在本地验证代码
每当更改机器学习项目中的任何代码时,都需要验证代码和模型质量。
在持续集成期间,需要为应用程序创建和验证资产。 作为数据科学家,你可能专注于创建用于准备数据和训练模型的脚本。 机器学习工程师稍后在管道中使用这些脚本来自动执行这些过程。
有两个常用任务用于验证脚本:
- Lint 分析:检查 Python 或 R 脚本中的任何编程或样式错误。
- 单元测试:检查脚本内容的性能。
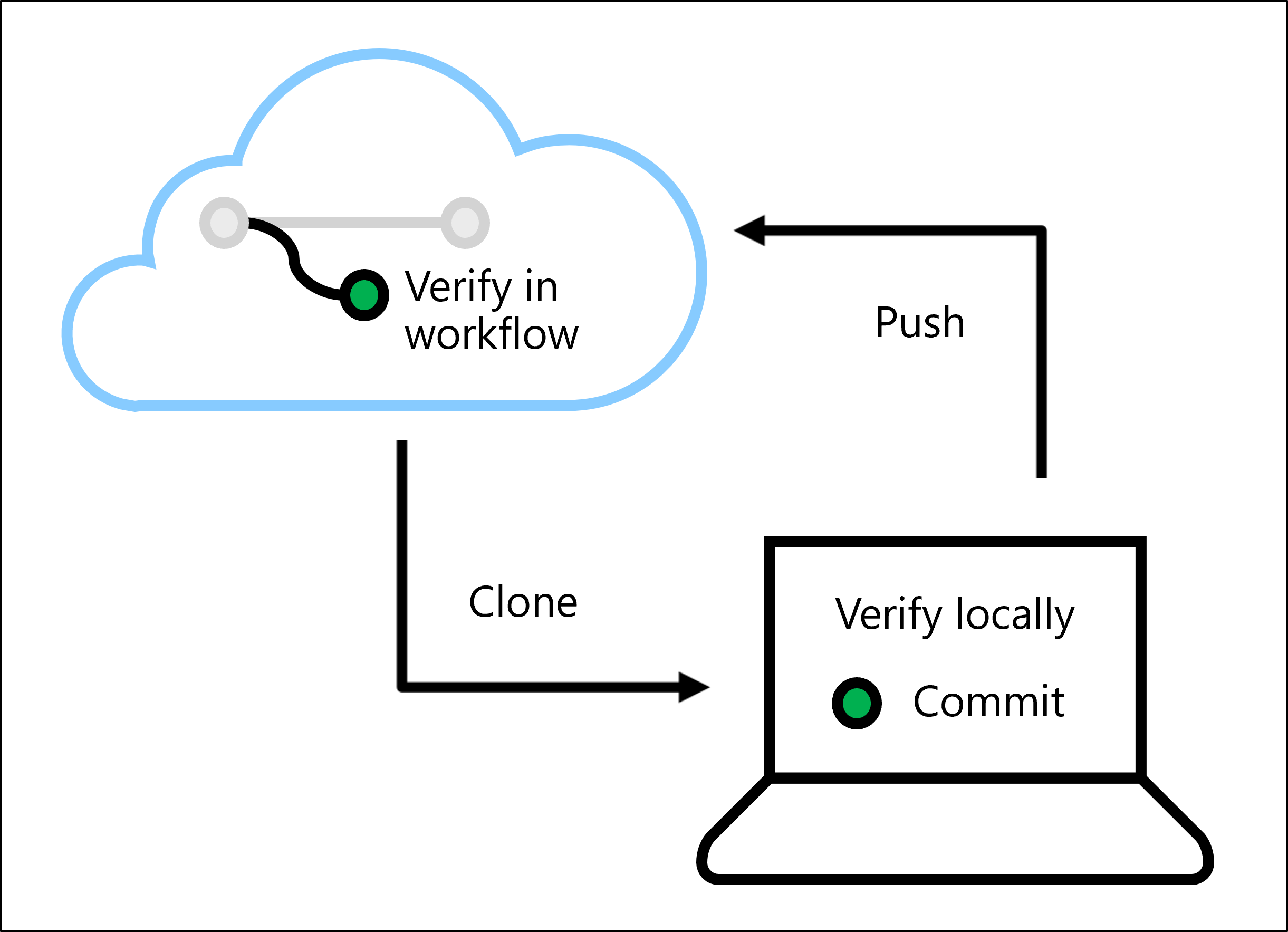
通过验证代码,可以阻止部署模型时出现 bug 或问题。 可以在本地验证代码,方法是在 IDE(例如 Visual Studio Code)中本地运行 Linter 和单元测试。
还可以使用 Azure Pipelines 或 GitHub Actions 在自动化工作流中运行 Linter 和单元测试。
你将了解如何在 Visual Studio Code 中运行 Lint 分析和单元测试。
对代码进行 Lint 分析
代码的质量取决于你和团队商定的标准。 为确保达到商定的质量,可以运行 Linter 来检查代码是否符合团队的标准。
根据所使用的代码语言,有多个选项可用于对代码进行 Lint 分析。 例如,如果使用 Python,则可以使用 Flake8 或 Pylint。
使用 Flake8 对代码进行 Lint 分析
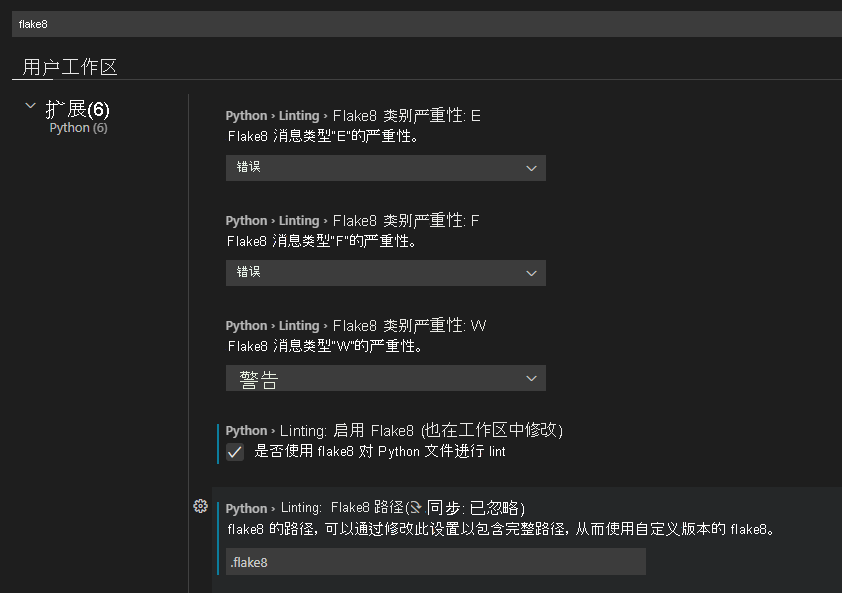
通过 Visual Studio Code 在本地使用 Flake8:
- 使用
pip install flake8安装 Flake8。 - 创建配置文件
.flake8并将该文件存储在存储库中。 - 通过转到设置 (
Ctrl+,),将 Visual Studio Code 配置为使用 Flake8 作为 Linter。 - 搜索
flake8。 - 启用“Python”>“Lint 分析”>“Flake8 已启用”。
- 将 Flake8 路径设置为存储库中存储
.flake8文件的位置。
若要指定团队的代码质量标准,可以配置 Flake8 Linter。 定义标准的常用方法是创建随代码一起存储的 .flake8 文件。
该 .flake8 文件应以 [flake8] 开头,后跟要使用的任何配置。
提示
可以在 Flake8 文档中找到可能的配置参数的完整列表。
例如,如果要指定任何行的最大长度不能超过 80 个字符,则将以下行添加到 .flake8 文件:
[flake8]
max-line-length = 80
Flake8 具有一个预定义列表,其中包含其可能返回的错误。 此外,还可以使用基于 PEP 8 样式指南的错误代码。 例如,可以包含有关正确使用缩进或空格的错误代码。
