适用范围:SQL Server
本文提供有关 I/O 问题导致 SQL Server 性能缓慢以及如何排查问题的指南。
缓慢的 I/O 性能定义
性能监视器计数器用于判断 I/O 性能是否缓慢。 这些计数器测量 I/O 子系统平均在时钟时间方面为每个 I/O 请求提供服务的速度。 测量 Windows 中 I/O 延迟的特定性能监视器计数器是Avg Disk sec/ Read、Avg. Disk sec/Write 和 Avg. Disk sec/Transfer(读和写的总和)。
在 SQL Server 中,事情的工作方式相同。 通常,您会查看 SQL Server 是否报告了以时钟时间(毫秒为单位)测量的任何 I/O 瓶颈。 SQL Server 通过调用 Win32 函数(例如WriteFile(),ReadFile()WriteFileGather()和ReadFileScatter())向 OS 发出 I/O 请求。 当它发出 I/O 请求时,SQL Server 会对请求进行计时,并使用等待类型报告请求的持续时间。 SQL Server 使用等待类型来指示产品中不同位置的 I/O 等待。 与 I/O 相关的等待有:
如果这些等待持续超过 10-15 毫秒,则 I/O 被视为瓶颈。
注意
为了提供上下文和视角,在 SQL Server 故障排除领域,Microsoft CSS 观察到一些案例,其中 I/O 请求用时超过一秒,甚至每次传输高达 15 秒,这类 I/O 系统需要进行优化。 相反,Microsoft CSS 已看到吞吐量低于 1 毫秒/传输的系统。 借助当今的 SSD/NVMe 技术,标称吞吐率在每次传输时可达到数十微秒。 因此,10-15 毫秒/次传输的数值是我们基于多年来 Windows 和 SQL Server 工程师的集体经验选择的一个非常近似的门槛。 通常,当数字超出此近似阈值时,SQL Server 用户开始看到工作负荷中的延迟并报告它们。 最终,I/O 子系统的预期吞吐量由制造商、型号、配置、工作负荷和可能多个其他因素定义。
方法
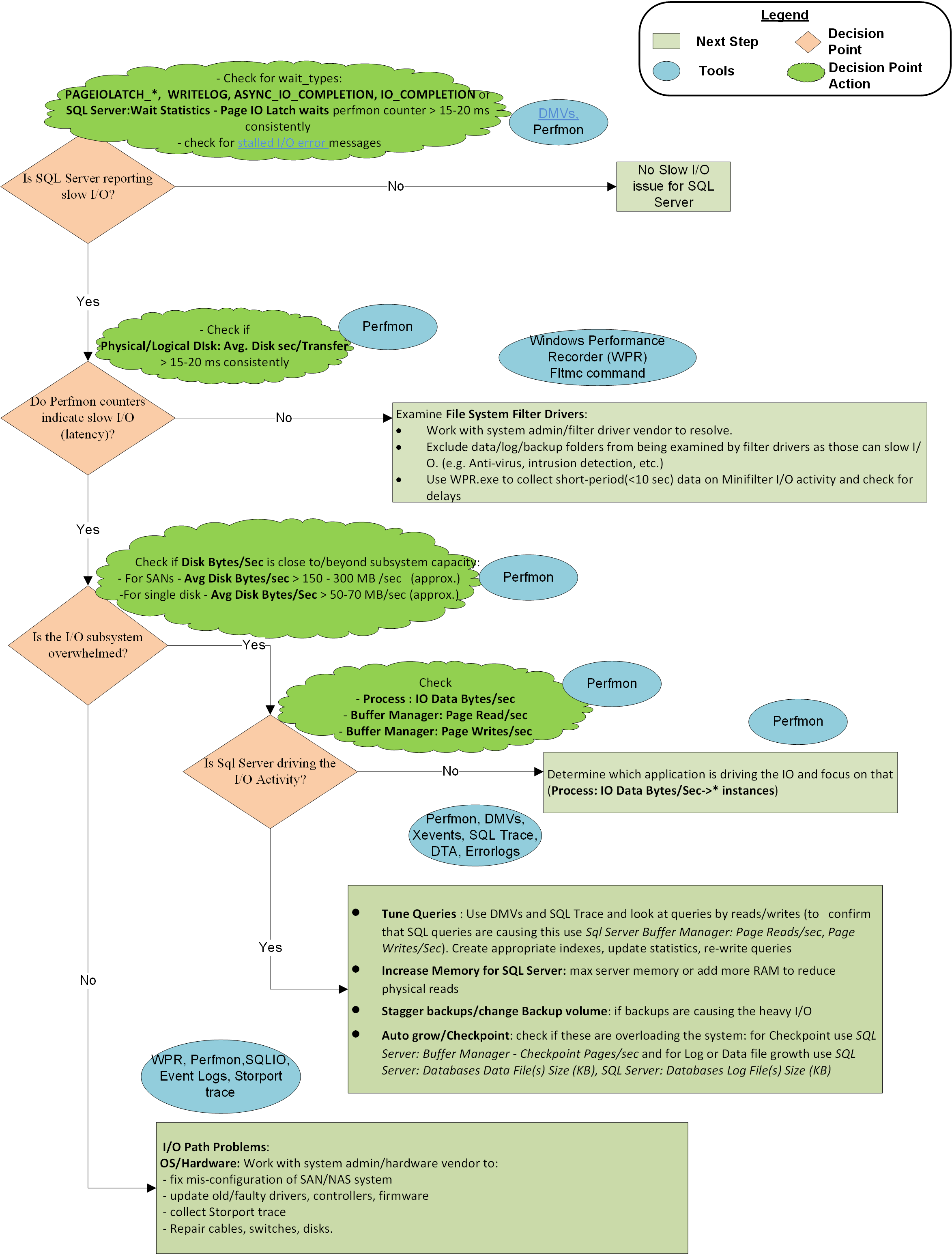
本文末尾的流程图描述了 Microsoft CSS 用于解决 SQL Server I/O 缓慢问题的方法。 这不是一种详尽或独占的方法,但它在隔离问题和解决问题方面已被证明是有用的。
这些步骤概述了该方法:
步骤 1:SQL Server 是否报告了 I/O 速度缓慢的问题?
SQL Server 可以通过多种方式报告 I/O 延迟:
- I/O 等待类型
- 车管所
sys.dm_io_virtual_file_stats - 错误日志或应用程序事件日志
I/O 等待类型
确定 SQL Server 等待类型是否报告了 I/O 延迟。 每个 I/O 请求的PAGEIOLATCH_*、WRITELOG和ASYNC_IO_COMPLETION的值以及其他几种不太常见等待类型的值通常应保持在10-15毫秒以下。 如果这些值一致更高,则存在 I/O 性能问题,需要进一步调查。 以下查询可能有助于收集有关系统上的此诊断信息:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
for ([int]$i = 0; $i -lt 100; $i++)
{
sqlcmd -E -S $sqlserver_instance -Q "SELECT r.session_id, r.wait_type, r.wait_time as wait_time_ms`
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s `
ON r.session_id = s.session_id `
WHERE wait_type in ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX', 'WRITELOG', `
'IO_COMPLETION', 'ASYNC_IO_COMPLETION', 'BACKUPIO')`
AND is_user_process = 1"
Start-Sleep -s 2
}
sys.dm_io_virtual_file_stats中的文件统计信息
