本文介绍有助于排查应用程序相关问题的 Azure Monitor Application Insights 功能。
注意
本文适用于经典云服务和云服务扩展支持。
为云服务应用配置 Application Insights
若要使用 Application Insights 监视应用,请执行以下步骤:
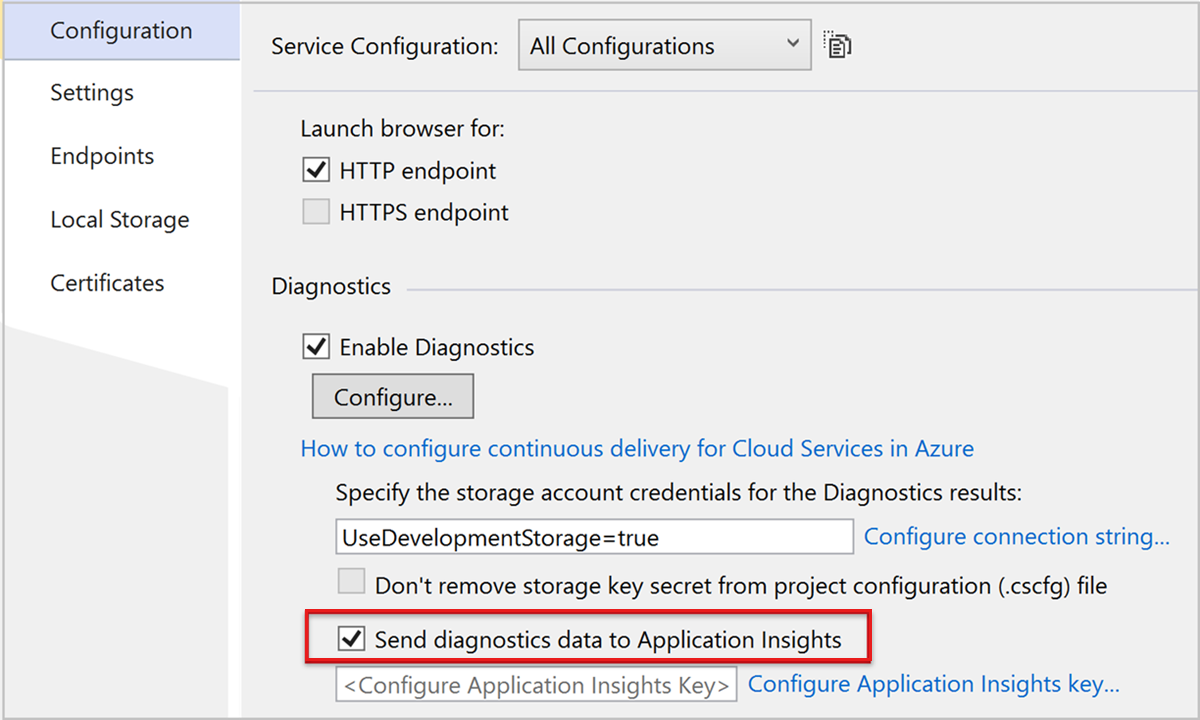
- 在 Visual Studio 解决方案资源管理器的“云服务>角色”下,打开每个角色的属性。
- 在“配置”中,选择“将诊断数据发送到 Application Insights 检查”框,然后选择之前创建的 Application Insights 实例。
对于 Web 角色,此选项提供性能监视、警报、诊断和使用情况分析。 对于其他角色,可以搜索和监视Azure 诊断,例如重启和性能计数器。
诊断 Application Insights 中的故障
Application Insights 附带特选的应用程序性能管理体验,可帮助诊断受监视应用程序中的故障。 若要查看Azure 门户中的故障,请转到 Application Insights 实例,然后选择“调查”下的“失败”。
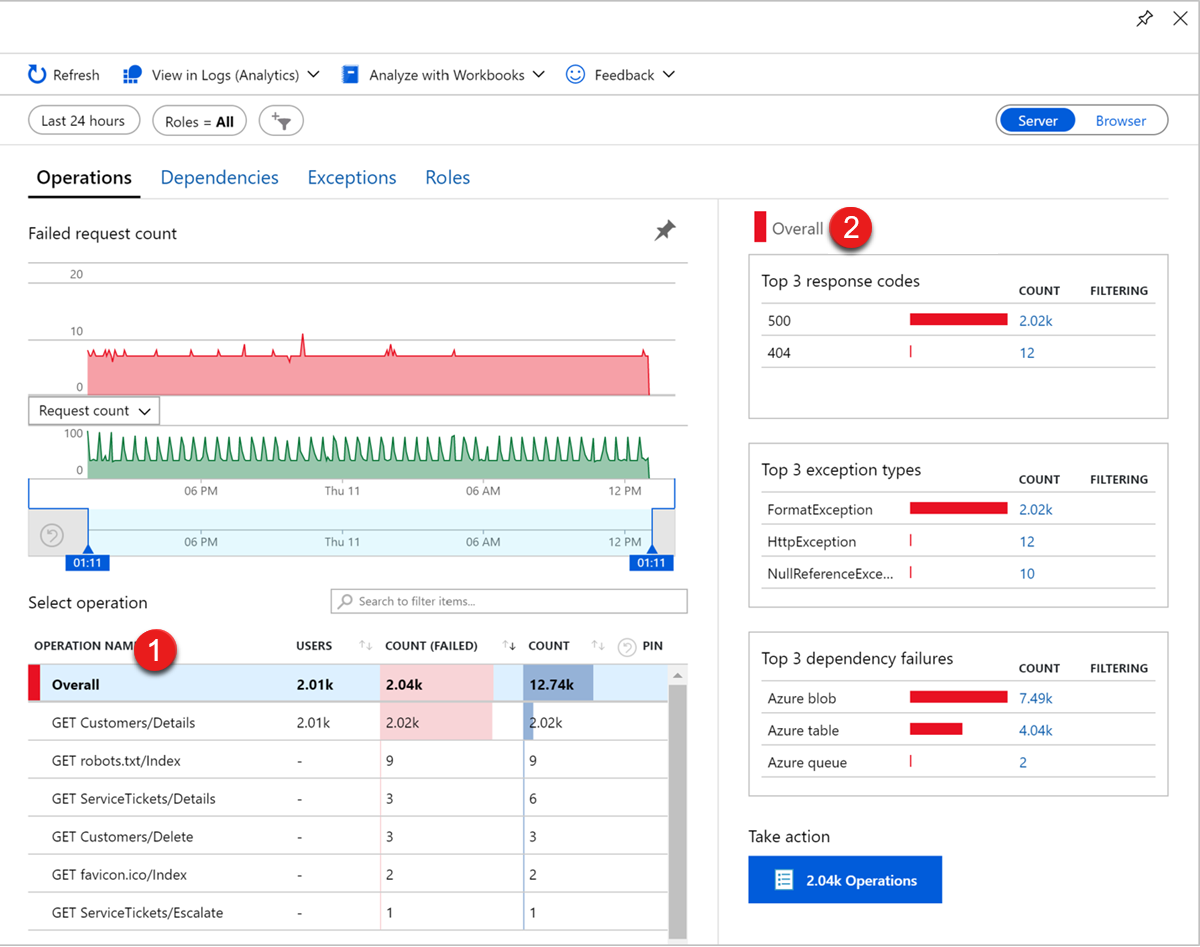
你将看到请求的失败率趋势、失败的次数以及受影响的用户数。 失败的操作表1 显示按请求 URL 分组的失败请求。 在“总体视图2”中,你将看到前三个响应代码、前三个异常类型和前三个失败的依赖项类型。
