本文介绍了通过 SR-IOV(单根 I/O 虚拟化)分区虚拟化的异构计算设备(GPU、NPU 等)实时迁移的功能设计。 通过 WDDM 和 MCDM 驱动程序模型支持分区的设备现已成为我们虚拟化产品不可或缺的一部分。 因此,必须支持实时迁移并帮助我们的虚拟化抽象实现最大程度的可靠性,以避免资源分配必须改变时对客户造成的影响。 本文还介绍了这些设备的快速迁移。
从 Windows 11 版本 24H2 (WDDM 3.2) 开始支持实时迁移。 更广泛地说,它是 GPU 半虚拟化 (GPU-P) DDI 的扩展,用于公开该功能的驱动程序。 实施 GPU-P 虚拟化接口的 MCDM 驱动程序也可选择实施这些实时迁移接口,包括其与分流事件的扩展。
在本文中,“GPU”仅指实施 GPU-P 虚拟化框架的设备,无论是 WDDM 还是 MCDM,也无论是 GPU、NPU 还是其他异构计算设备。
资源迁移的种类和目的
资源迁移是将虚拟化移动到新物理资源的功能。 移动虚拟化执行有多种方式,包括:
硬关机。 虚拟主板可直接断电,从而停止执行虚拟资源。 任何不具有电源容错的应用程序都会丢失正在运行的数据,并且所有设备状态都会被清除。 然后,虚拟硬盘 (VHD) 可以在不同的主机上虚拟化,从而实现冷启动。
软关机。 这种关机与硬关机不同,它只是向来宾 OS 发送关机请求。 然后,来宾 OS 将断电机制分配给应用程序,以便彻底关机。 应用程序可利用此通知安全地存储所有数据,并在启动时注册重启,但这取决于每个应用程序的编程。 软关机要求来宾 OS 支持这种完全关机机制,并支持适当的服务来存储当前状态并在重启时重新启动。
休眠。 另一种来宾启动技术允许来宾过渡到快速启动的睡眠电源状态,在这种状态下,所有应用进程都会被冻结,设备状态会被清除到 CPU 内存中,然后所有内存都会被发送到存储空间,以便让硬件关闭电源。 然后,可以在另一台机器上重新启动虚拟机存储 VHD,并加载内存、还原设备状态和解冻进程。 只有支持的来宾 OS 才能使用休眠功能。 这是一个相当具有侵入性的过程,依赖于客户机的稳定性,但它提供了一种机制来还原应用程序进程的状态,这是关机机制所不能提供的。
