本文提供与恢复队列相关的问题的解决方案。
什么是恢复队列?
对可用性组数据库中的主要副本所做的更改将发送到同一可用性组中定义的所有次要副本。 这些更改在到达次要副本后,会首先写入可用性组数据库的事务日志文件中。 Microsoft SQL Server 然后使用 恢复 或 重做 操作更新数据库文件。
如果对可用性组所做的更改到达并强化了数据库事务日志文件的速度比恢复快,则会 形成恢复队列 。 此队列由未恢复和还原到数据库的已强化事务日志事务组成。
恢复(重做)排队的症状和效果
查询主副本和次要副本将返回不同的结果
查询次要副本的只读工作负荷可能会查询过时的数据。 如果发生恢复队列,则查询相同数据时,对主副本数据库上的数据的更改可能不会反映在辅助数据库中。
尽管更改到达辅助数据库并写入数据库日志文件,但在恢复并还原到数据库文件之前,不会查询这些更改。 恢复操作使这些更改可读。
有关详细信息,请参阅 “AlwaysOn 可用性组可用性模式之间的差异”的次要副本 上的数据延迟部分。
故障转移时间较长或超过 RTO
恢复时间目标(RTO)是组织可以处理的最大数据库停机时间。 RTO 还介绍了组织在服务中断后如何重新获得对数据库的访问权限。 如果在发生故障转移时次要副本上存在大量恢复队列,则恢复可能需要更长的时间。 恢复后,数据库将转换为主角色,并表示故障转移之前存在的数据库的状态。 较长的恢复时间可能会延迟故障转移后生产恢复的速度。
各种诊断功能报告可用性组恢复队列
对于恢复排队,SQL Server Management Studio (SSMS) 中的 AlwaysOn 仪表板可能会报告运行不正常的可用性组。
如何检查恢复(重做)排队
恢复队列是一种按数据库度量值,可以使用主副本上的 AlwaysOn 仪表板或使用 主副本或辅助副本上的sys.dm_hadr_database_replica_states 动态管理视图(DMV)进行检查。 性能监视器计数器检查恢复队列和恢复速率。 必须针对次要副本检查这些计数器。
接下来的几个部分提供了主动监视可用性组数据库恢复队列的方法。
查询sys.dm_hadr_database_replica_states
sys.dm_hadr_database_replica_states DMV 为每个可用性组数据库报告一行。 报表中的一列是 redo_queue_size。 此值是以 KB 为单位的恢复队列大小。 可以设置类似于以下查询的查询,以每隔 30 秒监视恢复队列大小中的任何趋势。 查询在主要副本上运行。 它使用 is_local=0 谓词报告次要副本的数据,其中 redo_queue_size 和 redo_rate 相关。
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.redo_queue_size, drs.redo_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
下面是输出的外观。

在 AlwaysOn 仪表板中查看恢复队列
若要查看恢复队列,请执行以下步骤:
通过右键单击 SSMS 对象资源管理器中的可用性组,在 SSMS 中打开 Always On 仪表板。
选择“ 显示仪表板”。
可用性组数据库最后列出,并且报告了一些有关数据库的数据。 尽管 默认情况下未列出重做队列大小(KB) 和 重做率(KB/秒), 但可以将它们添加到此视图中,如下一步的屏幕截图所示。
若要添加这些计数器,请右键单击数据库报表上方的标题,然后从可用列列表中选择。
若要添加 重做队列大小(KB) 和 重做速率(KB/秒),请右键单击如以下屏幕截图中红色突出显示的标头。
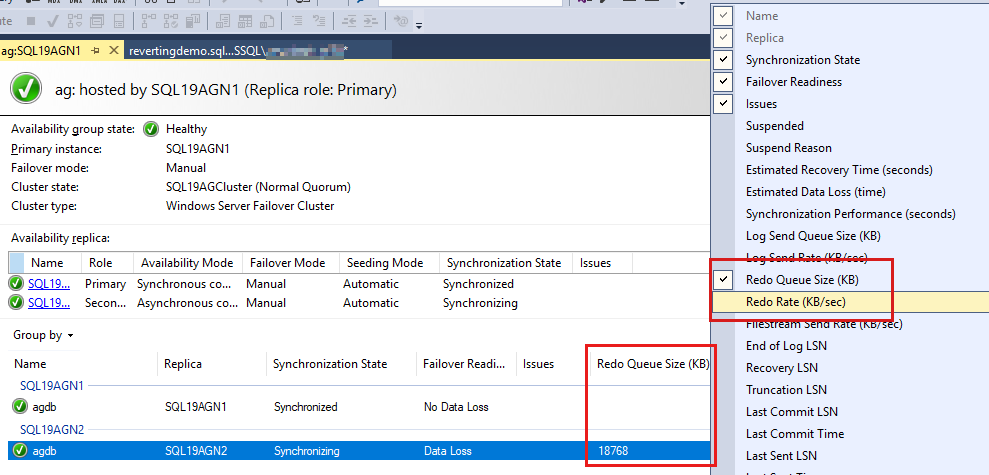
默认情况下,AlwaysOn 仪表板每 60 秒自动刷新 重做队列大小(KB) 和 重做率(KB/秒 )。
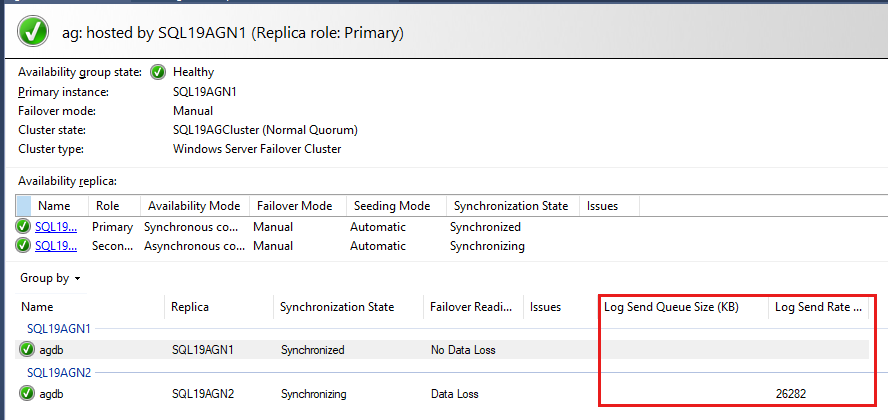


