备注
若要自动执行本文中所述的手动分析,请参阅 使用 AGDiag 诊断可用性组运行状况事件。
本文提供故障排除步骤,可帮助你确定可用性组故障转移的原因。
Always On 运行状况问题或故障转移的影响
AlwaysOn 通过不同的机制实现可靠的运行状况监视,以确保托管主副本、基础群集和系统运行状况的 Microsoft SQL Server 实例的运行状况。 确定 Windows 群集或 Always On 运行状况问题时,生产工作负荷暂时中断。
检测到运行状况时,通常会发生以下事件序列。 在此疑难解答中,引用以下事件时会提及运行状况事件:
可用性组副本和数据库从主角色过渡到解析角色。
可用性组数据库过渡到脱机状态,不再可访问。
Windows 群集将可用性组群集资源标记为失败。
Windows 群集尝试使可用性组角色重新联机(在原始或自动故障转移伙伴副本上)。
如果 AlwaysOn 和 Windows 群集运行状况监视检测到可用性组角色正常运行,则可用性组角色将成功联机。
如果成功,可用性组副本和数据库将转换为主角色,可用性组数据库联机并可供应用程序访问。
应用程序无法访问可用性组数据库
检测到运行状况时,可用性组副本和数据库将转换为解析角色,可用性组数据库处于脱机状态。 在副本以主要角色(在原始副本服务器或故障转移伙伴副本服务器上)联机后,副本和数据库再次转换为联机。 虽然副本和数据库正在解析并且处于脱机状态,但尝试访问这些可用性组数据库的任何应用程序都失败并生成“错误 983”消息: Unable to access availability database... 如果 SQL Server 配置为记录失败的登录尝试,也会在 Microsoft SQL Server 错误日志中记录此错误:
Logon Error: 983, Severity: 14, State: 1.
Logon Unable to access availability database '<databasename>' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
可用性组在主角色联机之前处于“解析”角色的时间段通常只持续几秒钟甚至不到一秒。
识别和诊断 AlwaysOn 可用性组运行状况事件或故障转移
1. 确定 AlwaysOn 运行状况趋势
可以调查单个 AlwaysOn 运行状况事件,或者可能存在间歇性中断生产的问题的最新或持续趋势。 以下问题可以帮助你缩小范围,并关联生产环境中可能与这些运行状况相关的最近更改:
- AlwaysOn 或群集运行状况事件趋势何时开始?
- 运行状况事件是否发生在某一天?
- 运行状况事件是否发生在一天中的某个时间?
- 运行状况事件是否发生在每月的某一天或一周?
如果检测到趋势,请检查系统(虚拟环境中的主机系统)、ETL 批处理和其他可能与这些运行状况事件关联的作业的计划维护。 如果系统是虚拟机,请调查主机系统,了解在中断时可能引入的更改。
考虑繁忙的临时生产工作负荷,这些工作负荷可能与运行状况问题的时间相关(例如,用户首次登录系统时或用户从午餐返回后)。
备注
这是考虑在一周和一个月内收集性能数据的计划的好时机。 为了更好地了解系统何时最繁忙,可以度量 Windows 性能监视器计数器,例如 Processor Information::% Processor Time, Memory::Available MBytes和 MSSQLServer:SQL Statistics::Batch Requests/sec。
2.查看群集日志
Windows 群集日志是用于标识 AlwaysOn 或群集运行状况事件类型以及检测到导致事件的运行状况状况的最全面的日志。 若要生成并打开群集日志,请执行以下步骤:
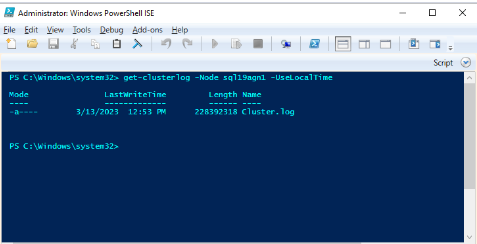
使用 Windows PowerShell 在运行事件时托管主副本的群集节点上生成 Windows 群集日志。 例如,使用“sql19agn1”作为基于 SQL Server 的服务器名称,在提升的 PowerShell 窗口中运行以下 cmdlet:
get-clusterlog -Node sql19agn1 -UseLocalTime
备注
默认情况下,日志文件在 %WINDIR%\cluster\reports 中创建。
3. 在群集日志中查找运行状况事件
AlwaysOn 使用多个运行状况监视机制来监视可用性组运行状况。 除了 Windows 群集运行状况事件(其中 Windows 群集检测到群集节点中的运行状况问题),AlwaysOn 还具有四种不同类型的运行状况检查:
- SQL Server 服务未运行
- SQL Server 租用超时
- SQL Server 运行状况检查超时
- SQL Server 内部运行状况问题
可以通过搜索字符串 [hadrag] Resource Alive result 0的群集日志来查找其中任一 AlwaysOn 特定的运行状况事件。 检测到这些事件中的任何一个时,此字符串将保存在群集日志中。 例如:
00001334.00002ef4::2019/06/24-18:24:36.153 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
可以使用工具查找群集日志中的所有运行状况事件,以便生成 AlwaysOn 运行状况问题的摘要报告。 这可用于识别时间顺序趋势,并确定特定的 AlwaysOn 运行状况状况是否定期出现。 以下屏幕截图显示了如何使用文本编辑器(在本例中为 NotePad++)查找包含字符串的群集日志 [hadrag] Resource Alive result 0 中的所有行:

确定并解决触发故障转移的运行状况问题
若要确定主要副本群集日志中的运行状况问题,请将它们与以下部分中介绍的问题进行比较。 AG 故障转移的常见原因包括:
- 群集运行状况事件
- SQL Server 服务已关闭(Always On 运行状况事件)
- 租用超时(AlwaysOn 运行状况事件)
- 运行状况检查超时(AlwaysOn 运行状况事件)
- SQL Server 运行状况(AlwaysOn 运行状况事件)
群集运行状况事件