快速迁移(也称为 VM 保存和还原)。 利用这种技术,VM 会暂停(vCPU 停止调度),并在主机 OS 中收集还原新物理资源状态所需的所有状态,包括 VM 的内存和所有设备的状态。 然后,此状态会被传输到新主机,新主机会创建一个已加载所有 vCPU 上下文的 VM,将内存映射到 VM 空间并还原设备状态。 然后,PowerOnRestore 会重新启动 vCPU 的执行。 此技术独立于来宾 OS,不依赖于客户环境中的执行,因此是比休眠更可靠的保持进程和设备状态的方法。 虚拟化用户可能会注意到明显的停机时间,因为 VM 内存可能会有很多 GB,传输时间也会很明显。
实时迁移。 如果我们有能力在虚拟化资源仍处于活动状态的情况下传输内容,并且可以跟踪被弄脏的内容,那么就可以在保持虚拟化处于活动状态的情况下传输大量内容。 这样,当 VM 暂停时,需要传输的内容就会大大减少,我们就能最大限度地减少不执行虚拟化的时间。 这样做能够最大限度地减少对终端用户的影响,因为迁移过程中发生的所有操作都不会受到影响,对资源消耗率的影响也会尽可能地降低。 特别是,这样可以最大限度地减少或消除中断期限(虚拟化中断的外部时间限制,如外部端点的 TCP 和其他协议超时)。
每一个进展都会减少或消除客户对虚拟化物理分配变化的一些(通常是主要的)感知,从而让虚拟化对用户越来越完整和透明。 它与其他将客户对基础设施的依赖性分离出来的技术(如主机崩溃隔离)一起,它让我们的虚拟化解决方案朝着分配独立和真正的短暂计算的理想方向发展。
大规模设计
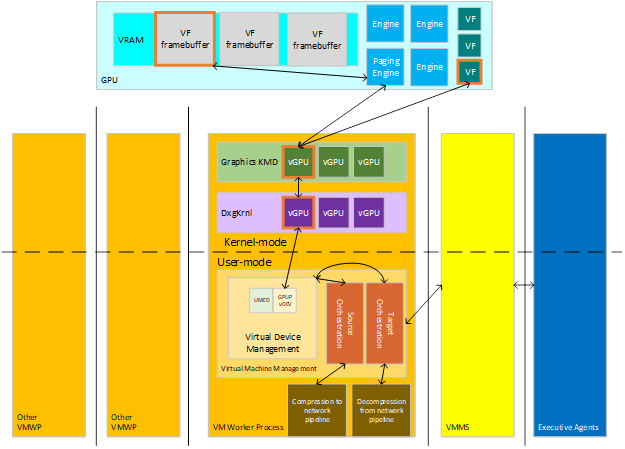
实时迁移会将虚拟化内容从源主机传输到目标主机。 虚拟化由各种有状态设备组成,包括内存、计算和存储设备,每个设备都有必须从源设备传输到目标设备的数据。 跨群集管理虚拟化的执行代理会与主机通信,让主机知道要为现有虚拟机的源迁移(当内容离开主机时)或向新虚拟机的目标迁移(接收内容)设置编排。 这种互动的主要参与者如下图所示。
:
源主机的时期
下图演示了源端迁移状态。
: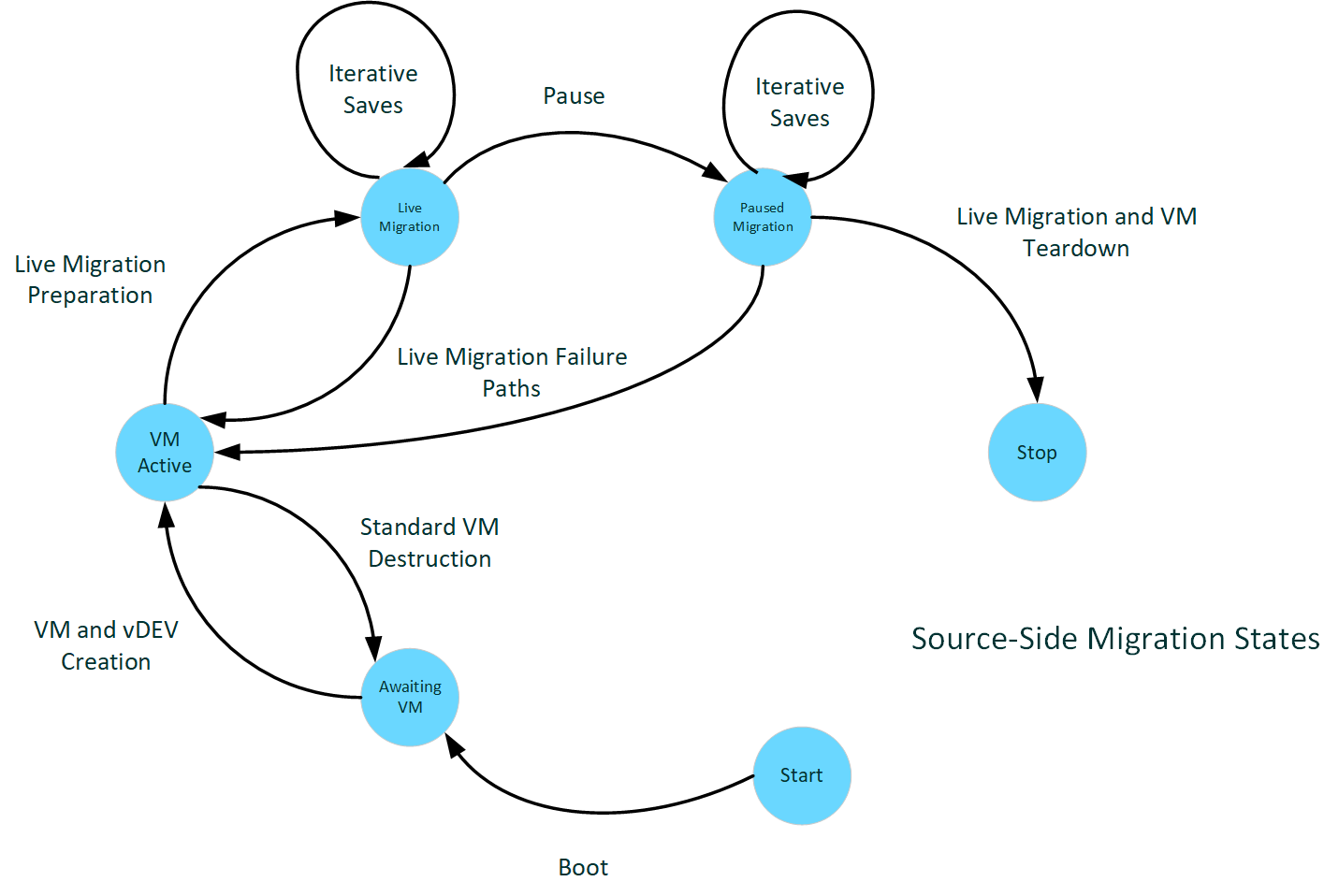
源端启动
一般情况下,当主机启动时,KMD 会通过各种初始化调用向内核报告设备能力。
当 KMD 收到 DXGKQAITYPE_GPUPCAPS 数据的 DxgkDdiQueryAdapterInfo 调用时,它可以设置添加到 DXGK_GPUPCAPS 的 LiveMigration 能力位。 当 KMD 设置该位时,它表示驱动程序支持实时迁移。
