浏览 RAG 工作流的主要概念
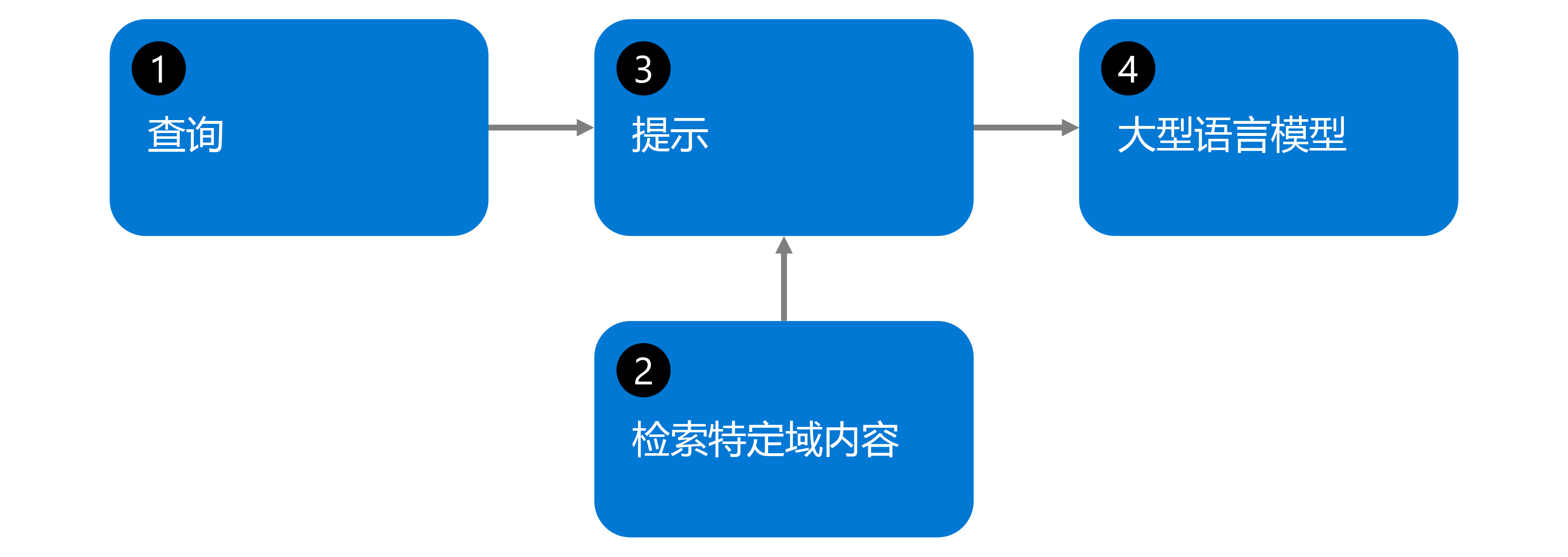
检索扩充生成(RAG) 是一种技术,通过将它们连接到自己的自定义数据,使大型语言模型更加有效。 RAG 工作流遵循一个简单的四步过程,如下图所示:
 检索增强生成工作流的关系图。
检索增强生成工作流的关系图。
用户查询:用户提出的问题,单靠基础语言模型无法准确回答,因为它无权访问您的特定文档、最新信息或专有数据。
搜索数据库:系统通过自己的文档集合(公司策略、报表、手册、数据库)进行搜索 - 而不是 LLM 的培训数据。 文档以前已转换为向量嵌入,并存储在向量数据库中。 系统从特定文档中查找最相关的信息。
将上下文添加到提示:从文档检索到的相关信息与用户的原始问题相结合,以创建增强提示,为 LLM 提供所需的特定上下文。
LLM 生成响应:基础语言模型处理原始问题以及从文档中检索的上下文,基于您的特定数据生成准确且可靠的回答。
此过程弥合了通用 LLM 与特定、专用或最新信息之间的差距,使你可以根据自己的文档获取准确的答案,而无需重新训练整个基本模型。
让我们看看何时可以使用 RAG,然后在 RAG 工作流中查看主要组件和概念。
了解何时可以使用 RAG
可以将 RAG 用于聊天机器人、搜索增强功能以及内容创建和摘要。
聊天机器人:RAG 通过访问当前信息帮助聊天机器人提供更准确的答案。 与客户支持系统集成后,RAG 支持的聊天机器人可以使用 up-to日期数据自动执行支持并快速解决客户问题。
