使用 CREATE EXTERNAL TABLE AS SELECT 语句转换数据文件
SQL 语言包含许多可操作数据的功能和函数。 例如,可以使用 SQL 来:
- 筛选数据集中的行和列。
- 重命名数据字段并在数据类型之间进行转换。
- 计算派生的数据字段。
- 操作字符串值。
- 对数据进行分组和聚合。
Azure Synapse 无服务器 SQL 池可用于运行 SQL 语句,这些 SQL 语句会转换数据,并将结果保存为数据湖中的文件,供进一步处理或查询。 如果你熟悉 Transact-SQL 语法,可编写一个应用你感兴趣的特定转换的 SELECT 语句,并将 SELECT 语句的结果以选定的文件格式存储,其中包含可使用 SQL 查询的元数据表架构。
可以在专用 SQL 池或无服务器 SQL 池中使用 CREATE EXTERNAL TABLE AS SELECT (CETAS) 语句将查询结果保存到外部表中,该外部表将其数据存储在数据湖的文件中。
CETAS 语句包含一个 SELECT 语句,用于查询和操作来自任何有效数据源的数据(数据源可以是数据库中现有的表或视图,或者从数据湖读取基于文件的数据的 OPENROWSET 函数)。 SELECT 语句的结果随后保存在外部表中,该表是数据库中的元数据对象,它对存储在文件中的数据提供关系抽象。 下图直观说明了此概念:
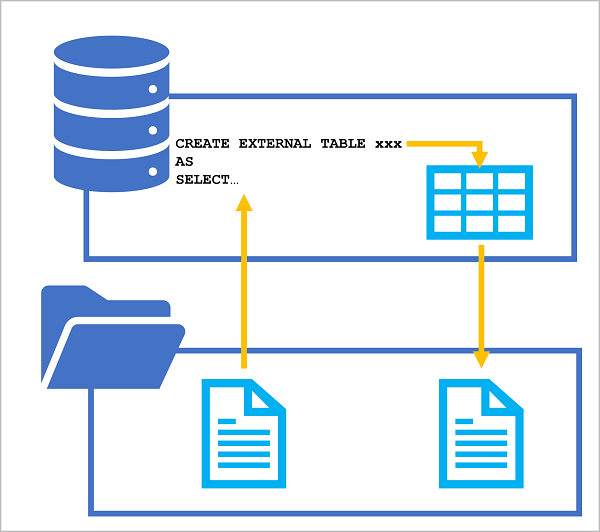
通过应用此方法,可以使用 SQL 从文件或表中提取和转换数据,并存储转换后的结果,以便进行下游处理或分析。 对转换后的数据的后续操作可针对 SQL 池数据库中的关系表执行,也可直接针对基础数据文件执行。
创建支持 CETAS 的外部数据库对象
要使用 CETAS 表达式,必须在数据库中为无服务器或专用 SQL 池创建以下类型的对象。 当使用无服务器 SQL 池时,在自定义数据库(使用 CREATE DATABASE 语句创建)中创建这些对象,而不是在内置数据库中创建。
外部数据源
外部数据源将连接封装到数据湖中的文件系统位置。 然后,可使用此连接指定一个相对路径,其中保存由 CETAS 语句创建的外部表的数据文件。
如果 CETAS 语句的源数据位于相同数据湖路径中的文件中,则可以在用于查询它的 OPENROWSET 函数中使用相同的外部数据源。 或者,可以为源文件创建单独的外部数据源,或者在 OPENROWSET 函数中使用完全限定的文件路径。
要创建外部数据源,请使用 CREATE EXTERNAL DATA SOURCE 语句,如下例所示:
-- Create an external data source for the Azure storage account
CREATE EXTERNAL DATA SOURCE files
WITH (
LOCATION = 'https://mydatalake.blob.core.windows.net/data/files/',
TYPE = HADOOP, -- For dedicated SQL pool
-- TYPE = BLOB_STORAGE, -- For serverless SQL pool
CREDENTIAL = storageCred
);
前面的示例假定运行使用外部数据源的查询的用户将有足够的权限访问文件。 另一种方法是将凭证封装在外部数据源中,以便它可以用于访问文件数据,而无需授予所有用户直接读取它的权限:
CREATE DATABASE SCOPED CREDENTIAL storagekeycred
WITH
IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=xxx...';
CREATE EXTERNAL DATA SOURCE secureFiles
WITH (
LOCATION = 'https://mydatalake.blob.core.windows.net/data/secureFiles/'
CREDENTIAL = storagekeycred
);
提示