Microsoft Windows 群集监视群集中成员服务器的运行状况。 如果检测到运行状况问题,可能会从群集中删除群集成员服务器。 此外,如果群集资源配置为自动故障转移,则群集资源(包括托管在已删除群集成员服务器上的可用性组角色)将移动到可用性组故障转移伙伴副本。
现象
下面是群集日志中群集运行状况事件的示例。 若要查找它,可以搜索Lost quorumCluster service has terminated或因为可用性组角色更改或故障转移期间可能存在。
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: Lost quorum (1)
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: goingAway: 0, core.IsServiceShutdown: 0
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925)
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [NETFT] Cluster Service preterminate succeeded.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925), executing OnStop
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM]: Shutting down, so unloading the cluster database.
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
000019cc.000019d0::2022/12/15-14:26:02.654 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
标识此事件的另一种方法是搜索 Windows 系统事件日志:
Critical SQL19AGN1.CSSSQL 1135 Microsoft-Windows-FailoverClusterin Node Mgr NT AUTHORITY\SYSTEM Cluster node 'SQL19AGN2' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Critical SQL19AGN1.CSSSQL 1177 Microsoft-Windows-FailoverClusterin Quorum Manager NT AUTHORITY\SYSTEM The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
诊断群集运行状况事件
Windows 事件日志(事件 1135 和 1177)中的错误表明网络连接是事件发生的原因。 这是检测到群集运行状况问题的最常见原因。 以下示例显示其他群集成员服务器无法与承载可用性组主副本的此服务器通信,并且此问题触发了从群集中删除群集节点:
00000fe4.00001edc::2022/12/14-22:44:36.870 INFO [NODE] Node 1: New join with n3: stage: 'Attempt Initial Connection' status (10060) reason: 'Failed to connect to remote endpoint <endpoint address>'
00000fe4.00001620::2022/12/15-14:26:02.050 INFO [IM] got event: Remote endpoint <endpoint address> unreachable from <endpoint address>
00000fe4.00001620::2022/12/15-14:26:02.050 WARN [NDP] All routes for route (virtual) local <local address> to remote <remote address> are down
00000fe4.0000179c::2022/12/15-14:26:02.053 WARN [NODE] Node 1: Connection to Node 2 is broken. Reason GracefulClose(1226)' because of 'channel to remote endpoint <endpoint address> is closed'
可以搜索群集日志,获取节点连接失败的证据。 从找到 Lost quorum的群集日志中的位置,向后搜索字符串,例如 Failed to connect to remote endpoint, unreachable和 is broken。
解决方法
确保群集运行状况监视适用于主机环境。 有关 Microsoft Azure 中托管的 SQL Server Always On 可用性组的详细信息,请参阅 Windows Server 故障转移群集概述 - Azure VM 上的 SQL Server。
如有必要,请考虑联系 Microsoft Windows 高可用性支持部门以打开支持事件。
SQL Server 服务已关闭:AlwaysOn 运行状况事件
AlwaysOn 运行状况监视可以检测托管可用性组主副本的 SQL Server 服务是否不再运行。
现象
下面是可用性组角色“ag”的群集日志报告示例,该报告指示失败,因为 QueryServiceStatusEx 返回了进程 ID 0:
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] QueryServiceStatusEx returned a process id 0
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] SQL server service is not alive
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] Resource Alive result 0.