搜索增强功能:RAG 支持的搜索引擎提供完整的对话答案,而不是仅返回链接和代码片段。 用户获得综合来自多个源的信息的综合响应,从而轻松找到所需的信息。
内容创建和摘要:使用自己的数据源生成高质量的基于事实的内容。 利用 RAG,可以生成知情的文章、从冗长的文档中创建摘要,并开发从多个源合成信息的报表。
浏览 RAG 工作流中的主要概念
RAG 工作流基于四个协同工作的基本组件构建:
- 嵌入 - 将文本转换为捕获含义的数学向量
- 矢量数据库 - 存储和组织这些矢量以快速搜索
- 搜索和检索 - 基于用户查询查找最相关的信息
- 提示扩充 - 将检索的信息与原始问题结合起来
将这些组件视为构建基块:嵌入内容将一切转换为公共语言,矢量数据库组织此信息,搜索和检索查找所需的内容,并提示扩充将所有内容组合在一起供 AI 使用。
使用嵌入转换文档和查询
在 RAG 系统找到相关信息之前,它需要将文档和用户查询中的所有文本转换为允许语义比较的格式。 嵌入就是在这个时候派上用场的。
嵌入模型是一种专用的 AI 工具,可将文本转换为数字向量(数字列表),以表示文本的含义。 将其视为将工作和句子转换为计算机可以理解和比较的数学语言的翻译器。
文档嵌入(如图所示)是准备阶段的一部分。 这只需要完成一次即可设置知识库。 在 RAG 系统正常工作之前,需要准备文档。 嵌入模型采用所有文本文档,并将其转换为称为嵌入的数学向量,以捕获其语义含义。 此预处理步骤创建可搜索的知识库。
