练习 - 清理和准备数据
你需要先了解数据集的内容和结构,然后才能准备数据集。 在上一实验室中,你导入了包含美国一家主要航空公司的准点到达信息的数据集。 该数据包含 26 列和数千行,其中每行代表一个航班,包含航班的出发地、目的地和计划出发时间等信息。 你还将数据加载到 Jupyter Notebook 中,并使用简单的 Python 脚本从中创建 Pandas DataFrame。
DataFrame 是二维标签数据结构。 DataFrame 中的列可以为不同类型,就像电子表格或数据库表中的列一样。 它是 Pandas 中最常用的对象。 在本练习中,你将更深入地了解 DataFrame 及其中的数据。
切换回到你在上一部分中创建的 Azure Notebook。 如果关闭了该笔记本,可重新登录 Microsoft Azure Notebooks 门户,打开笔记本,然后使用“单元格”-“全部运行”,在打开笔记本后重新运行笔记本中的所有单元格。
FlightData 笔记本
你在上一实验室中添加到笔记本中的代码会通过 flightdata.csv 创建 DataFrame,并在其中调用 DataFrame.head 以显示前五行。 对于数据集,你通常首先想要了解的事项之一是数据集中包含多少行。 若要获取计数,请在笔记本末尾的空单元格中键入以下语句并运行它:
df.shape确认 DataFrame 包含 11,231 行和 26 列:

获取行数和列数
现在花点时间查看数据集中的 26 列。 它们包含重要信息,例如航班飞行日期(YEAR、MONTH 和 DAY_OF_MONTH)、出发地和目的地(ORIGIN 和 DEST)、计划出发和到达时间(CRS_DEP_TIME 和 CRS_ARR_TIME)、以分钟为单位的计划到达时间和实际到达时间之间的差异 (ARR_DELAY),以及航班是否晚点 15 分钟或更长时间 (ARR_DEL15)。
以下是数据集中的列的完整列表。 时间以 24 小时军事时间表示。 例如,1130 等于上午 11:30,1500 等于下午 3:00。
列 说明 年份 航班飞行的年份 季度 航班飞行的季度 (1-4) MONTH 航班飞行的月份 (1-12) DAY_OF_MONTH 航班飞行的当月日期 (1-31) DAY_OF_WEEK 航班飞行的当周日期(1 = 星期一,2 = 星期二等) UNIQUE_CARRIER 航空公司代码(例如,DL) TAIL_NUM 飞机机尾编号 FL_NUM 航班号 ORIGIN_AIRPORT_ID 出发地机场 ID 起源 出发地机场代码(ATL、DFW、SEA 等) DEST_AIRPORT_ID 目的地机场 ID DEST 目的地机场代码(ATL、DFW、SEA 等) CRS_DEP_TIME 计划出发时间 DEP_TIME 实际出发时间 DEP_DELAY 出发晚点分钟数 DEP_DEL15 0 = 出发晚点不到 15 分钟,1 = 出发晚点 15 分钟或更长时间 CRS_ARR_TIME 计划到达时间 ARR_TIME 实际到达时间 ARR_DELAY 航班到达晚点分钟数 ARR_DEL15 0 = 到达晚点不到 15 分钟,1 = 到达晚点 15 分钟或更长时间 取消 0 = 航班未取消,1 = 航班已取消 DIVERTED 0 = 航班未转移,1 = 航班已转移 CRS_ELAPSED_TIME 以分钟为单位的计划飞行时间 ACTUAL_ELAPSED_TIME 以分钟为单位的实际飞行时间 距离 以英里为单位的飞行距离