若要查看 SQL Server 中报告的数据库文件级延迟,请运行以下查询:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT LEFT(mf.physical_name,100), `
ReadLatency = CASE WHEN num_of_reads = 0 THEN 0 ELSE (io_stall_read_ms / num_of_reads) END, `
WriteLatency = CASE WHEN num_of_writes = 0 THEN 0 ELSE (io_stall_write_ms / num_of_writes) END, `
AvgLatency = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE (io_stall / (num_of_reads + num_of_writes)) END,`
LatencyAssessment = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 'No data' ELSE `
CASE WHEN (io_stall / (num_of_reads + num_of_writes)) < 2 THEN 'Excellent' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 2 AND 5 THEN 'Very good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 6 AND 15 THEN 'Good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 16 AND 100 THEN 'Poor' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 100 AND 500 THEN 'Bad' `
ELSE 'Deplorable' END END, `
[Avg KBs/Transfer] = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE ((([num_of_bytes_read] + [num_of_bytes_written]) / (num_of_reads + num_of_writes)) / 1024) END, `
LEFT (mf.physical_name, 2) AS Volume, `
LEFT(DB_NAME (vfs.database_id),32) AS [Database Name]`
FROM sys.dm_io_virtual_file_stats (NULL,NULL) AS vfs `
JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id `
AND vfs.file_id = mf.file_id `
ORDER BY AvgLatency DESC"
查看AvgLatency和LatencyAssessment列以了解延迟详细信息。
Errorlog 或应用程序事件日志中报告的错误 833
在某些情况下,可能会在错误日志中观察到错误 833 SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database [%ls] (%d) 。 可以通过运行以下 PowerShell 命令来检查系统上的 SQL Server 错误日志:
Get-ChildItem -Path "c:\program files\microsoft sql server\mssql*" -Recurse -Include Errorlog |
Select-String "occurrence(s) of I/O requests taking longer than Longer than 15 secs"
此外,有关此错误的详细信息,请参阅 MSSQLSERVER_833 部分。
步骤 2:Perfmon 计数器是否指示 I/O 延迟?