可以从以下两种做法中进行选择:选择 (select) 一组将包含在 Linter 中的错误代码,或从默认选项列表中选择要忽略 (ignore) 的错误代码。
因此,.flake8 配置文件可能如下所示:
[flake8]
ignore =
W504,
C901,
E41
max-line-length = 79
exclude =
.git,
.cache,
per-file-ignores =
code/__init__.py:D104
max-complexity = 10
import-order-style = pep8
提示
有关可参考的错误代码的概述,请查看 Flake8 错误列表
将 Visual Studio Code 配置为对代码进行 Lint 分析时,可以打开任何代码文件以查看 Lint 结果。 任何警告或错误都将带有下划线。 可以选择“查看问题”以检查问题并了解错误。

使用 Azure Pipelines 或 GitHub Actions 进行 Lint 分析
还可以使用 Azure Pipelines 或 GitHub Actions 自动运行 Linter。 任一平台提供的代理都将在以下情况下运行 Linter:
- 创建配置文件
.flake8并将该文件存储在存储库中。 - 在 YAML 中定义持续集成管道或工作流。
- 在其中一个任务或步骤中,使用
python -m pip install flake8安装 Flake8。 - 在其中一个任务或步骤中,运行
flake8命令以对代码进行 Lint 分析。
单元测试
在 Lint 分析验证编写代码的方式时,单元测试会检查代码的工作方式。 单元是指所创建的代码。 因此,单元测试也称为代码测试。
最佳做法是,代码应主要存在于函数外。 无论创建的函数是用于准备数据,还是训练模型。 例如,可以将单元测试应用于以下操作:
- 检查列名是否正确。
- 检查新数据集上模型的预测级别。
- 检查预测级别的分布。
使用 Python 时,可以使用 Pytest 和 Numpy(使用 Pytest 框架)来测试代码。 若要详细了解如何使用 Pytest,请了解如何使用 Pytest 编写测试。
提示
查看有关 Visual Studio Code 中的 Python 测试的更详细的演练。
假设你创建了一个训练脚本 train.py,其中包含以下函数:
# Train the model, return the model
def train_model(data, ridge_args):
reg_model = Ridge(**ridge_args)
reg_model.fit(data["train"]["X"], data["train"]["y"])
return reg_model