00001898.0000185c::2023/02/27-13:27:41.121 WARN [RHS] Resource ag IsAlive has indicated failure.
诊断 SQL 服务关闭事件
检查 Windows 系统事件日志和 SQL Server 错误日志中是否有意外的 SQL Server 关闭。
如果 SQL Server 已由系统关闭或管理关闭关闭,则会在 SQL Server 错误日志中看到以下条目:
2023-03-10 09:38:46.73 spid9s SQL Server is terminating in response to a 'stop' request from Service Control Manager. This is an informational message only. No user action is required.
Windows 系统事件日志将显示以下错误条目:
Information 3/10/2023 9:41:06 AM Service Control Manager 7036 None The SQL Server (MSSQLSERVER) service entered the stopped state.
如果 SQL Server 意外关闭,Windows 系统事件日志会显示以下错误条目:
Error 3/10/2023 8:37:46 AM Service Control Manager 7034 None The SQL Server (MSSQLSERVER) service terminated unexpectedly. It has done this 1 time(s).
检查 SQL Server 错误日志的末尾是否有线索。 如果错误日志突然结束,这意味着它已强制关闭。 例如,如果 SQL Server 使用任务管理器终止,SQL Server 错误报告不会透露任何可能导致进程关闭的内部问题的任何信息。
解决方法
确保经过授权的数据库和系统管理员有权访问系统,以最大程度地减少 SQL Server 服务意外终止。 检查事件日志后,调查服务为何必须意外终止。
如果 SQL Server 内部运行状况问题导致 SQL Server 意外终止,则 SQL 错误日志末尾可能存在可能致命异常(包括正在生成的内存转储诊断文件)的线索。 查看线索并采取必要的操作。 如果找到转储文件,请考虑联系 Microsoft SQL Server 支持部门,并提供 SQL Server 错误日志和转储文件内容以供进一步调查。
租约超时:AlwaysOn 运行状况事件
AlwaysOn 使用“租用”机制监视安装 SQL Server 的计算机的运行状况。 默认租约超时为 20 秒。
现象
下面是群集日志中 AlwaysOn 租约超时的示例输出。 可以搜索这些字符串,在群集日志中查找租约超时。
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:35:57.0, 98.068572, 509227008.000000, 0.000395, 0.000350 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:7.0, 12.314941, 451817472.000000, 0.000278, 0.000266 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:17.0, 17.270742, 416096256.000000, 0.000376, 0.000292 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:27.0, 38.399895, 416301056.000000, 0.000446, 0.000304 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:37.0, 100.000000, 417517568.000000, 0.001292, 0.000666
有关租约超时的详细信息,请参阅“机制”中的“租约机制”部分,以及 AlwaysOn 可用性组的租约、群集和运行状况检查超时指南。
诊断和解决 AlwaysOn 租约超时事件
有两个主要问题可以触发租约超时:
SQL Server 内存转储:当 SQL Server 检测到某些内部运行状况事件(例如访问冲突、断言或计划程序死锁)时,它会在 SQL Server \LOG 文件夹中生成诊断转储文件(.mdmp)。 生成内存转储的过程会在短时间内挂起 SQL Server 执行。 在此期间,租约机制可以检测缺少服务响应和触发器操作。 有关详细信息,请参阅 转储生成的影响。
系统范围的性能问题:租约超时不一定表示 SQL Server 运行状况问题。 相反,它可以指示系统范围的运行状况问题,这也会影响基于 SQL Server 的服务器运行状况。
- 系统上 CPU 使用率高(接近 100%)。
- 内存不足条件 - 正在分页的虚拟内存和/或其中一个进程。
- WSFC 由于仲裁丢失而脱机
- VM 限制会影响性能并导致租约过期。
解决方法
有关详细故障排除步骤,请参阅 MSSQLSERVER_19407。 下面是两个最常见的问题:
1. SQL服务器转储文件诊断
SQL Server 可能会检测到内部运行状况问题,例如访问冲突、断言或死锁计划程序。 在这种情况下,程序会在 SQL Server 进程的 SQL Server \LOG 文件夹中生成一个微型转储文件(.mdmp),用于诊断。 将小型转储文件写入磁盘时,SQL Server 进程会冻结几秒钟。 在此期间,SQL Server 进程中的所有线程都处于冻结状态,其中包括 AlwaysOn 运行状况监视监视监视的租约线程。 因此,Always On 可能会检测到租约超时。
