使用运算符转换数据
虽然 Data Wrangler 中的许多运算符直观且易于使用,但其他运算符需要更深入地理解才能充分利用它们。
使用单热编码运算符
某些机器学习模型(如线性回归)要求所有输入和输出变量都是数字变量,并且不支持分类变量。 分类数据是指划分为多个类别的变量,这些类别不携带数值或顺序。
在 一热编码中,特征中的每个类别都表示为 1 和 0 的二进制向量。
例如,如果你有一个具有值狗、猫和鸟的宠物变量,将创建三个新变量(每个宠物类型一个)。 对于每个数据点,它为它所表示的宠物标记 1 ,而其他数据点则为 0 。 因此,如果数据点表示 狗,则它编码为 [1, 0, 0]。 如果是 猫,它[0,1, 0],如果它是 一只鸟,它就是 [0, 0, 1]。
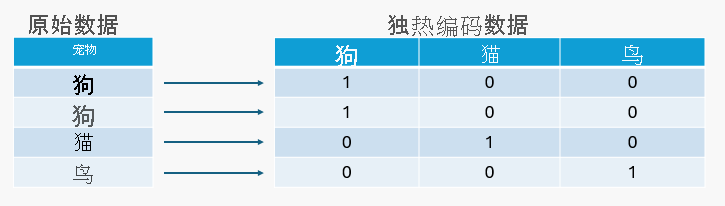
注释
当数据集中的特征数量变得非常大时,独热编码可能会导致维数增加。 当分类变量具有许多唯一值时,尤其如此。
让我们根据上面的“宠物”示例创建一个数据框,并使用数据整理器生成用于独热编码的代码。
import pandas as pd
# Sample dataset with 50 data points, including duplicates
data = {'pet': ['dog', 'dog', 'cat', 'cat', 'bird', 'bird']*8 + ['bird', 'cat']}
df = pd.DataFrame(data)
print(df.head(10))
以下步骤演示如何对 pet 变量使用单热编码运算符。
从 Microsoft Fabric 笔记本为