若要查看每个操作子集的代表性示例,请选择相应的链接。 例如,若要诊断异常,可以选择“ 端到端事务详细信息 ”选项卡显示的特定异常的计数。
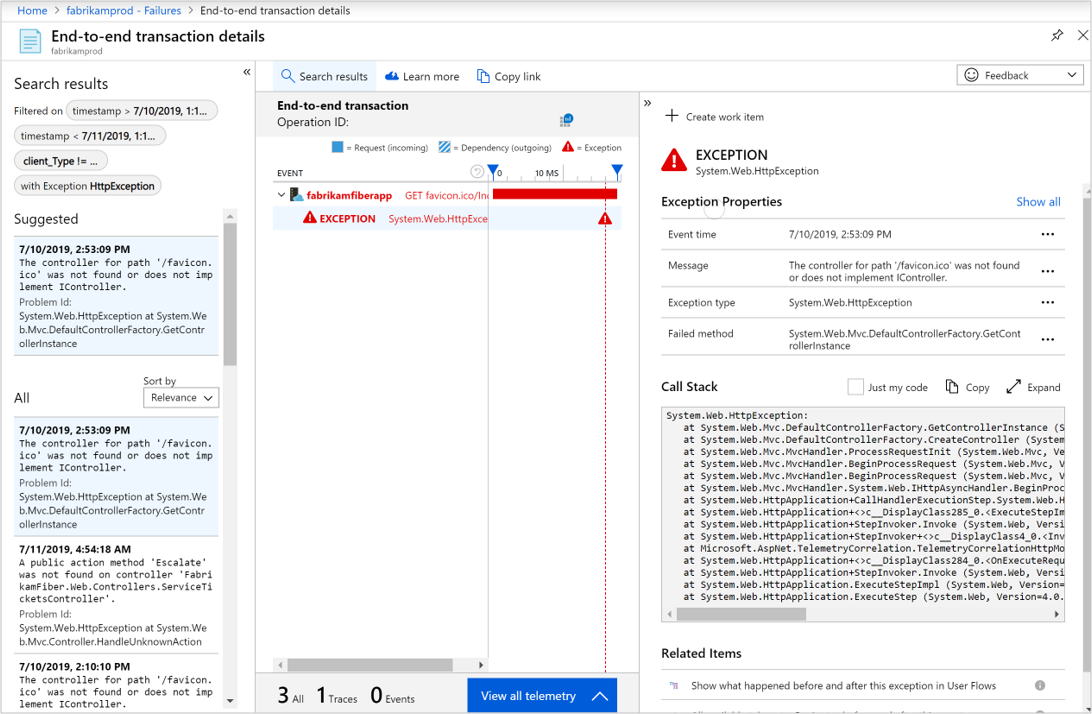
端到端事务详细信息中的以下信息可用于故障排除:
- 请求的时间戳
- 响应代码
- 响应时间
- 异常消息
- 异常类型
- 调用堆栈
诊断 Application Insights 中的性能问题
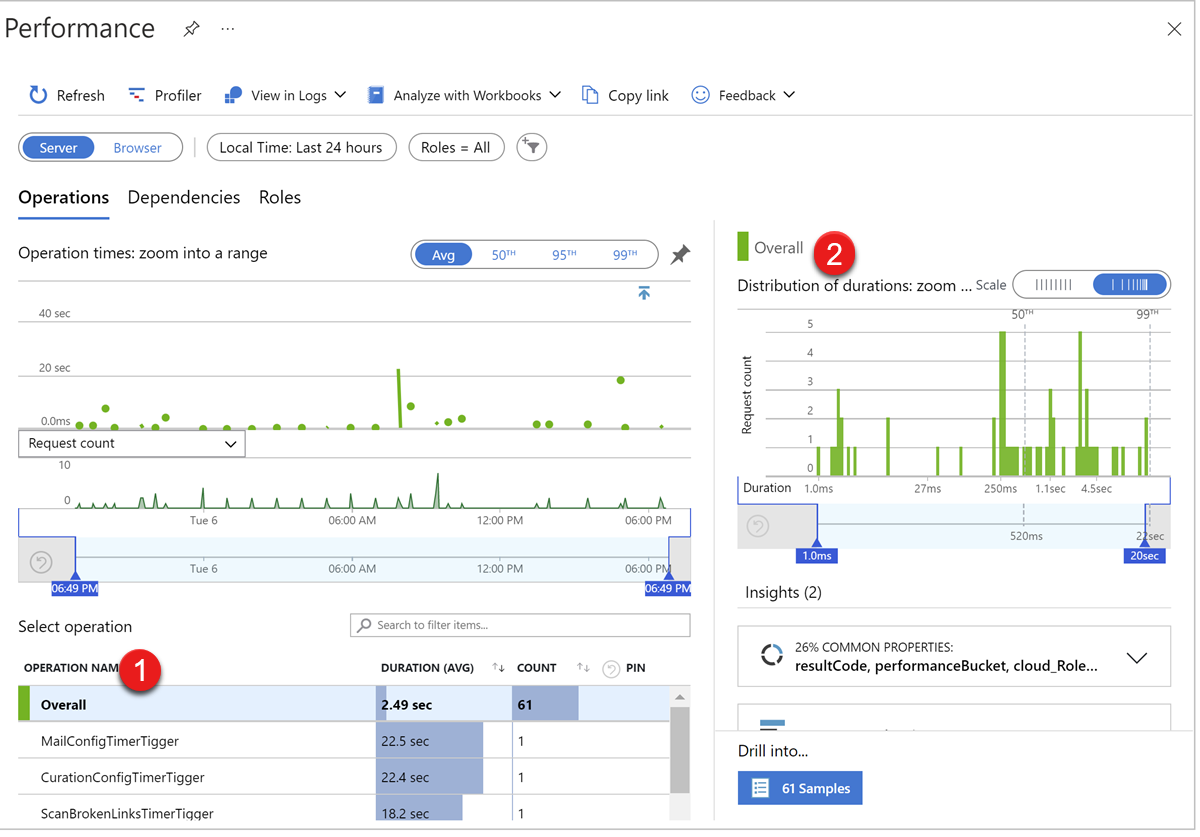
若要诊断 Web 角色的性能问题,可以在 Application Insights 实例的“性能”页上检查以下数据:
- Web 角色请求响应时间
- CPU、内存、磁盘 IO、Web 角色实例的网络 IO
在“ 操作 ”选项卡中,失败的操作表1 显示请求操作名称、持续时间、请求计数摘要。 选择一个操作,它将刷新指标图表2 以显示请求量和持续时间指标图表。
“ 角色 ”选项卡显示与云服务服务器更相关的指标数据,例如 CPU、可用内存、每个实例处理的请求等。
Application Insights 中的警报
警报允许用户设置自定义规则来监视云服务角色实例状态。 发生受监视事件时,用户可以收到电子邮件通知。
规则主要包含两个重要部分:条件和操作。 若要创建警报,请执行以下步骤:
在Azure 门户中,转到 Application Insights 实例,然后选择“监视”部分下的“警报”。 在此页上,可以看到所有触发的警报。 展开 “+ 创建”,然后选择“ 警报规则”。
