可视化数据
分析数据查询结果的最直观的方法之一是将其可视化为图表。 Azure Databricks 中的笔记本在用户界面中提供了图表绘制功能,并且当无法通过该功能获取所需内容时,可以使用众多 Python 图形库之一在笔记本中创建和显示数据可视化效果。
使用内置的笔记本图表
在 Azure Databricks 的 Spark 笔记本中显示数据帧或运行 SQL 查询时,结果显示在代码单元下。 默认情况下,结果呈现为表格,但你也可以将结果呈现为可视化效果,并自定义图表的数据显示方式,如下所示:
可视化效果类型
这些是可以在 Databricks 中实现的不同类型的可视化效果,每种可视化效果都适用于某些类型的数据见解。 要点:
条形图/折线图/面积图:用于显示随时间推移的趋势、分类比较或两者。 了解指标的发展方式非常有用。
饼图:适合显示整个比例部分(但不适用于时序)。
直方图:查看数值数据的分布(值分布方式、聚集方式)。
热度地图:可用于可视化两个分类轴,并通过数值着色,有助于查看各组的模式。
散点/气泡图:显示两个(或更多)数值变量之间的关系;气泡允许将大小或颜色用作第三个维度。
箱线图:用于比较不同类别的数据分布(扩展、四分位数、离群值)。
组合图:在同一图表中混合折线图和柱状图,有助于比较具有不同刻度的不同指标。
数据透视表:允许你以表形式(如 SQL PIVOT/GROUP BY)重新定义和聚合数据,有助于交叉选项卡分析。
特殊类型:队列分析(随时间推移跟踪组)、计数器显示(突出显示单个摘要指标,可能对照目标)、漏斗图、地图可视化效果(地区分布、标记)、词云等。这些内容更为专业化。
若要快速直观地汇总数据,可以使用笔记本中内置的可视化效果功能。 如果想要更好地控制数据的格式设置方式或更好地显示查询中已聚合的值,应考虑使用图形包创建自己的可视化效果。
在代码中使用图形包
有许多图形包可用于在代码中创建数据可视化效果。 具体而言,Python 支持大量不同种类的包;其中大多数均基于基础 Matplotlib 库构建。 图形库的输出可以在笔记本中呈现,从而可以轻松将引入和操作数据的代码与内联数据可视化效果和标记单元格组合起来,以提供注释。
例如,可以使用以下 PySpark 代码对本模块前面探讨的假设产品数据进行聚合,并使用 Matplotlib 从聚合数据创建图表。
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Matplotlib 库要求数据位于 Pandas 数据帧而不是 Spark 数据帧中,因此使用了 toPandas 方法来转换数据帧。 然后代码创建一个具有指定大小的数字,并绘制具有一些自定义属性配置的条形图,然后显示生成的绘图。
代码生成的图表类似于下图:
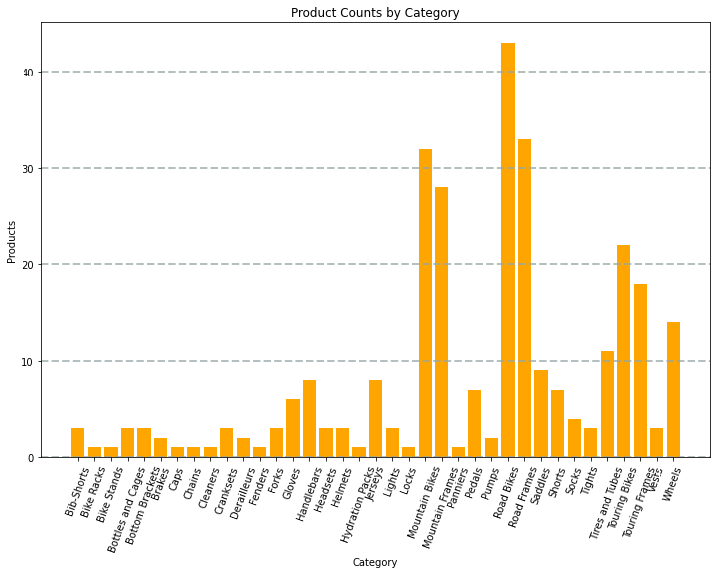
使用 Matplotlib 库可以创建多种图表:或如果需要,也可以使用其他库(如 Seaborn)创建高度自定义的图表。
注释
Matplotlib 和 Seaborn 库可能已在 Databricks 群集上安装,具体取决于群集的 Databricks Runtime。 如果没有,或者想要使用尚未安装的其他库,则可以将其添加到群集。 有关详细信息,请参阅 Azure Databricks 文档中的群集库。