该数据集包含在全年大致均匀分布的日期,这很重要,因为相较 1 月,从明尼阿波里斯市出发的航班在 7 月因冬季风暴而晚点的可能性更低。 但此数据集远非“干净”和随时可用。 让我们编写一些 Pandas 代码来清理它。
准备用于机器学习的数据集的最重要方面之一在于,选择与你尝试预测的结果相关的“特征”列,并同时筛选掉不影响结果的列,这可能会以负面方式使其产生偏差,或者可能会产生多重共线性。 另一项重要任务是通过删除包含缺失值的行或列,或通过使用有意义的值替换缺失值来清除缺失值。 在本练习中,你将清除无关的列并替换剩余列中的缺失值。
数据科学家通常首先在数据集中寻找缺失值。 有一种简单的方法可以检查 Pandas 中的缺失值。 若要演示,请在笔记本末尾的单元格中执行以下代码:
df.isnull().values.any()确认输出为“True”,这表示数据集中某处至少有一个缺失值。

检查缺失值
下一步是找出缺失值所在的位置。 为此,请执行以下代码:
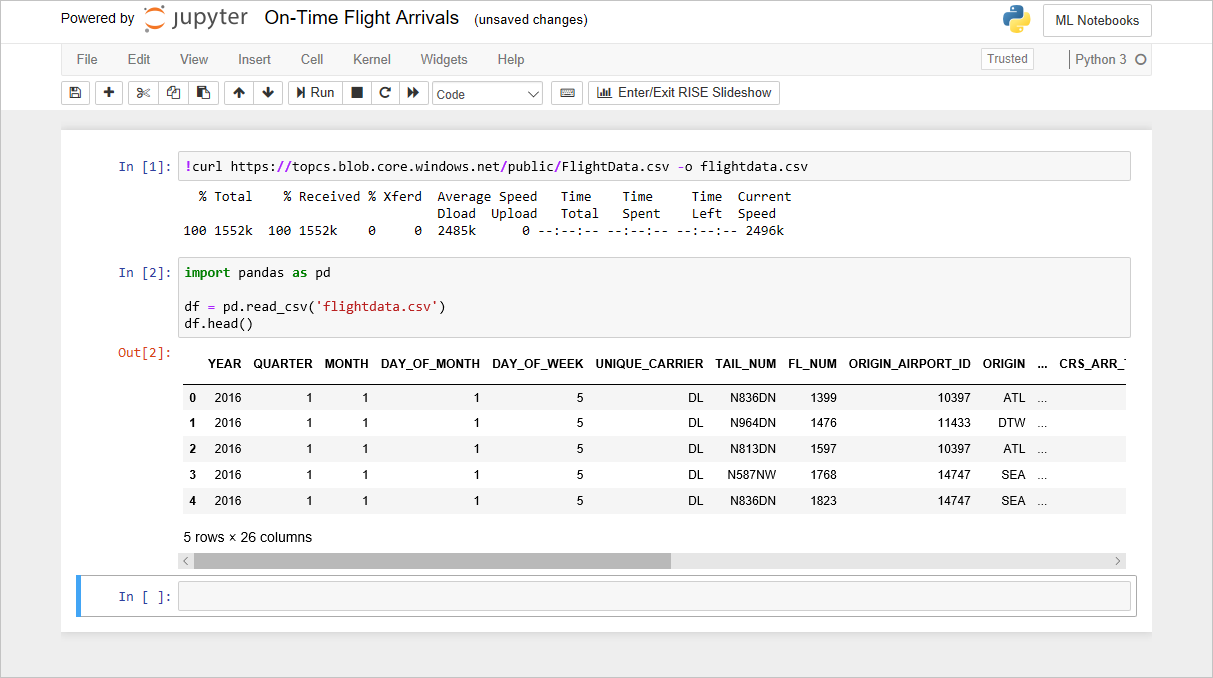
df.isnull().sum()确认看到以下列出每列中的缺失值计数的输出:
每列中的缺失值数量
有意思的是,第 26 列(“Unnamed:25”)包含 11,231 个缺失值,这等于数据集中的行数。 此列被错误地创建,因为你导入的 CSV 文件在每行末尾包含一个逗号。 若要清除该列,请将以下代码添加到笔记本中并执行它:
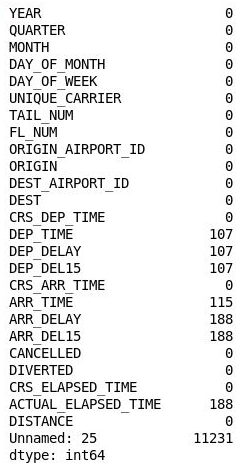
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()检查输出并确认第 26 列已从 DataFrame 中消失:
删除了第 26 列的 DataFrame
DataFrame 仍然包含许多缺失值,但其中一些缺失值是无用的,因为包含它们的列与你正在构建的模型无关。 该模型的目标是预测你考虑预订的航班是否可能准点到达。 如果你知道航班可能晚点,你可能会选择预订其他航班。
因此,下一步是筛选数据集以清除与预测模型无关的列。 例如,飞机的机尾编号可能与航班是否准点到达几乎没有关联,而在你预订机票时,你无法知道航班是否会取消、转移或晚点。 相比之下,计划出发时间可能与准点到达有很大关联。 由于大多数航空公司使用轮辐式系统,早上的航班往往比下午或晚上的航班更准时。 在一些主要机场,客流量在白天堆积,增加了后期航班晚点的可能性。
Pandas 提供一种简单的方法用于筛选掉不需要的列。 在笔记本末尾的新单元格中执行以下代码:
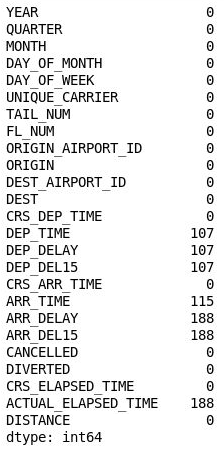
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()输出显示 DataFrame 现在仅包含与模型相关的列,并且缺失值的数量大幅减少:
筛选后的 DataFrame
现在,唯一包含缺失值的列是 ARR_DEL15 列,该列使用 0 来标识准点到达的航班,使用 1 来标识未准点到达的航班。 使用以下代码显示包含缺失值的前五行:
df[df.isnull().values.any(axis=1)].head()Pandas 使用
NaN表示缺失值,其表示非数字。 输出显示这些行实际上是 ARR_DEL15 列中的缺失值: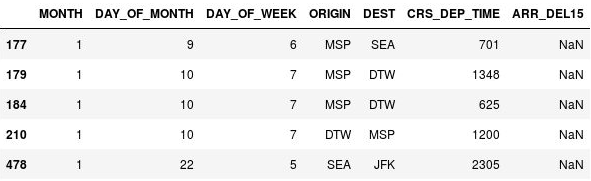
包含缺失值的行