查看性能监视器中的恢复队列
恢复队列大小对于每个次要副本和数据库都是唯一的。 因此,若要查看可用性组数据库的恢复队列,请执行以下步骤:
在次要副本上打开性能监视器。
选择“添加”(计数器)按钮。
在“可用计数器”下,选择“SQLServer:数据库副本”,然后选择“恢复队列”和“Redone Bytes/sec”计数器。
在 “实例 列表”框中,选择要监视的恢复队列的可用性组数据库。
选择“添加”>“确定”。
下面是增加恢复队列的外观。
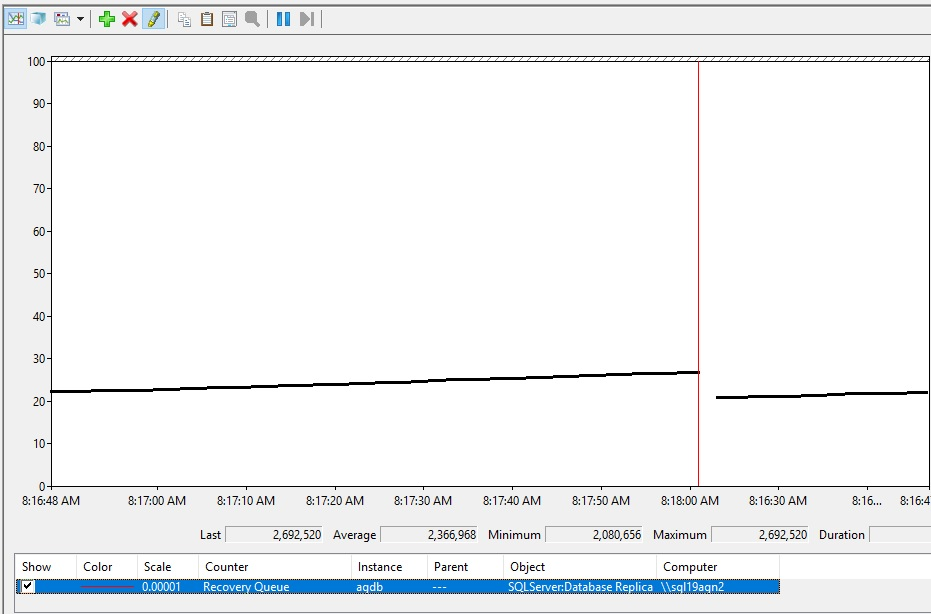