df数据框启动数据整理器。选择变量
pet。在“操作”面板中,选择“公式”,然后选择“独热编码”。
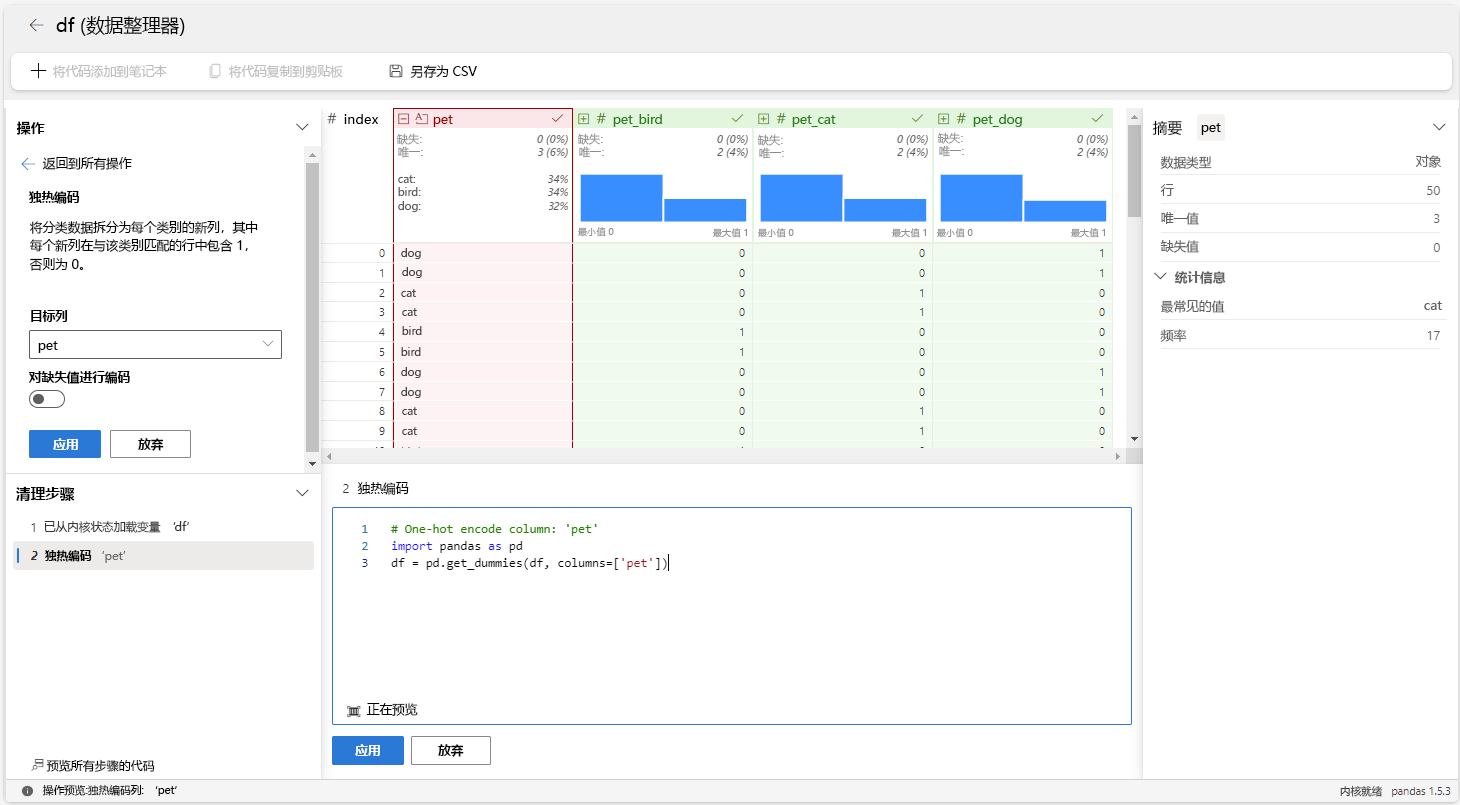
选择应用。
在 Data Wrangler 网格上方的工具栏中选择 “+ 向笔记本添加代码 ”。 这会生成一个可在数据管道中执行的函数。
使用多标签二值化器运算符
当每个数据点完全属于一个类别时,使用一热编码。 另一方面,当每个数据点可以属于多个类别时,将使用多标签二进制器运算符。
多标签二值化器运算符允许你使用文本分隔符将分类数据拆分为每个类别的新列,其中每个新列在与该类别匹配的行中包含 1,否则为 0。
出于训练目的,让我们创建一个有关食品类别的数据帧,并使用 Data Wrangler 为多标签二进制器生成代码。
import pandas as pd
#Sample data
data = {
'food': ['Pasta', 'Burger', 'Ice Cream', 'Salad'],
'category': ['Italian|Fine dining', 'American|Fast Food', 'Dessert', 'Healthy']
}
# Create DataFrame
restaurant = pd.DataFrame(data)
然后,以下步骤演示如何对变量使用多标签二进制器运算符 category 。
从 Microsoft Fabric 笔记本为
restaurant数据框启动数据整理器。选择变量
category。在 “操作” 面板中,选择 “公式”,然后选择 “多标签二值化器”。