设置条件。 条件由三个点组成:信号、维度和警报逻辑。 有关详细信息,请参阅 Azure Monitor 警报的类型。
- Signal 是警报规则将监视的指标数据类型。 可以使用常见的指标数据,例如 CPU、可用内存、失败的请求、异常和响应时间。
- 维度指定应用此警报规则的范围或筛选器。 对于基于云服务指标数据的警报规则,它们通常包含两个可能的维度选项:云角色实例和云角色名称。 除了这两个维度之外,还会有一些其他选择,具体取决于信号。
- 应在警报逻辑中设置警报规则条件的逻辑。 有几个重要概念:
- 阈值表示评估结果是动态的还是静态的。 如果它是静态的,则本示例中的评估指标数据 (失败请求计数,) 将与静态值(如 5 或 10)进行比较。 如果是动态的,则评估的数据将与过去短时间内的相同数据进行比较,例如过去 5 分钟的数据。
- 运算符、聚合类型、阈值和单位易于理解;它们表示逻辑的main主体。
- 聚合粒度(也称为“时间段”)是评估历史记录中的指标数据的时间长度。 如果为 5 分钟,则表示将评估过去 5 分钟的指标数据。 评估频率表示将触发评估的频率。
在触发警报规则时设置操作。 可以创建新的操作组并将其添加到此警报规则,也可以使用现有的操作组。
若要创建新的操作组,请执行以下步骤:
- 选择要在其中创建操作组资源的订阅和资源组,并提供名称和显示名称。
- 可选) 选择在触发警报规则(例如将电子邮件发送到特定电子邮件地址)时通知用户的方式。
