本文档为音频设备的设计和开发提供建议,包括旨在与 Microsoft 语音平台一起使用的音频播放和音频输入设备。 语音平台用于支持 Windows 中的所有语音体验,例如语音键入和实时字幕。 本文档的目的帮助生态系统合作伙伴使用 Microsoft 技术构建具有优化音频体验的设备。
最低硬件要求和 Windows 硬件兼容性计划
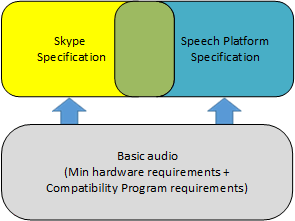
最低硬件要求和 Windows 硬件兼容性计划要求是创建 Windows 兼容的音频解决方案的基础。 尽管这些计划是可选的,但我们强烈建议音频产品满足这两套要求,以确保基本的音频质量。
有关每套要求的更多详细信息:
参阅最低硬件要求中的第 6.2.2 部分
优化多流音频播放的方案
尽管多流不再是 Windows 10 桌面版中的要求,但我们强烈建议至少提供两个数模转换器 (DAC) 来支持多流方案。 如果使用单个 DAC(例如重定向耳机),我们强烈建议单独为每个音频终结点(例如集成扬声器或 3.5mm 音频插孔)支持音频音量控制和状态,以便可以保留用户的设置偏好。
优化用于语音和通信的音频解决方案
在音频解决方案能够满足最低硬件要求和 Windows 兼容性计划要求后,它将在 Windows 中提供基本的音频体验。 根据目标细分市场,一个设备可以支持两项额外的优化:语音平台和 Skype。 针对语音平台和 Skype 的建议都建立在基本音频体验的要求基础之上。 如果音频解决方案不能完全满足基本要求,在优化语音平台或 Skype 时将会面临挑战。
注意
当针对电话和 Skype 等应用程序的指导原则可用时,我们将在本主题中补充这些内容。
Windows 中的语音识别
建议设备制造商优化语音增强处理并将其集成到他们的设备中,以优化语音识别测试条件相关的性能。
对于没有集成式语音增强处理的设备,Microsoft 将在 Windows 10 中提供默认处理。 Microsoft 的语音增强处理不需要 IHV 进行设备特定的优化。
如果音频驱动程序不公开麦克风几何结构和语音的音频信号处理,则会使用 Microsoft 语音增强管道。 若要利用第三方增强功能,必须提供麦克风几何结构,支持音频输入的“语音”信号处理模式,并确保音频驱动程序或其软件 APO 提供的效果至少包括噪声抑制和回声消除。
语音识别与电话之间的差别
许多以语音识别功能为目标的设备也将以电话用途为目标。 相似之处非常明显 – 这两种方案使用的设备都配备了用于拾取人类语音的麦克风,用于消除环境噪音和增强人类语音的音频处理管道,以及依赖于清晰语音信号来理解语音的应用程序。
不同之处在于,谁或哪个对象使用了语音信号。 电话的使用者为人类,对他们而言,感知性语音的质量和语音清晰度极其重要。 语音识别的使用者为算法,基于语音信号的特定特征训练的机器学习确定识别的内容,而这些特征不一定需要符合感知法则。
感知性语音的质量通常与语音识别准确度相关,但并非总是如此。 本文档将重点介绍评估和最大化语音识别准确度的方法。 建议支持“语音”信号处理模式,并专门为语音识别优化该模式。
通过 Skype/Lync 音频认证是良好设备音频性能的强有力指标。
音频设备建议
以下部分提供有关语音的建议。 为确保高质量的语音体验,应根据这些性能要求测试所有设备。
| 区域 | 指导类型 | 应测试哪些设备 |
|---|---|---|
| Device.SpeechRecognition | 提供语音识别性能要求,以确保高质量的语音体验。 | 应根据这些性能要求测试所有设备。 |
| Device.Audio | 提供指导原则,使软件接口、通信协议和数据格式能够配合主机操作系统以最佳方式正常运行。 | 应根据这些指导原则测试所有设备。 |
| Device.Audio.Acoustics | 提供设备设计的声学和相关属性的建议与最佳做法。 | 与使用 Microsoft 语音增强处理的设备最相关。 |
Device.SpeechRecognition
下表汇总了 Microsoft 针对各种环境中设备的目标语音识别准确度提供的建议。 所有目标都保持语音识别准确度。
| 测试 | 说明 | 目标 | 建议 |
|---|---|---|---|
| Device.SpeechRecognition.Quiet | 环境噪声极低(本底噪声 < 35 dBA SPL)且没有接收(回声路径)噪声的理想环境。 | 安静度 <= 35 dBA SPL | 95% |
| Device.SpeechRecognition.AmbientNoise | 各种级别和类型的嘈杂环境,例如咖啡厅和酒吧。 | 环境噪声 @ DUT >= 57 dBA SPL | 90% |
| Device.SpeechRecognition.EchoNoise | 各种级别和类型的渲染播放方案(例如媒体播放)。 | 回声噪声 @ LRP >= 70 dBA SPL | 90% |
Device.Audio
本部分提供的建议与设备的软件和硬件接口、通信协议和数据格式相关。 旨在使用语音识别功能的设备必须满足所有 Device.Audio 要求。
| 名称 | 建议 |
|---|---|
| Device.Audio.Base.AudioProcessing | 驱动程序必须通过 FXStreamCLSID、FXModeCLSID 和 FXEndpointCLSID APO(或代理 APO)公开所有音频效果。 在查询 APO 时,APO 必须向系统发送准确的已启用效果列表。 驱动程序必须支持 APO 更改通知,并且仅在发生了 APO 更改时才通知系统。 |