**Dump thread - spid = 0, EC = 0x0000000000000000
***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0001.txt
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 11/02/14 21:21:10 spid 1920
*
* Deadlocked Schedulers
*
* *******************************************************************************
* -------------------------------------------------------------------------------
* Short Stack Dump
Stack Signature for the dump is 0x00000000000002BA
Error: 19407, Severity: 16, State: 1.
The lease between availability group 'ag' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
若要解决此问题,必须检查内存转储文件诊断的根本原因。 请考虑联系 Microsoft SQL Server 支持部门,以提供 SQL Server 错误日志和转储文件内容以供进一步调查。
2. CPU 使用率较高或其他系统性能问题
租约超时表示影响整个系统(包括 SQL Server)的性能问题。 若要诊断系统问题,AlwaysOn 运行状况诊断报告群集日志中的性能监视器数据,并包括租约超时事件。 性能数据跨越约 50 秒,导致租约超时事件,报告 CPU 利用率、可用内存和磁盘延迟。
下面是报告的性能数据的示例,其中显示了群集日志中的租约超时。 在此示例输出中,与租用超时相关的高总体 CPU 利用率。
00000f90.000015c0::2020/08/07-14:16:41.378 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000f90.000015c0::2020/08/07-14:16:41.382 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:20.0, 83.266073, 31700828160.000000, 0.018094, 0.015752
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:30.0, 93.653224, 31697063936.000000, 0.038590, 0.026897
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:40.0, 94.270691, 31696265216.000000, 0.166000, 0.038962
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:50.0, 90.272016, 31695409152.000000, 0.215141, 0.106084
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:16:1.0, 99.991336, 31695892480.000000, 0.046983, 0.035440
如果性能数据显示 CPU 使用率高、内存不足或租约超时时磁盘延迟较高,请开始收集主副本全天性能监视器数据,以调查这些症状。 通过在较长时间内捕获性能监视器数据,可以更好地识别这些资源的基线和峰值,并在发生租约超时时监视这些资源的更改。 收集此数据时,请考虑 SQL Server 中是否存在与这些资源问题和运行状况事件时间相关的某些计划工作负荷或即席工作负荷。
还应捕获报告相同系统资源使用情况的计数器,包括以下内容:
Processor Information::% Processor TimeMemory::Available MBytesLogical Disk::Avg. Disk sec/ReadLogical Disk::Avg. Disk sec/WriteLogical Disk::Avg. Disk Read Queue LengthLogical Disk::Avg. Disk Write Queue LengthMSSQLServer:SQL Statistics::Batch Requests/sec
运行状况检查超时:AlwaysOn 运行状况事件
AlwaysOn 使用运行状况检查机制来监视 SQL Server 的运行状况,以及客户端应用程序连接的能力。
现象
当可用性组副本转换为主角色时,Always On 运行状况监视会建立与 SQL Server 实例的本地 ODBC 连接。 当 Always On 已连接和监视时,如果 SQL Server 在为可用性组的运行状况检查超时设置的时间段内未响应 ODBC 连接(默认值为 30 秒),则会触发运行状况检查超时事件。 在这种情况下,如果可用性组配置为执行此操作,则可用性组将从主角色过渡到解析角色并启动故障转移。
有关运行状况检查超时的详细信息,请参阅“机制”中的“运行状况检查超时操作”部分,以及 AlwaysOn 可用性组的租约、群集和运行状况检查超时指南。
下面是群集日志中报告的 AlwaysOn 运行状况检查超时:
0000211c.00002d70::2021/02/24-02:50:01.890 WARN [RES] SQL Server Availability Group: [hadrag] Failed to retrieve data column. Return code -1
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Resource Alive result 0.