如果 SQL Server 报告 I/O 延迟,请参阅 OS 计数器。 可以通过检查延迟计数器 Avg Disk Sec/Transfer来确定是否存在 I/O 问题。 以下代码片段指示通过 PowerShell 收集此信息的一种方法。 它会收集所有磁盘卷上的计数器信息:“_total”。 更改为特定驱动器卷(例如“D:”)。 若要查找托管数据库文件的卷,请在 SQL Server 中运行以下查询:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT DISTINCT LEFT(volume_mount_point, 32) AS volume_mount_point `
FROM sys.master_files f `
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) vs"
收集 Avg Disk Sec/Transfer 所选卷上的指标:
clear
$cntr = 0
# replace with your server name, unless local computer
$serverName = $env:COMPUTERNAME
# replace with your volume name - C: , D:, etc
$volumeName = "_total"
$Counters = @(("\\$serverName" +"\LogicalDisk($volumeName)\Avg. disk sec/transfer"))
$disksectransfer = Get-Counter -Counter $Counters -MaxSamples 1
$avg = $($disksectransfer.CounterSamples | Select-Object CookedValue).CookedValue
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 30 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 5))
turn = $cntr = $cntr +1
running_avg = [Math]::Round(($avg = (($_.CookedValue + $avg) / 2)), 5)
} | Format-Table
}
}
write-host "Final_Running_Average: $([Math]::Round( $avg, 5)) sec/transfer`n"
if ($avg -gt 0.01)
{
Write-Host "There ARE indications of slow I/O performance on your system"
}
else
{
Write-Host "There is NO indication of slow I/O performance on your system"
}
如果此计数器的值一直高于 10-15 毫秒,则需要进一步查看问题。 在大多数情况下,偶尔的峰值不会计数,但请务必仔细检查峰值的持续时间。 如果峰值持续了一分钟或更长时间,它更像是高原而不是峰值。
如果性能监视器计数器没有报告延迟,但 SQL Server 报告了延迟,则问题在于 SQL Server 和分区管理器之间,也就是筛选驱动程序。 分区管理器是 OS 收集 Perfmon 计数器的 I/O 层。 若要解决延迟问题,请确保正确排除筛选器驱动程序并解决筛选器驱动程序问题。 筛选器驱动程序由防病毒软件、备份解决方案、加密、压缩等程序使用。 可以使用此命令列出系统上的筛选器驱动程序及其附加到的卷。 然后,可以在“分配的筛选器高度”一文中查找驱动程序名称和软件供应商。
fltmc instances
有关详细信息,请参阅 如何选择要在运行 SQL Server 的计算机上运行的防病毒软件。
避免使用加密文件系统(EFS)和文件系统压缩,因为它们会导致异步 I/O 同步,因此速度变慢。 有关详细信息,请参阅文章《Windows 上异步磁盘 I/O 似乎是同步的》。
步骤 3:I/O 子系统是否超出容量?