- (可选) 选择将执行的操作。 我们可以在此选项中触发自动化 Runbook、Azure 函数和其他五种服务类型。
创建操作组时,也会将其添加到警报规则中。
在 “详细信息 ”页中,选择要在其中保存警报规则并设置其名称和严重性级别的订阅和资源组。
Application Insights 中的指标图表
应用程序见解中的指标图表可用于可视化数据更改。 这对于监视某个时间范围内服务的状态(例如几天或几周)非常有用。
可通过以下几点配置要监视的数据:
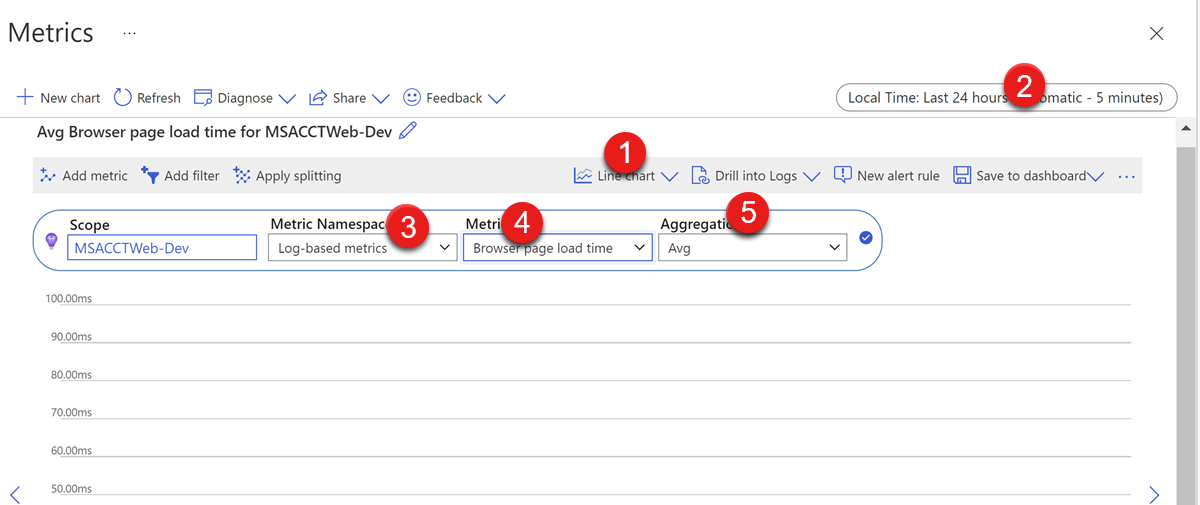
- 图表类型 - 要查看的图表类型。 可以选择折线图、面积图、条形图、散点图和网格。
- 时间范围 - 要生成图表的指标数据的时间范围, (注意本地时间与 UTC) 之间的差异。
- 指标命名空间 - 可能的指标数据组。 通常,只需在基于日志的指标和 Application Insights 标准指标之间进行选择。 默认情况下,将收集所有数据,例如 CPU、内存、请求、异常等。 自定义设置收集的一些更具体的数据(例如可在云服务) 的诊断设置中配置的 w3wp 进程 (的处理器时间)将包含在基于日志的指标中。
- 指标 - 要为其生成图表的数据。
- 聚合 - 从多个指标值计算的统计信息类型。 有关更多详细信息,检查本文档。 强烈建议将此保留为默认值。 只有在了解此指标数据类型的收集方式以及所有聚合类型之间的差异时,才应修改它。
提示
