存储库和基于主干的开发
许多数据科学家更喜欢使用 Python 或 R 来定义机器学习工作负载。 可使用 Jupyter Notebook 或脚本来准备数据或训练模型。
使用源代码管理时处理任何代码资产都会变得更加容易。 源代码管理是管理代码和跟踪团队对代码所做的任何更改的做法。
如果使用 Azure DevOps 或 GitHub 等 DevOps 工具,代码将存储在所谓的存储库中。
存储库
设置 MLOps 框架时,机器学习工程师可能会创建存储库。 无论是选择使用 Azure DevOps 中的 Azure Repos 还是选用 GitHub 存储库,都是用 Git 存储库来存储代码。
通常有两种方法来限定存储库的范围:
- 单存储库:将所有机器学习工作负载保存在同一存储库中。
- 多存储库:为每个新的机器学习项目创建单独的存储库。
团队倾向于使用哪种方法取决于谁应有权访问哪些资产。 如果要确保可以快速访问所有代码资产,单存储库可能更符合团队的要求。 如果希望仅在人员正在参与项目时才向其提供访问项目的权限,团队可能会更倾向于使用多存储库。 请记住,管理访问控制可能会产生更多的开销。
整理你的存储库
无论采用哪种方法,最佳做法是就项目的标准顶级文件夹结构达成一致。 例如,你可能在你的所有存储库中具有以下文件夹:
.cloud:包含特定于云的代码,例如用于创建 Azure 机器学习工作区的模板。.ad/.github:包含 Azure DevOps 或 GitHub 工件,例如用于自动化工作流的 YAML 管道。src:包含用于机器学习工作负载(如预处理数据或模型训练)的任何代码(Python 或 R 脚本)。docs:包含用于描述项目的任何 Markdown 文件或其他文档。pipelines:包含 Azure 机器学习管道定义。tests:包含用于检测代码中错误和问题的单元测试和集成测试。notebooks:包含 Jupyter笔记本,主要用于实验。
注意
训练数据不应包含在存储库中。 数据应存储在数据库或数据湖中。 Azure 机器学习可以通过将连接信息存储为数据存储来直接访问数据库或数据湖。
通过提供一个所有项目均使用的标准结构,数据科学家和其他协作者会发现更容易找到他们需要处理的代码。
提示
查找更多构建数据科学项目的最佳做法。
若要了解如何以数据科学家的身份使用存储库,你将了解基于主干的开发。
基于分支的开发
大多数软件开发项目都使用 Git 作为源代码管理系统,Azure DevOps 和 GitHub 均这样使用。
使用 Git 的主要好处是轻松实现代码协作,同时跟踪所做的任何更改。 此外,你可以添加审批入口,以确保只有经过查看并接受的更改才会应用于生产代码。
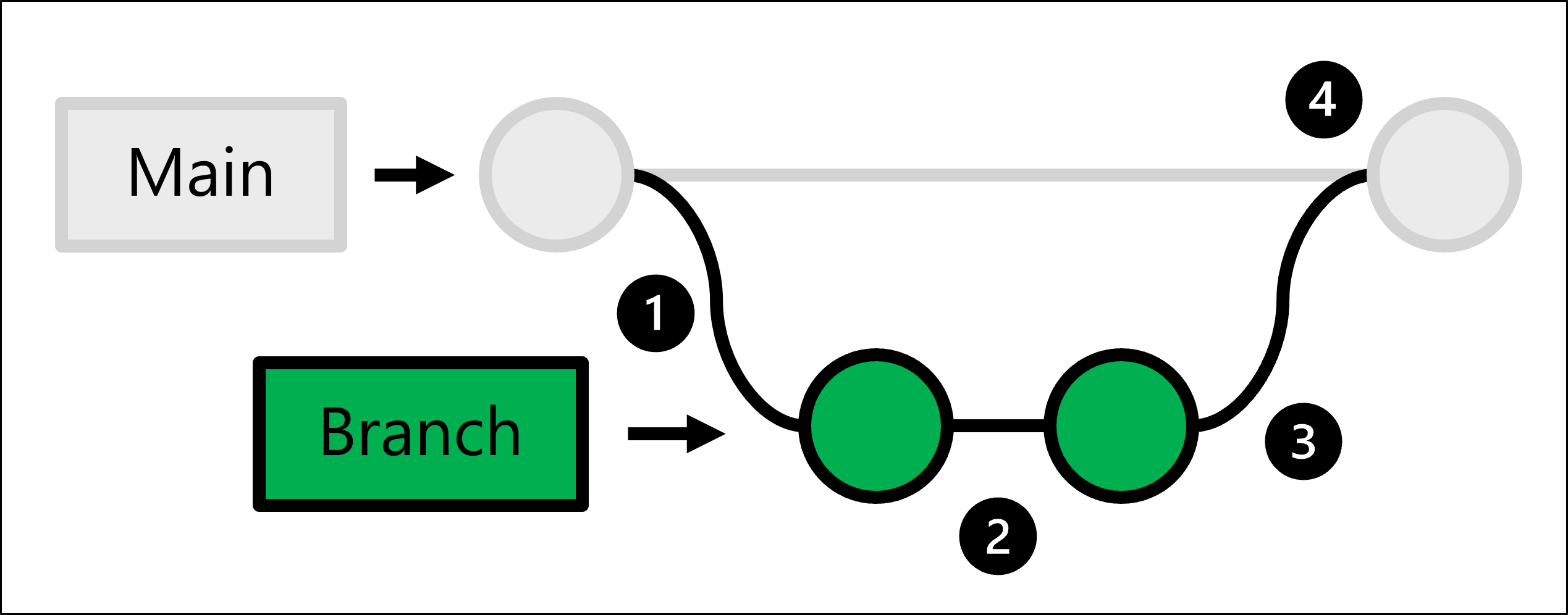
为满足上述要求,Git 使用了基于主干的开发,从而让你可以创建分支。
生产代码托管在主分支中。 每当有人要进行更改时:
- 通过创建分支来创建生产代码的完整副本。
- 在创建的分支中,进行任何更改并对其进行测试。
- 分支中的更改准备就绪后,可以要求某人查看更改。
- 如果更改已获批准,请将创建的分支与主存储库合并,生产代码将更新以反映所做的更改。