如果 SQL Server 和操作系统表示 I/O 子系统速度缓慢,请检查是否是因为系统超出了容量。 可以通过查看 I/O 计数器Disk Bytes/Sec或Disk Read Bytes/SecDisk Write Bytes/Sec检查容量。 请务必与系统管理员或硬件供应商核实 SAN(或其他 I/O 子系统)的预期吞吐量规范。 例如,可以通过传输速率为 2 GB/秒的 SAN 交换机上的 HBA 卡或专用端口传输不超过 200 MB/秒的 I/O。 硬件制造商定义的预期吞吐量容量定义从此处开始的运行方式。
clear
$serverName = $env:COMPUTERNAME
$Counters = @(
("\\$serverName" +"\PhysicalDisk(*)\Disk Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Read Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Write Bytes/sec")
)
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 20 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 3)) }
}
}
步骤 4:SQL Server 是否驱动大量 I/O 活动?
如果 I/O 子系统超出容量,请查看特定实例中的 Buffer Manager: Page Reads/Sec(最常见的罪魁祸首)和 Page Writes/Sec(不太常见),以确定 SQL Server 是否是问题的根源。 如果 SQL Server 是主要的 I/O 驱动且 I/O 负荷超出了系统的处理能力,请与应用程序开发团队或应用程序供应商合作:
- 优化查询,例如:更好的索引、更新统计信息、重写查询和重新设计数据库。
- 增加 最大服务器内存 或在系统上添加更多 RAM。 更多的 RAM 将缓存更多的数据或索引页,而无需频繁从磁盘重新读取,这将减少 I/O 活动。 增加的内存还可以减少
Lazy Writes/sec,当经常需要将更多数据库页存储在有限的内存中时,延迟编写器刷新会驱动这些内存。 - 如果发现页面写入导致大量 I/O 活动,请检查
Buffer Manager: Checkpoint pages/sec来确定是否由于满足恢复间隔配置需求所需的大量页面刷新造成的。 可以使用 间接检查点 来均衡 I/O 随时间分配,或者增加硬件 I/O 吞吐量。
原因
一般情况下,以下问题是 SQL Server 查询遭受 I/O 延迟的高级别原因:
硬件问题:
SAN 配置错误(交换机、电缆、HBA、存储)
超出 I/O 容量(整个 SAN 网络不均衡,而不仅仅是后端存储)
驱动程序或固件问题
硬件供应商和/或系统管理员需要在此阶段参与。
查询问题: SQL Server 使用 I/O 请求使磁盘卷饱和,并且正在将 I/O 子系统推送到容量之外,这会导致 I/O 传输速率较高。 在这种情况下,解决方案是查找那些导致大量逻辑读取或写入的查询,并优化这些查询以最大程度地减少磁盘 I/O。使用适当的索引是实现这一目标的第一步。 此外,请保持统计信息的更新,以便为查询优化器提供足够的信息来选择最佳计划。 此外,不正确的数据库设计和查询设计可能会导致 I/O 问题增加。 因此,重新设计查询以及有时重新设计表可能有助于改进 I/O。
筛选器驱动程序: 如果文件系统筛选器驱动程序处理大量 I/O 流量,SQL Server I/O 响应可能会受到严重影响。 建议软件供应商在防病毒扫描中排除适当的文件,以及正确的筛选器驱动程序设计,以防止对 I/O 性能造成影响。