有时,图表中会有虚线。 这意味着该时间范围内的数据不够准确或未收集。 原因是该时间段内的数据不会继续。 假设每两分钟收集一次指标数据,但图表中两个点之间的时差为一分钟,则数据的准确性不足以生成图表,因此它是虚线。
Application Insights 中收集的日志
上面提供的所有 Application Insights 功能几乎都基于以日志形式收集的数据。 用户还可以直接检查这些日志,以获取页面上未显示的详细信息。
若要查看日志,请选择“监视”部分下的“日志”。
在“日志”页上,需要使用 Kusto 查询语言 (KQL) 查询或筛选收集的日志并获取所需的信息。
只需要注意两点:时间范围和查询。
顶部的时间范围可以设置要检查的日志的时间范围。 请记住,请注意本地时间与 UTC 之间的差异。
查询将分为两个部分:第一行中的表名和用于筛选结果的条件。
下面是常用的表:
| Application Insights 实例中的表 | 解释 |
|---|---|
| 请求 | 已发送到云服务并记录的请求 |
| exceptions | 未经处理的异常和记录的已处理异常 |
| 性能计数器 | 性能数据 |
下表中的数据由自定义诊断设置收集:
| Application Insights 实例中的表 | 诊断设置中的名称 |
|---|---|
| 痕迹 | 应用程序日志 |
| 痕迹 | ETW 日志 |
| 痕迹 | 基础结构日志 |
| traces/自定义事件 | Windows 事件日志 |
| 自定义指标 | 性能计数器 |