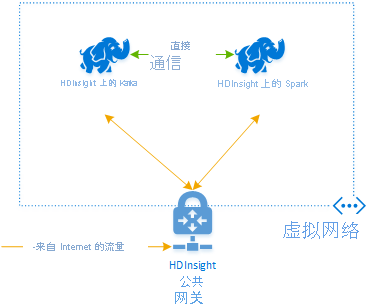
若要在 Azure HDInsight 中结合使用 Kafka 和 Spark,必须将它们放置在同一个 VNet 中,或使 VNet 对等,以便群集通过 DNS 名称解析运行。
在同一个 VNet 中创建群集的过程是:
- 创建资源组
- 将 VNet 添加到资源组
- 将 Kafka 群集和 Spark 群集添加到同一个 VNet 中;或者如果这些服务使用 DNS 名称解析在 VNet 中运行,使这些 VNet 对等。
连接 HDInsight Kafka 和 Spark 群集的推荐方式是使用本机 Spark-Kafka 连接器,它使 Spark 群集能够访问 Kafka 群集中数据的各个分区,从而提高你在实时处理作业过程中的并行度,并提供非常高的吞吐量。
两个群集位于同一个 VNet 中时,你还可以在 Spark 流代码中使用 Kafka 中转站 FQDN,以及在 VNet 上创建 NSG 规则以实现企业级安全性。
解决方案体系结构
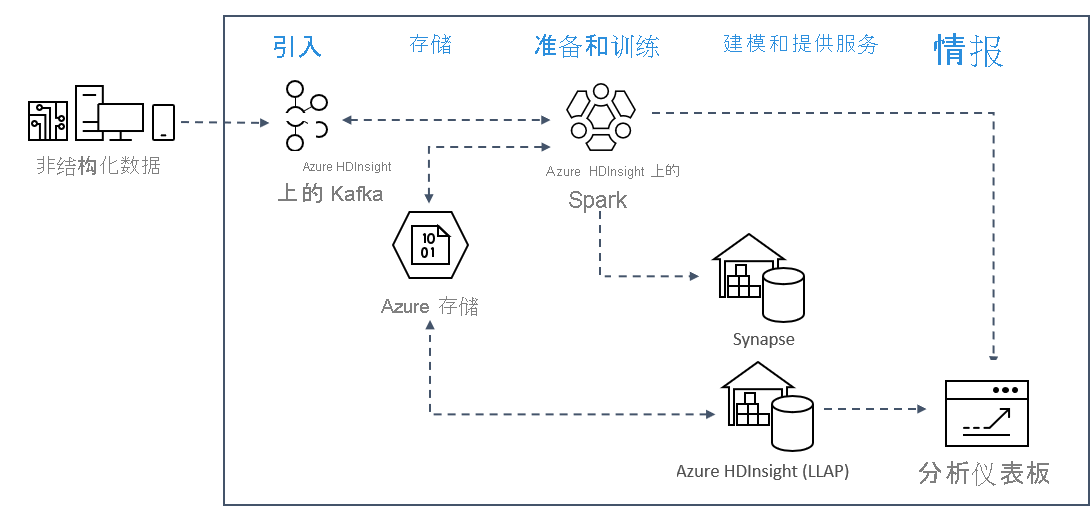
Azure 上的实时流式处理分析模式通常使用以下解决方案体系结构。
- 引入:非结构化或结构化数据引入到 Azure HDInsight 上的 Kafka 群集中。
- 准备和训练:使用 Spark on HDInsight 预先准备和训练数据。
- 模型和服务:数据放入数据仓库,例如 Azure Synapse 或 HDInsight 交互式查询。
- 智能:数据被传输到像 Power BI 或 Tableau 这样的分析仪表板中。
- 存储:数据将放入冷存储解决方案(如 Azure 存储),并在以后提供。
示例方案体系结构
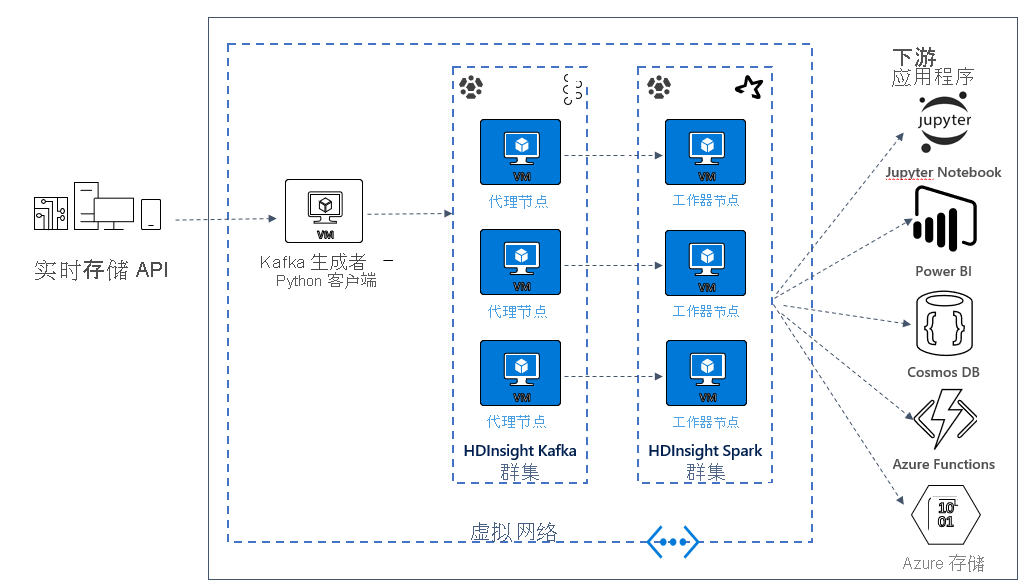
在下一个单元中,你将开始为示例应用程序构建解决方案体系结构。 此示例使用 Azure 资源管理器模板文件创建资源组、VNET、Spark 群集和 Kafka 群集。
部署群集后,你将利用 ssh 连接到 Kafka 中转站之一,并将 Python 制作者文件复制到头节点。 该制作者文件每 10 秒提供一次人为股票价格,它还将分区编号和消息的偏移写入控制台。
制作者运行后,你可以将 Jupyter Notebook 上传到 Spark 群集。 在笔记本中,你将连接 Spark 和 Kafka 群集,并对数据运行一些示例查询,包括在事件窗口内查找股票的高低值。