输入 | 作为分隔符。
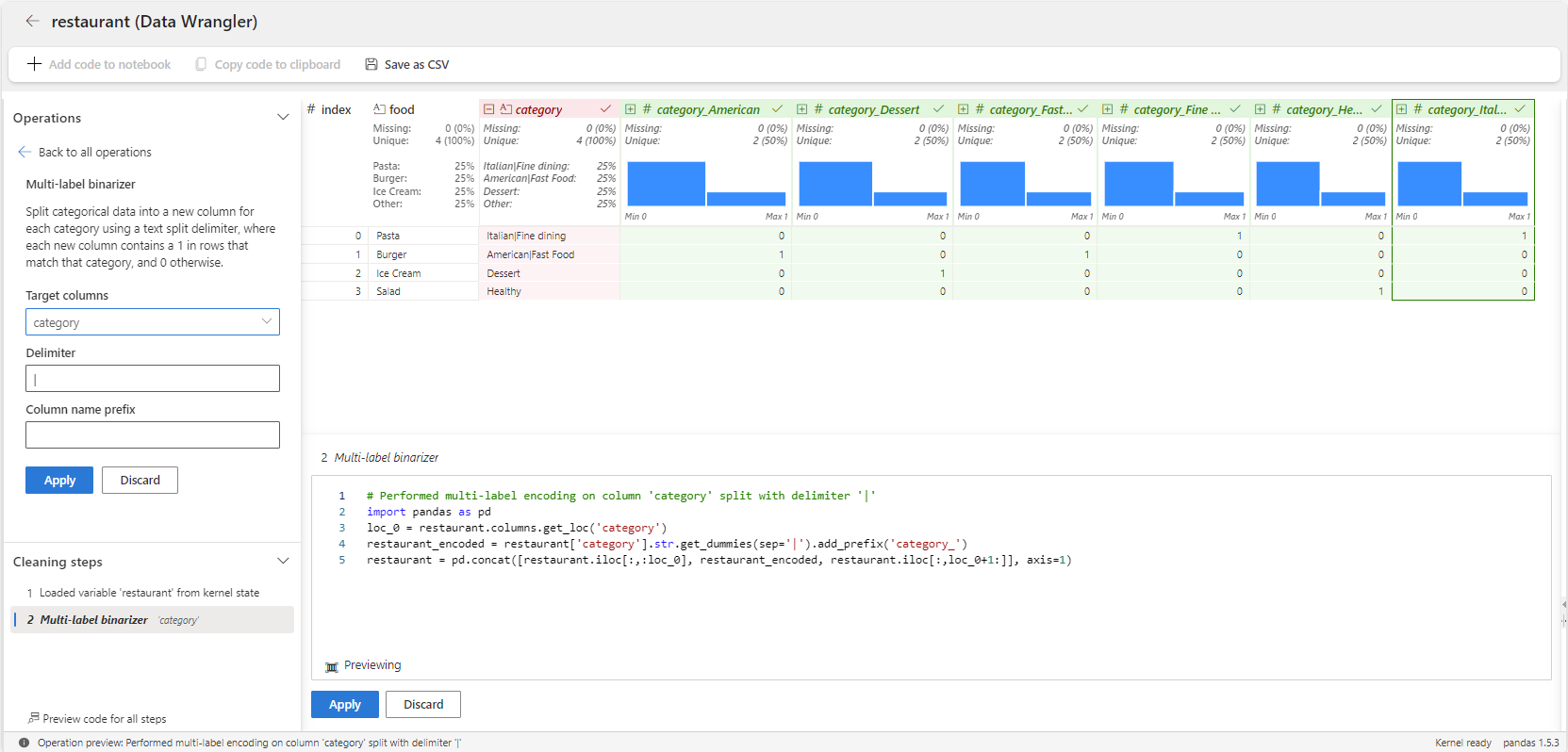
结果是一个数据帧,其中包含每个类别(如 美国、 甜点、 快餐、 健康和 意大利)的变量。 每个食物项目都用这些列中的 1 或 0 标记,以显示它所属的类别。 例如, 披萨 和 汉堡 都属于多个类别。
选择应用。
在 Data Wrangler 网格上方的工具栏中选择 “+ 向笔记本添加代码 ”。 这会生成一个可在预处理管道中执行的函数。
使用最小最大缩放运算符
最小最大缩放或最小-最大规范化 是转换数字特征的过程。 此过程可缩放数据范围,同时保留原始分布的形状和变量之间的关系。
它确保特征的重要性取决于特征的相对值,而不是其绝对值。 换句话说,特性不被视为更重要,只是因为它们具有更大的规模。
它采用数据中的每个值,减去该数据的最小值,然后除以数据范围(最大值减去最小值)。
结果是,数据通常重新缩放为 0 到 1 的范围,这对于某些类型的机器学习算法非常有用,尤其是那些使用距离度量值(如 K-Nearest Neighbors)的数据。
让我们考虑一个表示课堂中学生成绩的数据帧。 数据帧有三列:Student、Math_Grade和English_GradeHours_Studied。
import pandas as pd
# Sample data
data = {
'Student': ['Bob', 'Mark', 'Anna', 'David', 'Sam'],
'Math_Grade': [85, 90, 78, 92, 88],
'English_Grade': [80, 85, 92, 88, 90],