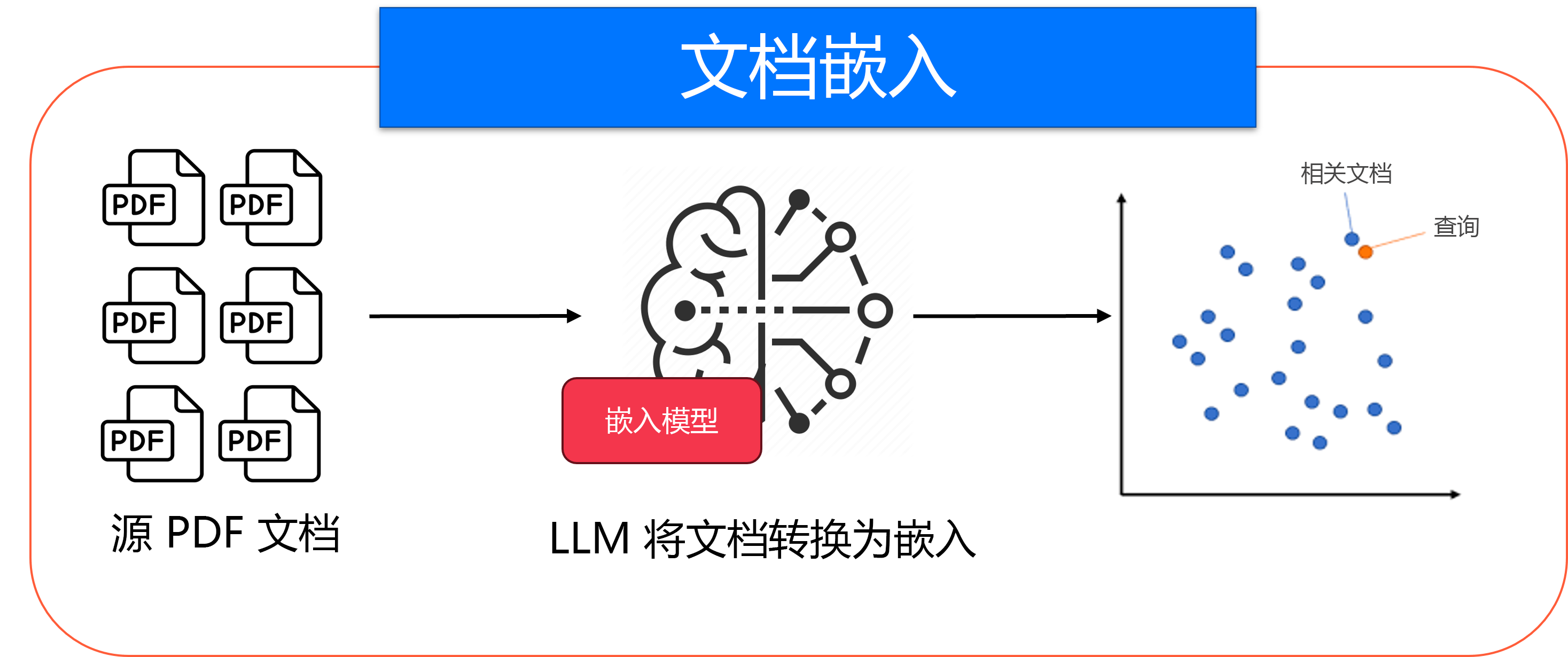 嵌入模型会将文档转换为矢量的关系图。
嵌入模型会将文档转换为矢量的关系图。
每次用户提出问题时,都会进行查询嵌入(如图所示)。 首先,将用户的问题转换为嵌入,使用与处理文档时相同的嵌入模型。 此实时转换将查询准备好,以便与已预处理的文档嵌入进行比较。 只有在嵌入查询后,系统才能开始搜索相关文档。
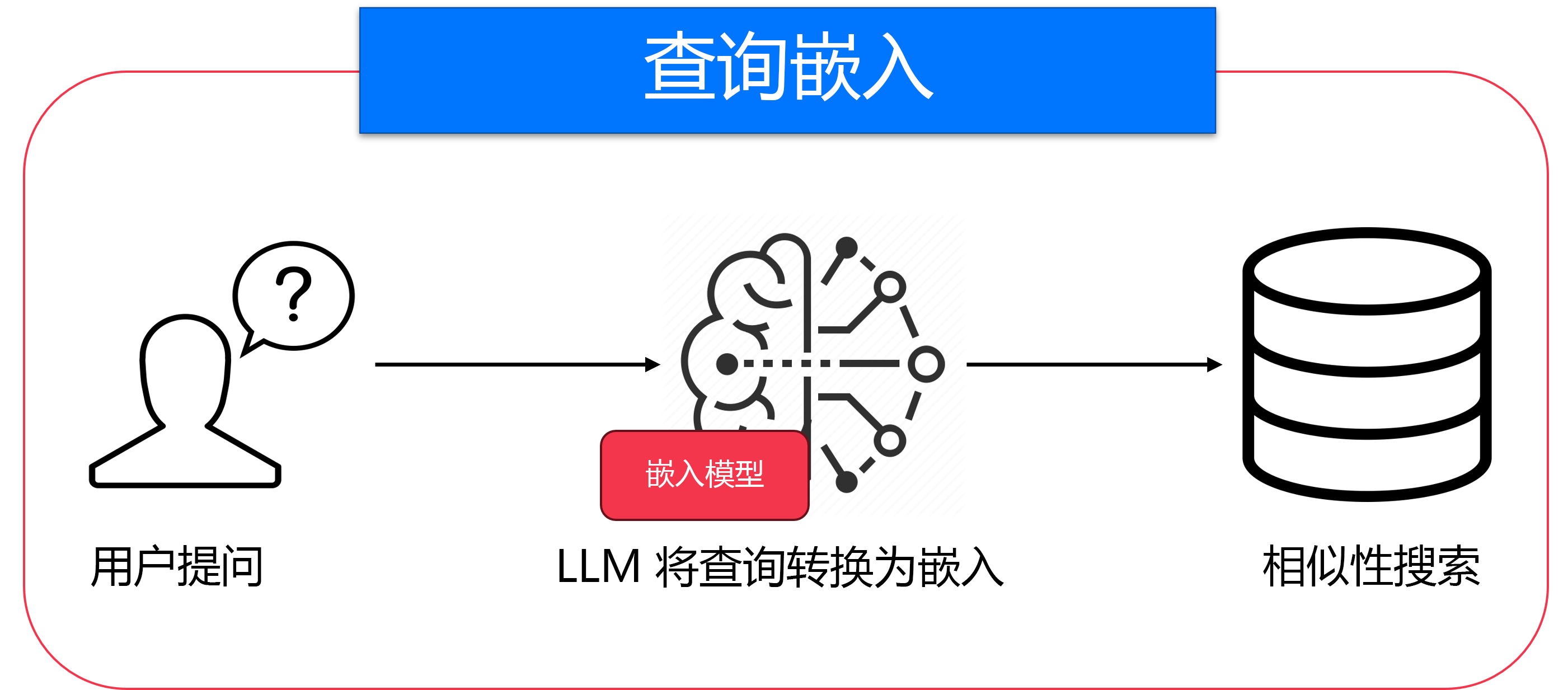 嵌入式模型的关系图。
嵌入式模型的关系图。
将嵌入的文档视为构建可搜索的库,并将嵌入的查询视为将每个问题翻译为相同的格式,以便可以在该库中找到正确的书籍。 问题翻译完成 后,搜索才开始。
使用矢量存储对嵌入内容进行存储和搜索
将文档转换为嵌入后,需要一个位置来存储它们,以便快速进行语义搜索。 常规数据库会为此而苦苦挣扎,因为它无法有效地比较矢量之间的数学相似性。
矢量存储是一个专用数据库,专为通过嵌入(从文档创建的数学向量)进行存储和搜索而设计。 与传统存储文本或数字的数据库不同,即使处理数百万个文档,矢量存储也经过优化,以便快速查找类似的向量。
可以通过 矢量数据库、 矢量库或 数据库插件实现矢量存储。