| Device.Audio.Base.StreamingFormats | 采用 StreamingFormats HLK 中定义的所有音频捕获和渲染流格式(最佳值为 16 kHz,24 位捕获和单声道渲染)的语音识别功能。 |
| Device.Audio.Base.SamplePositionAccuracy | 渲染和捕获音频信号必须 1) 准确采样;2) 准确提供时间戳。 |
| Device.Audio.USB.USB | 所有 USB 音频输入设备必须根据 USB.org 设备类规范正确设置描述符。 |
| 驱动程序指导原则 | WDM 音频驱动程序开发路线图 |
Device.Audio.Acoustics
本部分提供的建议与设备的声学和相关属性有关,例如麦克风和扬声器的定位、麦克风响应、从设备接收的噪声等。 要支持优质的语音识别性能,麦克风选择、定位、集成和阵列设计是最重要的一部分考虑因素。
建议和测试与完成语音增强处理之前、但设置麦克风均衡和固定麦克风增益之后的信号有关。
有关所有这些建议(包括建议的麦克风阵列几何结构)的更多详细信息,请参阅麦克风阵列几何结构描述符格式。
| 名称 | 建议 |
|---|---|
| Device.Audio.Acoustics.MicArray | 请参阅 Windows 中的麦克风阵列支持。 音频驱动程序必须实现 KSPROPERTY_AUDIO_MIC_ARRAY_GEOMETRY 属性。 然后可以通过 Windows.Devices.Enumeration API 访问 System.Devices.MicrophoneArray.Geometry 属性。 USB 音频驱动程序将支持在 USB 描述符中设置了相应字段的 USB 麦克风阵列的此属性。 |
| 麦克风阵列描述符 | 设备必须使用麦克风阵列描述符来描述其麦克风类型和几何结构。 |
| Device.Audio.Acoustics.MicSensitivity | “最大值”建议设置为能够支持被认为“响亮”的语音输入级别,“最小值”建议设置为能够支持被认为“安静”的语音输入级别。 |
| Device.Audio.Acoustics.MicIntegration | 必须集成麦克风,以确保麦克风和设备机箱之间的良好声学密封性,如果适用,则还应配备麦克风回音管。 尽量减少系统与麦克风之间的声学噪声和振动。 两种典型的解决方案是使用橡胶套或垫圈。 无论选择哪种方法,都要检查声学密封性是否足以应对所有生产公差以及环境和工作寿命变化。 |
| Device.Audio.Acoustics.MicPlacement | 将麦克风定位在尽可能远离扬声器、风扇、键盘、硬盘驱动器和用户手部等噪声源的位置,并尽可能靠近扬声器的喇叭口处。 |
| Device.Audio.Acoustics.MicSelfNoise | 使用高质量的麦克风可以最大程度地降低麦克风的内部噪声。 建议使用 SNR 至少为额定 61 dB 的麦克风实现“标准”级别,使用额定 63 dB 的麦克风实现“高级”级别。 |
| Device.Audio.Acoustics.MicReceivedNoise | 接收噪声的两个主要来源是声学噪声和电噪声。 声学噪声可能来自设备外部,也可能由于风扇、硬盘等原因而在设备内部产生。声学噪声还可能通过设备机械部件传播。 可以使用数字麦克风(而不是模拟麦克风)来最大程度地降低电噪声。 |
| Device.Audio.Acoustics.MicMagnitudeResponse | “高级”和“标准”屏蔽适用于 Device.Audio.Acoustics.Bandwidth 下的所有设备层,例如,设备可能具有“标准”带宽(窄带),但在该频带内具有“高级”幅频响应。 |
| Device.Audio.Acoustics.MicPhaseResponseMatching | 此项建议可确保通过阵列中麦克风元件接收的信号之间的临时关系与阵列中麦克风元件的物理几何结构相一致。 |
| Device.Audio.Acoustics.MicDistortion | 尽管也给出了 THD 目标,但建议使用 SDNR(脉冲信号失真噪声比)来测量失真。 |
| Device.Audio.Acoustics.MicBandwidth | 捕获信号的采样率是确定语音信号有效带宽的主要因素。 由于语音平台在语音识别器中使用 16 kHz 声学模型,因此建议使用 16 kHz 的最小采样率。 300 Hz 是语音识别器的有效下限,但是对于同样以语音通信为目标的设备,建议的声学限制为 200 Hz。 |
| Device.Audio.Acoustics.RenderDistortion | 尽管也给出了 THD 目标,但建议使用 SDNR(脉冲信号失真噪声比)来测量失真。 |
| Device.Audio.Acoustics.RenderPlacement | 要使回声消除器正常工作,应将设备扬声器定位在距离麦克风最远的位置,或将定向性零点朝向扬声器。 |
启用第三方增强管道的要求
以下要求对于启用第三方增强管道非常关键。 以下部分更详细地介绍了这些建议和其他建议:
麦克风位置报告 – 解释如何实现麦克风阵列的报告结构。
语音模式支持:
如何为特定模式注册 APO
音频信号处理模式
Device.Audio.Base.Audioprocessing – 第三方管道需要回声消除 (AEC) 和噪声抑制 (NS):
实现音频处理对象
音频处理对象体系结构