假设你将训练脚本存储在存储库的 src/model/train.py 目录下。 若要测试函数 train_model,必须从 src.model.train 中导入该函数。
在 test_train.py 文件夹中创建 tests 文件。 测试 Python 代码的一种方法是使用 numpy。 Numpy 提供了多个 assert 函数来比较数组、字符串、对象或项。
提示
详细了解使用 Numpy 测试时的测试指南和 Numpy 的测试支持。
例如,若要测试 train_model 函数,可以使用小型训练数据集,并使用 assert 来验证预测是否几乎等于预定义的性能指标。
import numpy as np
from src.model.train import train_model
def test_train_model():
X_train = np.array([1, 2, 3, 4, 5, 6]).reshape(-1, 1)
y_train = np.array([10, 9, 8, 8, 6, 5])
data = {"train": {"X": X_train, "y": y_train}}
reg_model = train_model(data, {"alpha": 1.2})
preds = reg_model.predict([[1], [2]])
np.testing.assert_almost_equal(preds, [9.93939393939394, 9.03030303030303])
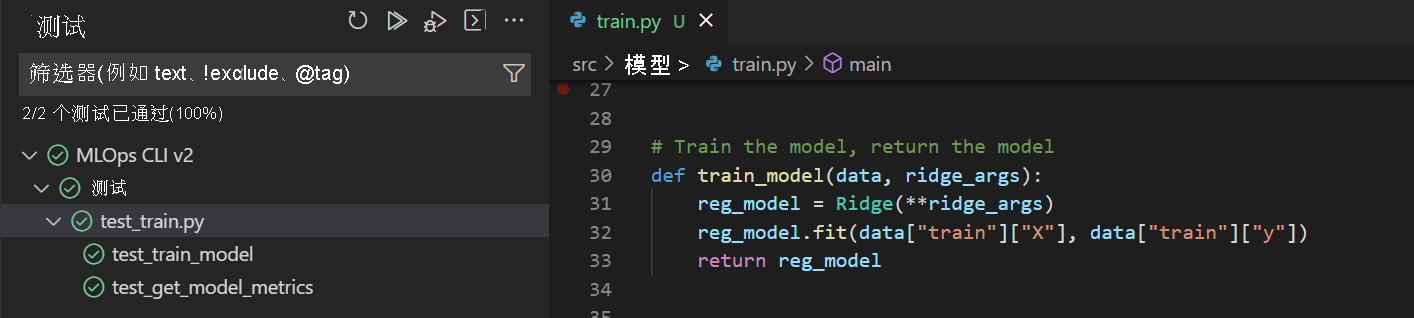
使用 UI 在 Visual Studio Code 中测试代码:
- 安装所有必要的库以运行训练脚本。
- 确保在 Visual Studio Code 内安装和启用
pytest。 - 安装 Visual Studio Code 的 Python 扩展。
- 选择要测试的
train.py脚本。 - 从左侧菜单中选择“测试”选项卡。
- 通过选择“pytest”并将测试目录设置为 文件夹来配置 Python 测试
tests/。 - 通过选择“播放”按钮并查看结果来运行所有测试。
在 Azure DevOps 管道或 GitHub Action 中运行测试:
- 确保安装所有必要的库以运行训练脚本。 理想情况下,使用
requirements.txt列出所有包含pip install -r requirements.txt的库 - 使用
pytest安装pip install pytest - 使用
pytest tests/运行测试
测试结果将显示在运行的管道或工作流的输出中。
注意
如果在 Lint 分析或单元测试期间返回了错误,CI 管道可能会失败。 因此,最好先在本地验证代码,然后再触发 CI 管道。