除了 SAS 身份验证之外,还可以定义使用“托管标识”(Azure Synapse 工作区使用的 Microsoft Entra 标识)、特定 Microsoft Entra 主体的凭据,或者基于运行查询的用户标识(这是默认类型的身份验证)的直通身份验证。 若要了解有关在无服务器 SQL 池中使用凭据的详细信息,请参阅 Azure Synapse Analytics 文档中的 在 Azure Synapse Analytics 中的无服务器 SQL 池中控制存储帐户访问 一文。
外部文件格式
CETAS 语句会创建一个表,其数据存储在文件中。 必须将要创建的文件的格式指定为外部文件格式。
要创建外部文件格式,请使用 CREATE EXTERNAL FILE FORMAT 语句,如以下示例所示:
CREATE EXTERNAL FILE FORMAT ParquetFormat
WITH (
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
);
提示
在此示例中,文件将以 Parquet 格式保存。 还可以为其他类型的文件创建外部文件格式。 有关详细信息,请参阅 CREATE EXTERNAL FILE FORMAT (Transact-SQL)。
使用 CETAS 语句
创建外部数据源和外部文件格式后,可以使用 CETAS 语句转换数据并将结果存储在外部表中。
例如,假设要转换的源数据由销售订单组成,这些订单以逗号分隔的文本文件存储在数据湖的文件夹中。 你想要筛选数据以仅包含标记为“特殊订单”的订单,并将转换后的数据作为 Parquet 文件保存在同一数据湖的不同文件夹中。 可以为源文件夹和目标文件夹使用相同的外部数据源,如以下示例所示:
CREATE EXTERNAL TABLE SpecialOrders
WITH (
-- details for storing results
LOCATION = 'special_orders/',
DATA_SOURCE = files,
FILE_FORMAT = ParquetFormat
)
AS
SELECT OrderID, CustomerName, OrderTotal
FROM
OPENROWSET(
-- details for reading source files
BULK 'sales_orders/*.csv',
DATA_SOURCE = 'files',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE
) AS source_data
WHERE OrderType = 'Special Order';
上例中的 LOCATION 和 BULK 参数分别是结果文件和源文件的相对路径。 路径相对于文件外部数据源引用的文件系统位置。
需了解的一个要点是,必须使用外部数据源来指定保存外部表转换后的数据的位置。 当基于文件的源数据存储在同一文件夹层次结构中时,可以使用同一外部数据源。 否则,可使用第二个数据源来定义与源数据的连接或使用完全限定的路径,如以下示例所示:
CREATE EXTERNAL TABLE SpecialOrders
WITH (
-- details for storing results
LOCATION = 'special_orders/',
DATA_SOURCE = files,
FILE_FORMAT = ParquetFormat
)
AS
SELECT OrderID, CustomerName, OrderTotal
FROM
OPENROWSET(
-- details for reading source files
BULK 'https://mystorage.blob.core.windows.net/data/sales_orders/*.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE
) AS source_data
WHERE OrderType = 'Special Order';
删除外部表
如果不再需要包含已转换的数据的外部表,可使用 DROP EXTERNAL TABLE 语句将其从数据库中删除,如下所示:
DROP EXTERNAL TABLE SpecialOrders;
但是,必须了解外部表是包含实际数据的文件上的元数据抽象。 删除外部表不会删除基础数据。