解释恢复队列值
本部分介绍如何解释与上一部分确定的恢复队列相关的值。
恢复队列何时出现问题? 应该容忍多少恢复队列?
你可能假设如果恢复队列报告值 0,这意味着该报告时不会发生恢复队列。 但是,当生产环境繁忙时,应该会看到恢复队列经常报告非零的值,即使在正常的 AlwaysOn 环境中也是如此。 在典型生产期间,应会看到此值在 0 与非零值之间波动。
如果发现随着时间推移增加恢复队列,需要进一步调查。 此额外活动指示某些内容已更改。 如果在恢复队列中观察到突然增长,以下度量值可用于故障排除:
- Log Redo Rate (KB/sec) (AlwaysOn 仪表板)
- DMV sys.dm_hadr_database_replica_states 中的Redo_rate
获取重做率的基线费率
在正常运行的 AlwaysOn 性能期间,监视繁忙可用性组数据库的重做速率。 在通常繁忙的工作时间,他们看起来是什么样子? 在维护期间,当大型事务(索引重新生成、ETL 进程)在系统上驱动更高的事务吞吐量时,这些速率是多少? 观察恢复队列增长时,可以比较这些值,以帮助确定已更改的内容。 工作负荷可能大于平常。 如果重做率较低,可能需要进一步调查来确定原因。
工作负荷卷很重要
如果工作负荷较大(例如针对 100 万行的 UPDATE 语句,对 1 TB 表生成索引,甚至插入数百万行的 ETL 批处理),应会看到一些恢复队列增长(即立即或随着时间的推移)。 当可用性组数据库中突然发生大量更改时,这一点是预期的。
如何诊断恢复(重做)排队
确定特定辅助副本可用性组数据库的恢复队列后,连接到辅助副本,然后查询 sys.dm_exec_requests 以确定 wait_type 恢复线程和 wait_time 恢复线程。 下面是可在循环中运行的查询。 你正在寻找一个或多个等待类型的高频率,甚至等待这些等待类型。 下面是每秒运行一次的示例查询,并报告可用性组“agdb”的等待类型和等待时间:
WHILE (1=1)
BEGIN
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')
waitfor delay '00:00:05.000'
END
重要
对于有意义的等待类型输出,在使用前面所述的方法之一监视此情况时,应观察到恢复队列增加。
在此示例中,报告了一些与 I/O 相关的等待类型(PAGEIOLATCH_UP,)。 PAGEIOATCH_EX 监视以检查这些等待类型是否继续具有最大 wait_times 值,如下一列中报告的那样。

SQL Server 重做等待类型
确定等待类型后,请查看以下文章 SQL Server 2016/2017:可用性组次要副本重做模型和性能 - Microsoft Tech Community 作为导致恢复队列的常见等待类型的交叉引用,以及帮助解决问题。
辅助报表服务器上的阻止重做线程
如果解决方案针对次要副本上的可用性组数据库定向报告(查询),则这些只读查询获取架构稳定性 (Sch-S) 锁。 这些 Sch-S 锁可以阻止重做线程获取架构修改 (Sch-M) 锁(也称为“架构修改锁”或 LCK_M_SCH_M)以进行任何数据定义语言(例如 ALTER TABLE 或 ALTER INDEX) 更改。 在取消阻止之前,阻止的重做线程无法应用日志记录。 这可能会导致恢复队列。
若要检查阻止重做的历史证据,请使用 SSMS 打开 辅助副本上的 AlwaysOn_health Xevent 跟踪文件。 查找 lock_redo_blocked 事件。

使用性能监视器主动监视对恢复队列的阻止重做影响。 添加 SQL Server::D atabase Replica::Redo blocked/sec 和 SQL Server::D atabase Replica::Recovery 队列计数器。 以下屏幕截图显示了针对 ALTER TABLE ALTER COLUMN 主副本运行的命令,而长时间运行的查询针对次要副本上的同一个表运行。 Redo blocked/sec 计数器指示ALTER TABLE ALTER COLUMN命令正在运行。 尽管长时间运行的查询在次要副本上的同一个表上运行,但主副本上的任何后续更改都会导致恢复队列增加。

监视重做线程尝试获取的架构修改锁等待类型。 为此,请使用前面所述的查询来检查针对重做操作 sys.dm_exec_requests报告的等待类型。 可以观察正在进行的重做阻塞中不断增加的等待时间 LCK_M_SCH_M 。

单线程重做
SQL Server 为 Microsoft SQL Server 2016 中的辅助副本数据库引入了并行恢复。 如果在运行 SQL Microsoft Server 2012 或 Microsoft SQL Server 2014 时遇到恢复队列,则可以升级到更高版本的程序以提高生产环境中的重做性能。
在以后,可以使用并行恢复体系结构的更高级的 SQL Server 版本进行单线程重做。 在这些版本中,SQL Server 实例最多可以使用 100 个线程进行并行重做。 根据处理器和可用性组数据库的数量,并行重做线程最多分配 100 个线程。 如果达到 100 线程重做限制,则会为可用性组中的某些数据库分配一个重做线程。
若要确定可用性组数据库是否使用并行恢复,请连接到次要副本,并使用以下查询来确定为可用性组数据库应用恢复的行数(线程)。 在以下示例中,如果“agdb”数据库是单个线程,并且其命令是 DB STARTUP,则恢复工作负荷可能会受益于并行恢复。
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN ('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')

如果验证数据库是否使用单线程重做,请查看前面所述的算法,以确定 SQL Server 是否超过专用于并行恢复的 100 个工作线程数。 这种情况可能是“agdb”数据库只使用单个线程进行恢复的原因。
SQL Server 2022 现在使用新的并行恢复算法,以便根据工作负荷为并行恢复分配工作线程。 这样就消除了忙碌数据库保留在单线程恢复中的可能性。 有关详细信息,请参阅 “针对 AlwaysOn 可用性组的先决条件、限制和建议”的“按可用性组 使用的线程使用情况”部分。