在笔记本中使用 Spark
可以在 Spark 上运行多种不同类型的应用程序,包括 Python 或 Scala 脚本中的代码、编译为 Java 存档 (JAR) 的 Java 代码等。 Spark 通常用于两种类型的工作负载:
- 用于引入、清理和转换数据的批处理或流式处理作业 - 通常作为自动化管道的一部分运行。
- 用于浏览、分析和直观呈现数据的交互式分析会话。
笔记本编辑和代码基础知识
Databricks 笔记本是数据科学、工程和分析的主要工作环境。 它们围绕单元格构建,可以包含代码或格式化文本(Markdown)。 这种基于单元的方法让你能够在一个位置轻松试验、测试和解释你的工作。 可以运行单个单元格、一组单元格或整个笔记本,其中输出(如表格、图表或纯文本)直接显示在执行单元格下方。 单元格可以重新排列、折叠或清除,以使笔记本保持有序且可读。
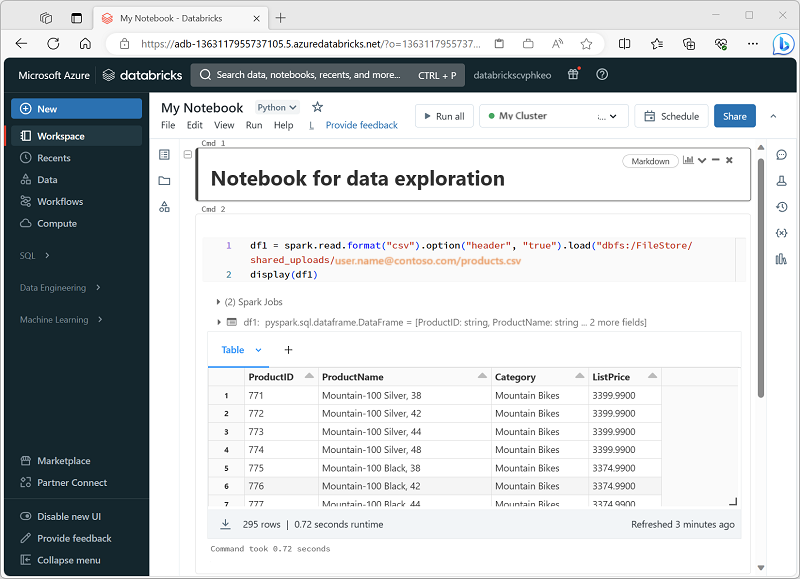
Databricks 笔记本的主要优势是多语言支持。 虽然默认值通常是 Python,但可以使用 magic 命令(如 %sql 或 %scala)切换到同一笔记本中的 SQL、Scala 或 R。 这种灵活性意味着可以在 SQL 中编写 ETL 逻辑,在 Python 中编写机器学习代码,然后使用 R 直观显示结果,所有这些作都在一个工作流中。 Databricks 还提供自动完成和语法突出显示功能,以便更轻松地捕获错误并加快编码速度。
在运行任何代码之前,笔记本必须附加到群集。 如果没有附加的群集,则无法运行代码单元。 可以从笔记本工具栏中选择现有群集或创建新的群集,并根据需要轻松分离和重新附加笔记本。 此连接允许笔记本利用 Azure Databricks 中的分布式处理能力。
使用 Databricks 助手
Databricks 助手是一个由 AI 提供支持的编码助手,直接内置于笔记本中。 其目标是利用笔记本和工作区中的上下文,帮助你更有效地编写、理解和改进代码。 它可以从自然语言提示生成新代码、解释复杂的逻辑、建议错误修复、优化性能,甚至重构代码或设置代码格式以获得可读性。 这使得它不仅对初学者学习 Spark 或 SQL 具有价值,而且对于想要加快开发和减少重复工作的经验丰富的用户来说也很有用。