这些行缺失 ARR_DEL15 值的原因在于它们全都对应于已取消或转移的航班。 你可以在 DataFrame 上调用 dropna 来删除这些行。 但是,由于取消或转移到另一机场的航班可能被视为“晚点”,让我们使用 fillna 方法将缺失值替换为 1。
使用以下代码将 ARR_DEL15 列中的缺失值替换为 1 并显示第 177 到 184 行:
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]确认第 177、179 和 184 行中的
NaN被替换为表示航班晚点的 1: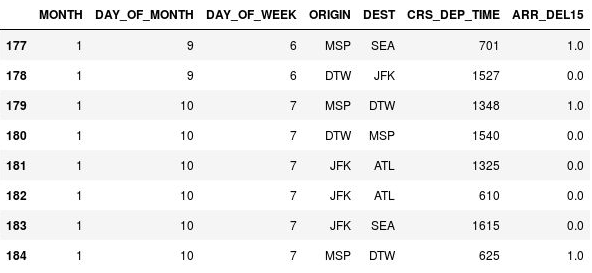
NaN 替换为 1
数据集现在是“干净的”,因为缺失值已被替换,且列的列表已将范围缩小到与模型最相关的列。 但你的任务还没有完成。 准备数据集以用于机器学习还有很多工作要做。
你正在使用的数据集的 CRS_DEP_TIME 列表示计划出发时间。 此列(包含超过 500 个唯一值)中数字的粒度可能会对机器学习模型的准确率产生负面影响。 这可以使用名为分箱或量化的技术来解决。 如果将此列中的每个数字除以 100 并向下舍入到最近的整数会怎么样? 1030 将变为 10,1925 将变为 19,依此类推,并且你将在此列中最多留下 24 个离散值。 直观地说,这是有道理的,因为航班是在上午 10:30 还是在上午 10:40 出发可能无关紧要。重点在于它是在上午 10:30 出发还是在下午 5:30 出发。
此外,数据集的 ORIGIN 和 DEST 列包含代表分类机器学习值的机场代码。 这些列需要转换为包含指示变量(有时称为“虚拟”变量)的离散列。 换句话说,包含五个机场代码的 ORIGIN 列需要转换为五列,每个机场一列,且每列都包含指示航班是否从该列所表示的机场出发的 1 和 0。 DEST 列需要以类似的方式进行处理。
在本练习中,你将对 CRS_DEP_TIME 列中的出发时间进行“分箱”,并使用 Pandas 的 get_dummies 方法从 ORIGIN 和 DEST 列创建指示列。
使用以下命令显示 DataFrame 的前五行:
df.head()请注意,CRS_DEP_TIME 列包含表示军事时间的 0 到 2359 之间的值。
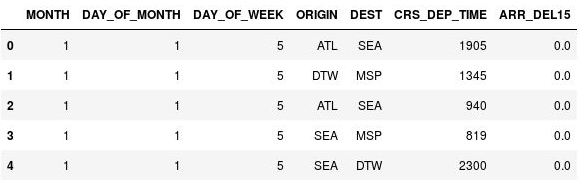
具有未分箱出发时间的 DataFrame
使用以下语句来对出发时间进行分箱:
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()确认 CRS_DEP_TIME 列中的数字现在落在 0 到 23 的范围内:
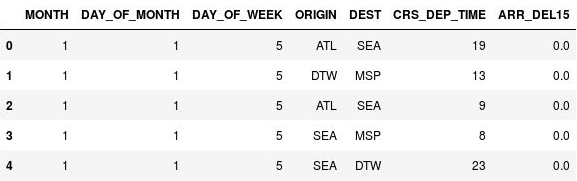
具有分箱出发时间的 DataFrame
现在使用以下语句从 ORIGIN 和 DEST 列生成指示列,同时删除 ORIGIN 和 DEST 列本身:
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()检查生成的 DataFrame,注意 ORIGIN 和 DEST 列已替换为与原始列中存在的机场代码对应的列。 新列具有 1 和 0,指示给定航班是从对应机场起飞还是飞往对应机场。
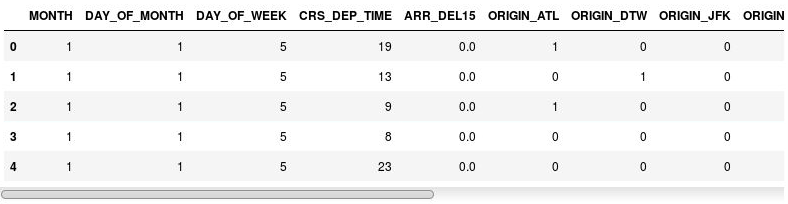
具有指示列的 DataFrame
使用“文件”-“保存和检查点”命令来保存笔记本。
该数据集看起来与开始时完全不同,但它现在已经过优化,可用于机器学习。