0000211c.00002594::2021/02/24-02:50:02.453 WARN [RHS] Resource AG IsAlive has indicated failure.
00001278.00002ed8::2021/02/24-02:50:02.453 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'AG', gen(0) result 1/0.
诊断并解决 AlwaysOn 运行状况检查超时事件
以下部分可帮助你查看可能发现的“痕迹崩溃”事件的 SQL Server 日志,以及与检测到和报告的 AlwaysOn 运行状况检查超时相关的事件。 此处查看的日志包括群集日志(确认运行状况检查超时)、 system_health 扩展事件日志和 SQL Server 错误日志(在 SQL Server \LOG 文件夹中找到),以及 Windows 系统事件日志。 使用这些日志和其他日志查找有助于确定运行状况检查超时原因的关联事件。
1.检查未生成计划程序事件
AlwaysOn 运行状况检查超时通常是由 SQL Server 中的“非生成”事件引起的。 当 SQL Server 检测到某个线程未在计划程序上生成时,它将报告发生非生成计划程序事件。 如果在未收到 CPU 时间的同一计划程序上看到其他任务,则这是非生成计划程序的主要标志。 此行为可能会导致延迟执行这些任务和分配给特定 CPU 时间计划程序“饥饿”工作负荷。
若要检查非生成计划程序事件,请执行以下步骤:
检查 SQL Server
system_health扩展事件日志,以确定在 AlwaysOn 运行状况检查超时事件发生时是否报告了某种类型的非生成计划程序事件。 你可能会发现的非生成事件包括:scheduler_monitor_non_yielding_ring_buffer_recordedscheduler_monitor_non_yielding_iocp_ring_buffer_recordedscheduler_monitor_stalled_dispatcher_ring_buffer_recordedscheduler_monitor_non_yielding_rm_ring_buffer_recorded
在主副本上打开 SQL Server 系统运行状况扩展事件日志,到可疑运行状况检查超时的时间。
在 SQL Server Management Studio (SSMS)中,转到 “文件 > 打开”,然后选择“ 合并扩展事件文件”。
选择“添加”按钮。
在 “文件打开 ”对话框中,导航到 SQL Server \LOG 目录中的文件。
按住 Control,然后选择名称以
system_health_xxx.xel开头的文件。选择“打开>确定”。
筛选结果。 右键单击名称列下的事件,然后选择“按此值筛选”。
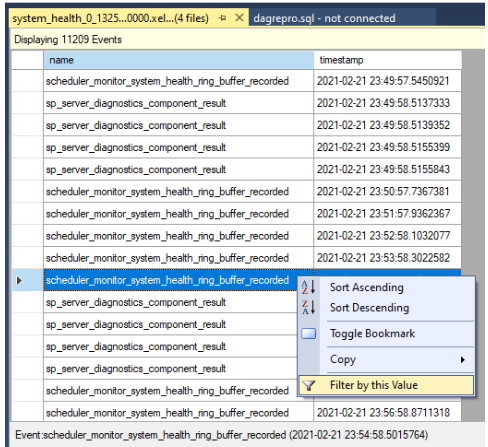
定义筛选器以对名称列中的值包含
yield的行进行排序,如以下屏幕截图所示。 这会返回可能记录在日志中的system_health所有类型的非生成事件。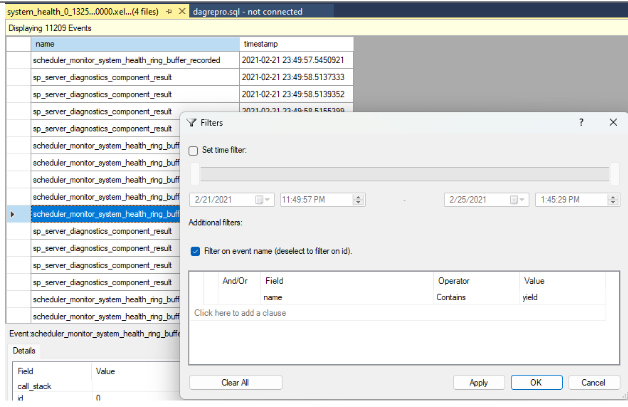
比较时间戳以查看运行状况检查超时时是否存在非生成事件。下面是群集日志中报告的运行状况检查超时:
0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1: [hadrag] Resource Alive result 0.可以看到,运行状况检查超时时发生了非生成事件。
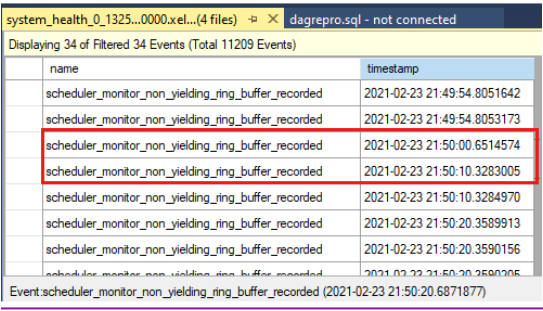
如果检测到非生成事件,请检查非生成事件的原因。 请考虑联系 SQL Server 支持团队调查非生成事件。
2.检查 SQL Server 错误日志