矢量存储启用语义搜索,这意味着它基于含义而不是完全匹配关键字来查找相关内容。 例如,搜索“休假”会查找有关“休假策略”的文档,即使确切的字词不匹配。 搜索时,可以应用筛选器预查询、期间查询或后查询。
通过检索的内容增强你的提示
找到最相关的文档后,RAG 系统将此信息与用户的原始问题相结合,以创建一个“扩充提示”,为 LLM 提供准确答案所需的一切。
扩充过程如下所示:
- 从用户的问题开始:“我们的度假策略是什么?
- 添加检索的上下文:包括 HR 文档中的相关摘录
- 创建扩充式提示:“根据这些 HR 策略文档:[检索内容],我们的休假策略是什么?”LLM 现在同时包含用户的问题和准确回答所需的具体信息。 这称为“上下文学习”,因为 LLM 从提示中提供的上下文中学习,而不是从其原始训练数据中学习。
在最后一步中,扩充式提示将发送到大型语言模型(LLM),该模型基于问题和检索的信息生成响应。 LLM 可以包含原始来源的引文,允许用户验证信息的来源。
RAG 工作流的主要好处是,它为你提供准确的源支持答案,而无需重新训练特定文档上的整个语言模型。
RAG 体系结构概述
完整的 RAG 工作流将我们回顾的所有组件合并为一个统一系统,将通用型 LLM 转变为特定领域的知识丰富的助手。
关键机制是 上下文学习 - 而不是重新训练 LLM,而是在每个提示中作为上下文提供相关信息,使 LLM 在不需要进行永久修改的情况下生成合理的响应。
当初始响应不满足质量阈值时,高级实现可能包括反馈循环来优化结果。