其他应用程序: 使用 SQL Server 的同一台计算机上的另一个应用程序可能会饱和 I/O 路径,并出现过多的读取或写入请求。 这种情况可能会将 I/O 子系统推送到容量限制之外,并导致 SQL Server 的 I/O 速度缓慢。 确定应用程序并对其进行优化或将其移到其他位置,以消除其对 I/O 堆栈的影响。
方法的图形表示形式
有关 I/O 相关等待类型的信息
以下是报告磁盘 I/O 问题时在 SQL Server 中观察到的常见等待类型的说明。
PAGEIOLATCH_EX
当任务在 I/O 请求中等待数据或索引页(缓冲区)的闩锁时发生。 闩锁请求处于独占模式。 将缓冲区写入磁盘时,将使用独占模式。 长时间的等待可能指示磁盘子系统出现问题。
PAGEIOLATCH_SH
当任务在 I/O 请求中等待数据或索引页(缓冲区)的闩锁时发生。 闩锁请求处于共享模式。 从磁盘读取缓冲区时,将使用共享模式。 长时间的等待可能指示磁盘子系统出现问题。
PAGEIOLATCH_UP
当任务正在等待 I/O 请求中的缓冲区的闩锁时发生。 闩锁请求处于更新模式。 长时间的等待可能指示磁盘子系统出现问题。
WRITELOG
当任务正在等待事务日志刷新完成时发生。 当日志管理器将其临时内容写入磁盘时,会发生刷新。 导致日志刷新的一些常见操作包括事务提交和检查点。
长时间等待 WRITELOG 的常见原因是:
事务日志磁盘延迟:这是最常见的等待原因
WRITELOG。 通常,建议将数据和日志文件保留在单独的卷上。 写入事务日志是顺序进行的,而从数据文件读取或写入数据是随机进行的。 在一个驱动器卷(尤其是传统的旋转磁盘驱动器)上混合数据和日志文件将导致磁盘头移动过多。过多的 VLF:过多的虚拟日志文件(VLF)可能会导致
WRITELOG等待。 过多的 VLF 可能会导致其他类型的问题,例如恢复时间过长。事务过多:虽然大型事务可能导致阻塞,但过多的小事务可能导致另一组问题。 如果未显式开始事务,任何插入、删除或更新都会触发一个事务(这称为自动事务)。 如果在循环中插入 1,000 个项目,将生成 1,000 个事务。 此示例中的每个事务都需要提交,这会导致事务日志刷新和 1,000 个事务刷新。 如果可能,请将单个更新、删除或插入操作组合到更大的事务中,以减少事务日志刷新,并提高性能。 此操作可能会导致等待时间减少
WRITELOG。调度问题导致日志编写器线程未能被足够快地调度:在 SQL Server 2016 之前,单个日志编写器线程执行了所有日志写入。 如果线程计划出现问题(例如 CPU 较高),则日志编写器线程和日志刷新都可能会延迟。 在 SQL Server 2016 中,最多添加了四个日志编写器线程,以提高日志写入吞吐量。 请参阅 SQL 2016 - 就是跑得更快:多个日志写入工作线程。 在 SQL Server 2019 中,最多添加了 8 个日志编写器线程,从而提高了吞吐量。 此外,在 SQL Server 2019 中,每个常规工作线程都可以直接执行日志写入,而不是发布到日志编写器线程。 通过这些改进,由于调度问题引发的等待将极少发生。
ASYNC_IO_COMPLETION
在发生以下某些 I/O 活动时发生:
- 执行 I/O 时,批量插入提供程序(“Insert Bulk”)使用此等待类型。
- 在日志传送中读取撤消文件,并管理用于日志传送的异步 I/O 操作。
- 在数据备份期间从数据文件读取实际数据。
IO_COMPLETION
在等待 I/O 操作完成时出现。 此等待类型通常涉及与数据页(缓冲区)无关的 I/O。 示例包括:
- 在溢出期间,从磁盘读取和写入排序和哈希结果(检查 tempdb 存储的性能)。
- 将预处理缓存读写到磁盘(检查 tempdb 存储)。
- 从事务日志读取日志块(在导致日志从磁盘读取的任何操作期间,例如恢复)。
- 尚未设置数据库时从磁盘读取页面。
- 将页面复制到数据库快照(写入时复制)。
- 关闭数据库文件和解压文件。
BACKUPIO
当备份任务正在等待数据或等待缓冲区存储数据时发生。 除非任务正在等待磁带装载,否则此类型并不典型。