'Hours_Studied': [250, 500, 355, 245, 199]
}
df = pd.DataFrame(data)
print(df)
输出为:
Student Math_Grade English_Grade Hours_Studied
0 Bob 85 80 250
1 Mark 90 85 500
2 Anna 78 92 355
3 David 92 88 245
4 Sam 88 90 199
现在,让我们使用 Data Wrangler 将最小缩放器应用于Math_Grade和English_GradeHours_Studied变量。 为此,需要使用 Numeric 类别下的 Scale min/max 值运算符。
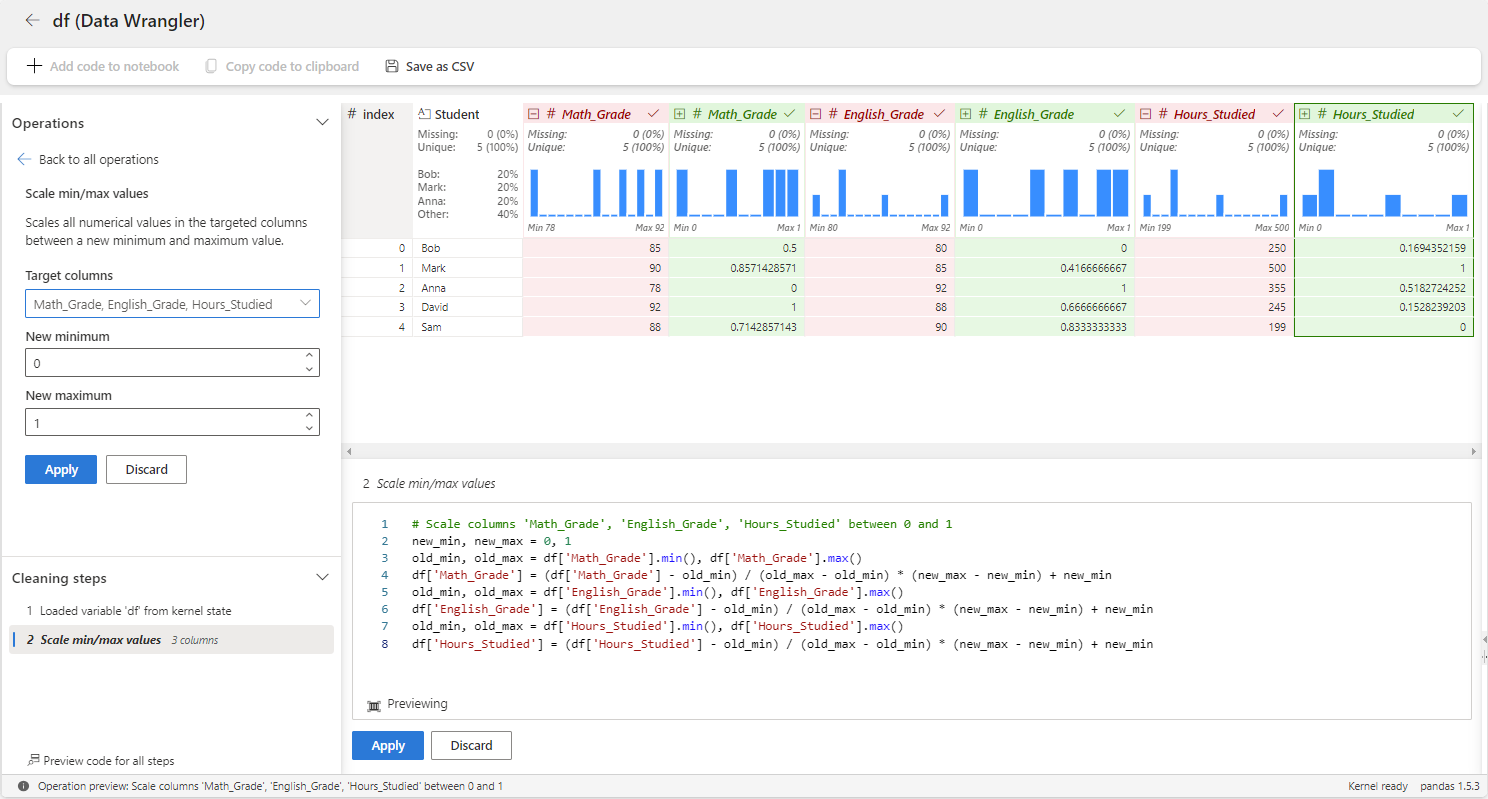
在上述等级中,分数被调整到范围 [0, 1] 内,最低分数映射为 0,最高分数映射为 1。 其他成绩在此范围内按比例缩放。 还可以调整最小和最大范围。
如果在基于距离的机器学习算法(例如 K-Nearest Neighbors)中使用 Math_Grade、English_Grade 和 Hours_Studied 等特征而不首先对其进行缩放,则可能会遇到一些问题。
Hours_Studied 特征由于其值的范围较大,可能会主宰其他特征。 这可能导致严重依赖 Hours_Studied的模型,同时忽略 Math_Grade 和 English_Grade。 因此,请务必在这些情况下缩放数据,以确保所有功能都给予同等的重要性。
若要详细了解机器学习模型的数据规范化,请参阅 数据转换。