Azure AI 视觉入门
100 XP
计算机系统处理书面和印刷文本的能力是 AI 的一个领域,其中 计算机视觉 与 自然语言处理相交。 视觉功能需要“读取”文本,然后自然语言处理功能可以理解它。
OCR 是处理图像中的文本的基础,并使用经过训练的机器学习模型将各个形状识别为字母、数字、标点符号或其他文本元素。 邮政服务执行了此类功能的早期工作,以支持基于邮政编码自动对邮件进行排序。 从那时起,阅读文本的最先进的模型已经继续,我们有模型检测图像中的打印或手写文本,并逐行阅读和逐字阅读。

Azure AI 视觉的 OCR 引擎
Azure AI 视觉服务能够从图像中提取计算机可读文本。 Azure AI 视觉 读取 API 是支持从图像、PDF 和 TIFF 文件提取文本的 OCR 引擎。 针对图像的 OCR 针对常规的非文档图像进行了优化,可更轻松地在用户体验方案中嵌入 OCR。
读取 API(也称为 读取 OCR 引擎)使用最新的识别模型,并且针对具有大量文本或具有相当视觉干扰的图像进行优化。 它可以自动确定适当的识别模型,以考虑文本行数、包含文本的图像和手写。
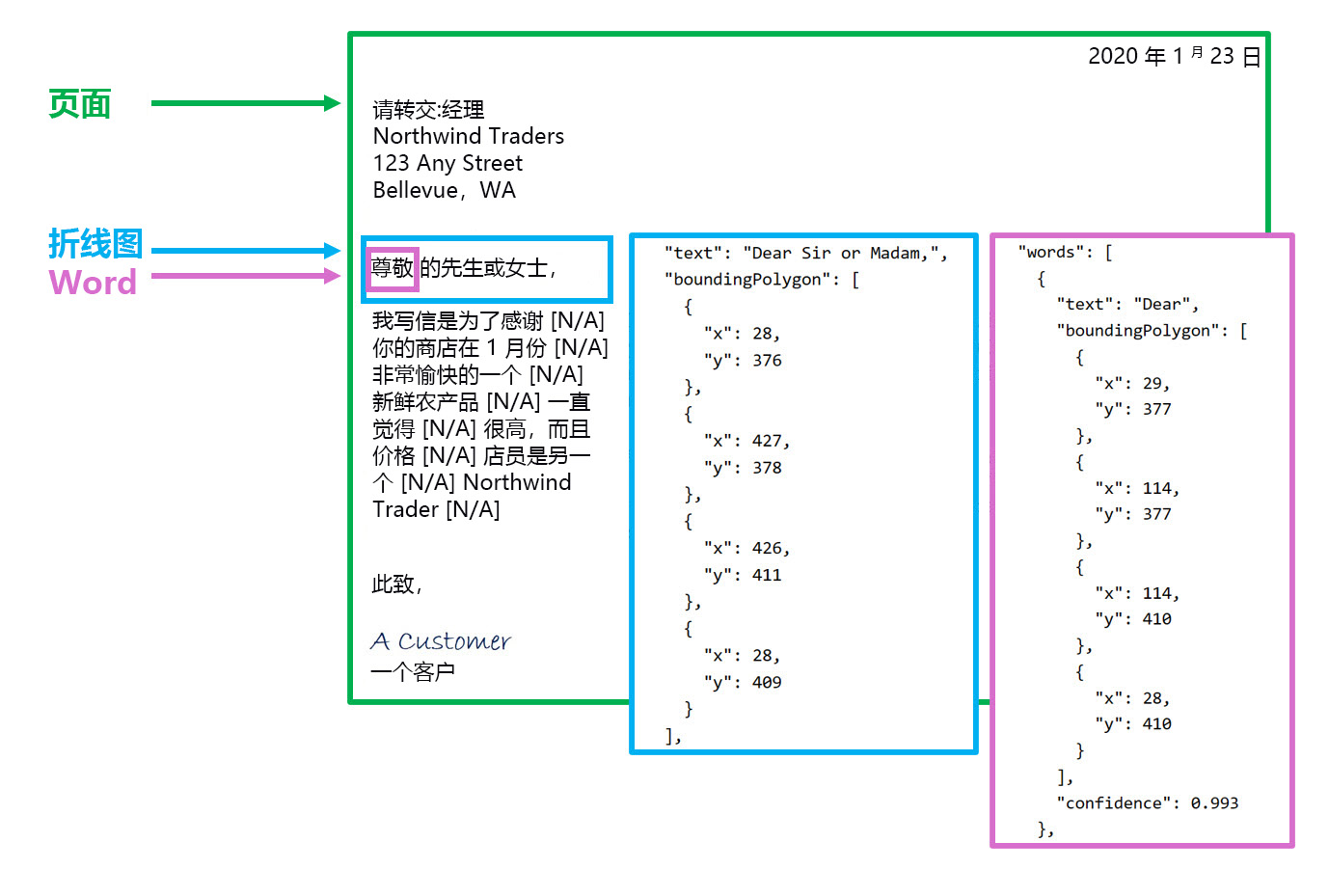
OCR 引擎采用图像文件并标识边界框或坐标,其中项位于图像中。 在 OCR 中,模型标识图像中看似文本的任何内容周围的边界框。
调用读取 API 将返回排列为以下层次结构的结果:
- Pages - 每页文本的一页,包括有关页面大小和方向的信息。
- 行 - 页面上的文本行。
- 单词 - 文本行中的单词,包括边界框坐标和文本本身。
每行和单词都包含表示其位置在页面上的边界框坐标。