检查 SQL Server 错误日志,以便在运行状况检查超时时关联事件。这些事件可能提供“面包屑”,建议采取进一步步骤来确定运行状况检查超时的根本原因。
例如,以下日志条目显示群集日志中发生了运行状况检查超时:
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Resource Alive result 0.
在 SQL Server 错误日志中,在运行状况检查超时后的几秒钟内,SQL Server 报告检测到严重 I/O 延迟:
2021-02-23 20:49:54.64 spid12s SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\DATA\agdb_log.ldf] in database id 12. The OS file handle is 0x0000000000001594. The offset of the latest long I/O is: 0x000030435b0000. The duration of the long I/O is: 26728 ms.
查看系统事件日志,了解可能与运行状况检查超时事件相关的系统线索。 查看 Windows 系统事件日志时,可能会发现在同一运行状况检查超时时同时报告的 I/O 问题:
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"Reset to device, \Device\<device ID>, was issued."
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"The IO operation at logical block address <block address> for Disk 6 (PDO name: \Device\<device ID>) was retried."
SQL Server 运行状况:AlwaysOn 运行状况事件
AlwaysOn 监视不同类型的 SQL Server 运行状况事件。 在托管可用性组主副本时,SQL Server 会持续运行 sp_server_diagnostics 使用不同的组件报告 SQL Server 运行状况。 检测到任何运行状况问题时, sp_server_diagnostics 报告该特定组件的错误,然后将结果发送回 AlwaysOn 运行状况检测过程。 报告错误时,如果可用性组配置为执行此操作,可用性组角色会显示失败状态和可能的故障转移。
现象
下面是群集日志中报告 sp_server_diagnostics SQL Server 运行状况问题的示例。 SQL Server 将系统组件中的“错误”状态报告给 AlwaysOn 运行状况监视,并且“contoso-ag”可用性组转换为失败状态。
备注
SQL Server 运行状况问题生成类似于运行状况检查超时的报告。两个运行状况事件报告 Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel。 SQL Server 运行状况事件的区别在于它报告 SQL Server 组件已从“警告”更改为“错误”。
INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'warning' to 'error' at 2019-06-20 15:05:52.330
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Resource Alive result 0.
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
WARN [RHS] Resource contoso-ag IsAlive has indicated failure.
INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'contoso-ag', gen(0) result 1/0.
诊断 SQL Server 运行状况事件
SQL Server 运行状况报告的运行状况问题应指示根本原因分析的方向。
默认情况下,部署可用性组时,该 FAILURE_CONDITION_LEVEL 组设置为 3。 这会激活对某些 SQL Server 运行状况配置文件(而非所有)的监视。 在默认级别,当 SQL Server 生成过多的转储文件、写入访问冲突或孤立的旋转锁时,Always On 会触发运行状况事件。 将可用性组设置为最高级别 4 或 5 将扩展受监视的 SQL Server 运行状况问题的类型。 有关 SQL Server 运行状况 AlwaysOn 监视器的详细信息,请参阅 为可用性组配置灵活的自动故障转移策略 - SQL Server Always On。
若要确定 AlwaysOn 特定的运行状况问题,请执行以下步骤:
打开主副本上的 SQL Server 群集诊断扩展事件日志,以在发生可疑 SQL Server 运行状况事件时。
在 SSMS 中,转到“文件>打开”,然后选择“合并扩展事件文件”。
选择 添加 。
在 “文件打开 ”对话框中,导航到 SQL Server \LOG 目录中的文件。
按 Control,选择名称匹配
<servername>_<instance>_SQLDIAG_xxx.xel的文件,然后选择“打开>确定”。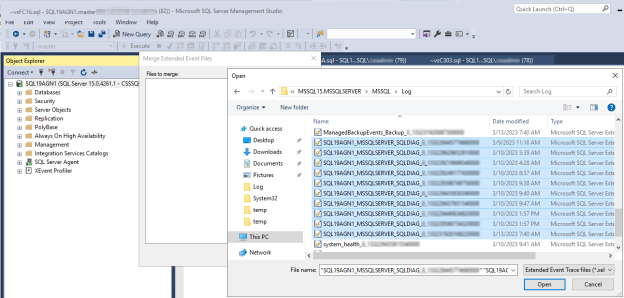
SSMS 中会显示一个新的选项卡式窗口,其中包含扩展事件,如以下屏幕截图所示。
若要调查 SQL Server 运行状况问题,请找到
component_health_result其值为error< a0/state_desc>。 下面是系统组件事件的示例,该事件将错误报告回 AlwaysOn 运行状况监视: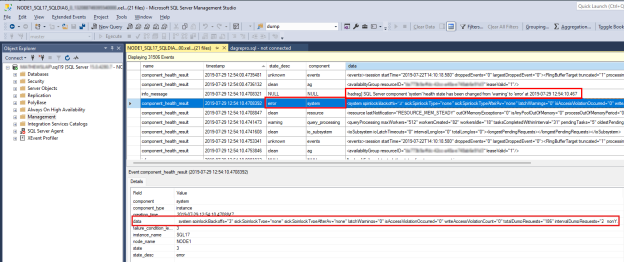
双击 下窗格中的数据 列。 这将在新的 SSMS 窗口窗格中打开详细的组件数据以供审阅。 下面是系统组件数据的外观:

请注意,“totalDumprequests=186”数据指示此 SQL Server 上生成的转储文件诊断事件过多。 这是系统组件报告错误状态的原因。 当 AlwaysOn 运行状况监视收到此错误状态时,它会触发可用性组运行状况事件。 还可以验证是否未从系统组件数据中提供的数据检测到写入访问冲突或孤立旋转锁。



解决方法
根据发现的问题类型,必须相应地解决该问题。 由于为可用性组配置灵活的自动故障转移策略 - SQL Server Always On 一文讨论了可能导致此问题的各种问题。 示例包括:
- SQL Server 服务停止。
- 租约超时。
- 可用性副本处于失败状态。
- 孤立的旋转锁、访问冲突或短时间内生成的内存转储过多的内存转储。
- SQL Server 内部资源池中的持久内存不足条件。
- 检测计划程序死锁。
- 检测到无法解决的死锁。
如有必要,请联系 SQL Server 支持部门,以打开支持事件,以获取进一步帮助查找这些内部 SQL Server 运行状况问题的根本原因