本文提供故障后恢复Microsoft Azure Kubernetes 服务(AKS)群集节点的故障排除步骤。 本文专门介绍了在节点未就绪故障发生时生成的最常见错误消息,并说明了如何为 Windows 和 Linux 节点执行节点修复功能。
开始之前
阅读有关 Kubernetes 群集故障排除的官方指南。 此外,请阅读 Microsoft 工程师的 Kubernetes 故障排除指南。 本指南包含用于对 Pod、节点、群集和其他功能进行故障排除的命令。
先决条件
-
Azure CLI 版本 2.31 或更高版本。 如果已安装 Azure CLI,可以通过运行
az --version找到版本号。
基本故障排除
AKS 持续监视工作器节点的运行状况,并在 节点运行不正常时自动修复 节点。 Azure 虚拟机(VM)平台 维护遇到问题的 VM 。 AKS 和 Azure VM 协同工作,以减少群集的服务中断次数。
对于节点,有两种形式的检测信号:
更新对象的 .status
Node。kube-node-lease 命名空间中的 Lease 对象。 每个
Node对象都有一个关联的Lease对象。
与更新到 Node 相比,a Lease 是一种轻型资源。 对检测信号使用 Lease 对象可降低这些更新对大型群集的性能影响。
kubeletNode 它还负责更新 Lease 与 Node 对象相关的对象。
- 当状态发生更改或配置间隔没有更新时,kubelet 会更新节点
.status。 节点更新的默认间隔.status为 5 分钟,这比不可访问节点的 40 秒默认超时时间要长得多。 - kubelet 创建并每隔 10 秒更新一次对象
Lease(默认更新间隔)。Lease更新独立于节点.status的更新进行。Lease如果更新失败,kubelet 会重试,使用指数回退以 200 毫秒开始,上限为 7 秒。
不能在状态为 NotReady 或 Unknown. 的节点上计划 Pod。 只能在处于状态的 Ready 节点上计划 Pod。
如果节点处于MemoryPressure或DiskPressurePIDPressure状态,则必须管理资源,才能在节点上计划额外的 Pod。 如果节点处于 NetworkUnavailable 模式,则必须正确配置节点上的网络。
AKS 为你管理代理节点的生命周期和操作。 不支持修改与代理节点关联的 IaaS 资源。 例如,不支持通过 SSH 连接自定义节点、更新包或更改节点上的网络配置。 有关详细信息,请参阅 代理节点的 AKS 支持覆盖范围。
确保满足以下条件:
群集处于 “成功”(正在运行) 状态。 若要检查Azure 门户上的群集状态,请搜索并选择 Kubernetes 服务,然后选择 AKS 群集的名称。 然后,在群集的“概述”页上,在“概要”中查找状态。 或者,在 Azure CLI 中输入 az aks show 命令。
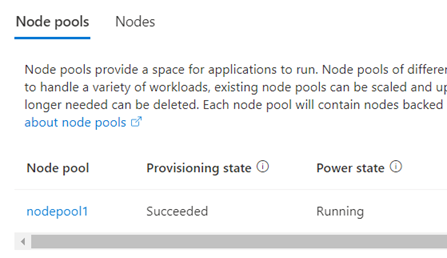
节点池的 预配状态 为 “成功” ,电源 状态 为 “正在运行”。 若要检查Azure 门户上的节点池状态,请返回到 AKS 群集的页面,然后选择“节点池”。 或者,在 Azure CLI 中输入 az aks nodepool show 命令。
所需的出口端口在网络安全组(NSG)和防火墙中打开,以便可以访问 API 服务器的 IP 地址。 有关详细信息,请参阅 AKS 群集所需的出站网络规则和 FQDN。
节点 已部署最新的节点映像。
节点处于
Running状态,而不是Stopped或Deallocated。群集运行的 是 Kubernetes 的 AKS 支持版本。
详细信息
若要排查 Not Ready 节点的状态问题,请参阅 “排查正常节点的更改”更改为“未就绪”状态的问题。
第三方联系人免责声明
Microsoft 会提供第三方联系信息来帮助你查找有关本主题的其他信息。 此联系信息可能会更改,恕不另行通知。 Microsoft 不保证第三方联系信息的准确性。