该助手具有 上下文感知性,这意味着它可以使用有关笔记本、群集和数据环境的信息来提供定制的建议。 例如,如果工作区启用了 Unity 目录,则它可以在编写 SQL 查询时拉取表名、列名和架构等元数据。 这样,你可以询问“从销售表中按区域选择平均销售额”之类的问题,并获取符合实际数据模型的运行 SQL 代码。 同样,在 Python 中,可以要求它创建数据转换或 Spark 作业,而无需从内存中召回每个函数签名。
可通过两种主要方式与助手交互:
自然语言提示 - 可以在类似聊天的界面中键入纯英语说明,并将代码插入笔记本。
斜杠命令 - 快速命令,例如
/explain,/fix或/optimize允许你处理所选代码。 例如,/explain将复杂函数分解为更简单的步骤,/fix可以尝试解决语法或运行时错误,并/optimize建议性能改进,例如重新分区或使用高效的 Spark 函数。
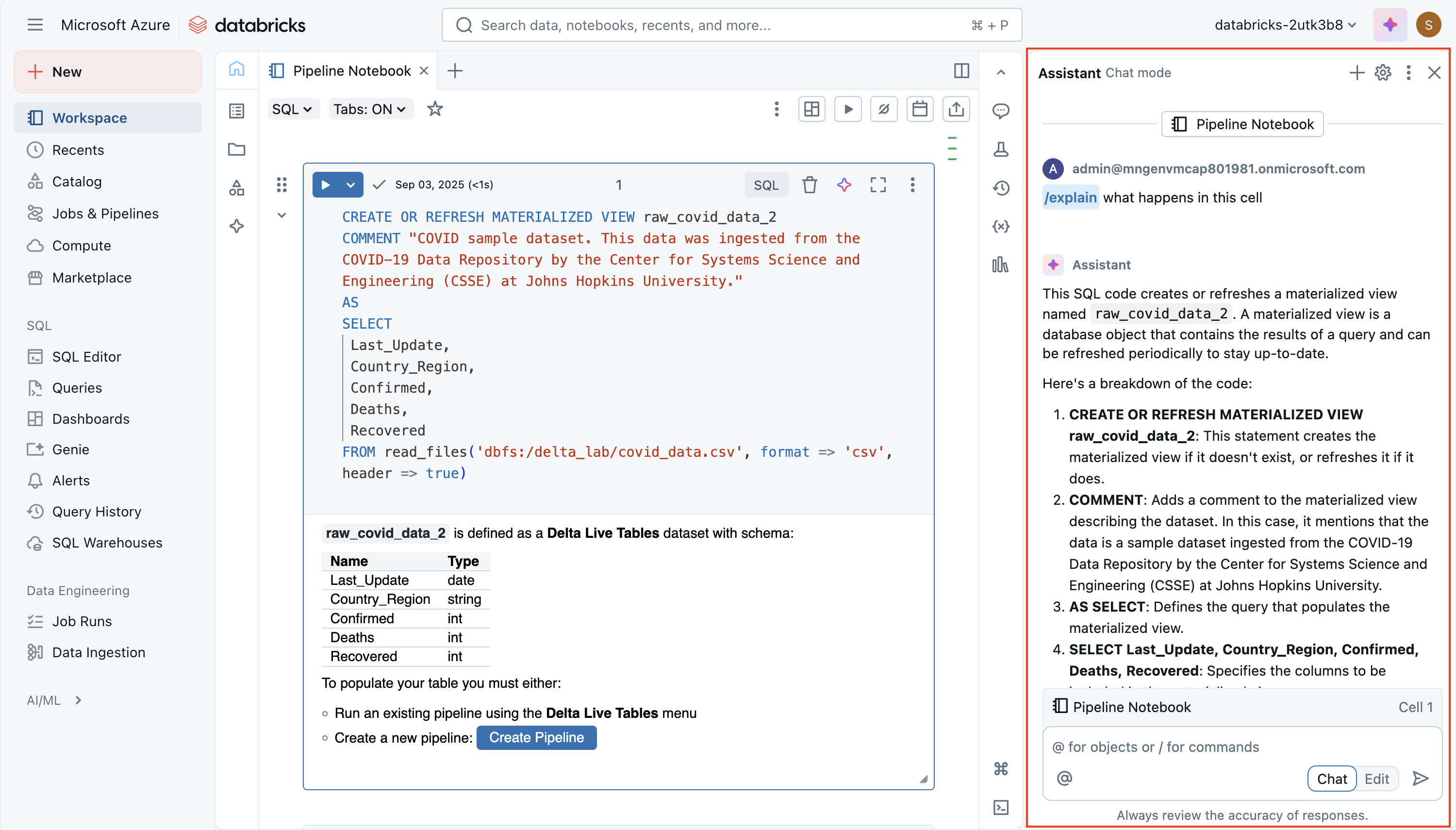
强大的功能是编辑模式,助手可以在多个单元格中提出更大的结构更改。 例如,它可以将重复逻辑重构到单个可重用函数或重构工作流,以提高可读性。 你始终具有控制权:建议是非破坏性的,这意味着你可以在将更改应用到笔记本之前查看和接受或拒绝它们。
共享和模块化代码
为避免重复并提高可维护性,Databricks 支持将可重用的代码保存到工作区的文件中(例如,.py模块),笔记本可以导入这些文件。 有一些机制可以协调笔记本(即,从其他笔记本运行笔记本或具有多个任务的作业),以便生成使用共享函数或模块的工作流。 不过,使用 %run 是包含另一个笔记本的更简单方法,但存在一些限制。
调试、版本历史记录和撤消错误
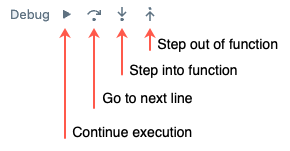
Databricks 为 Python 笔记本提供了一个内置的 交互式调试器 :可以设置断点、单步执行、检查变量,以及逐步浏览代码执行。 与打印/日志调试相比,这有助于更有效地隔离 bug。
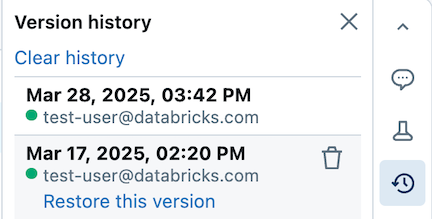
笔记本还自动维护版本历史记录:可以查看过去的快照、提供版本说明、还原旧版本或删除/清除历史记录。 如果使用 Git 集成,则可以在存储库中同步和版本化笔记本/文件。
提示
有关在 Azure Databricks 中使用笔记本的详细信息,请参阅 Azure Databricks 文档中的 Notebooks 文章。