支持实时迁移的前提条件是支持跟踪所有 GPU 本地内存段上已修改的 VRAM 页面,如脏位跟踪中所述。 该支持通过其他指定信息类型的其他 DxgkDdiQueryAdapterInfo 调用进行报告。 报告支持实时迁移的驱动程序还必须报告支持脏位跟踪。 支持实时迁移但不支持脏位跟踪的配置无效,并且 Dxgkrnl 无法启动适配器。
VM 在线
一旦主机启动并且管理堆栈上线,虚拟机活动就会开始上线。 启动和停止 VM 的请求开始到达,我们开始看到 GPU-P vGPU 被投射到这些虚拟化中。
假定具备高性能脏位平面能力,Dxgkrnl 将在为 VF(虚拟函数)预留 VRAM 资源后调用 DxgkDdiStartDirtyTracking,这样将允许系统在 VF 稍后参与迁移的情况下跟踪 VRAM 的清洁度。
此 VM 启动后会开始拦截中断表访问以虚拟化中断支持,而这将在 VM 的整个生命周期内持续进行。
实时迁移发送准备
管理堆栈会根据控制指示发送开始实时迁移的事件,迁移状态机管理会从虚拟设备中收集虚拟化期间不可更改的所有状态(vGPU 分区配置指标),以便在目标上重建 vGPU。 准备就绪后,传输缓冲区的准备和传输栈的初始化过程就会开始。
此时期生成对引入的 DxgkDdiPrepareLiveMigration DDI 的调用。 KMD 应制定 PF/VF 调度策略,以便让实时迁移能够从主机的 VRAM 中流式传输脏内容,同时为 VF 保持公平的性能。 如果脏追踪被报告为不执行,则脏追踪也会从这一点开始。
实时迁移发送
:
然后,我们将进入脏 VRAM 传输的活动阶段。 此阶段包括调用脏位平面 DDI 来获取 VF 帧缓冲区的快照,然后将这些页面从 GPU 分页到之前准备好的 CPU 缓冲区。
在传输中的某个阶段,VM 及其所有虚拟设备都会暂停。 可以停止为来宾安排 VF,此时,可以为 PF 提供额外的时间分区来完成内容分页。 由于 VM 中的 VF 和 vCPU 都已暂停,因此在此之后,被迁移的内容(CPU 或设备本地内存)不应再有任何变化。
暂停的迁移发送
脏页的最后一次迭代是在暂停时传输的。 此时,系统会调用最后的设备和驱动程序状态碎片,这些碎片在激活时是可变的,但在之前的准备过程中无法传输。 此状态可以是另一端需要重建的任何状态、任何跟踪结构,或者一般来说是最终还原目标方 VF 状态所需的所有信息。
实时迁移拆解
最后,一旦 VM 及其所有虚拟设备将其状态转移到新的物理实现中,源端就可以清理 VM 残余。 缓冲区和其他迁移状态被清除,并且 vGPU 会被销毁。
目标主机的时期
下图演示了目标端迁移状态。
: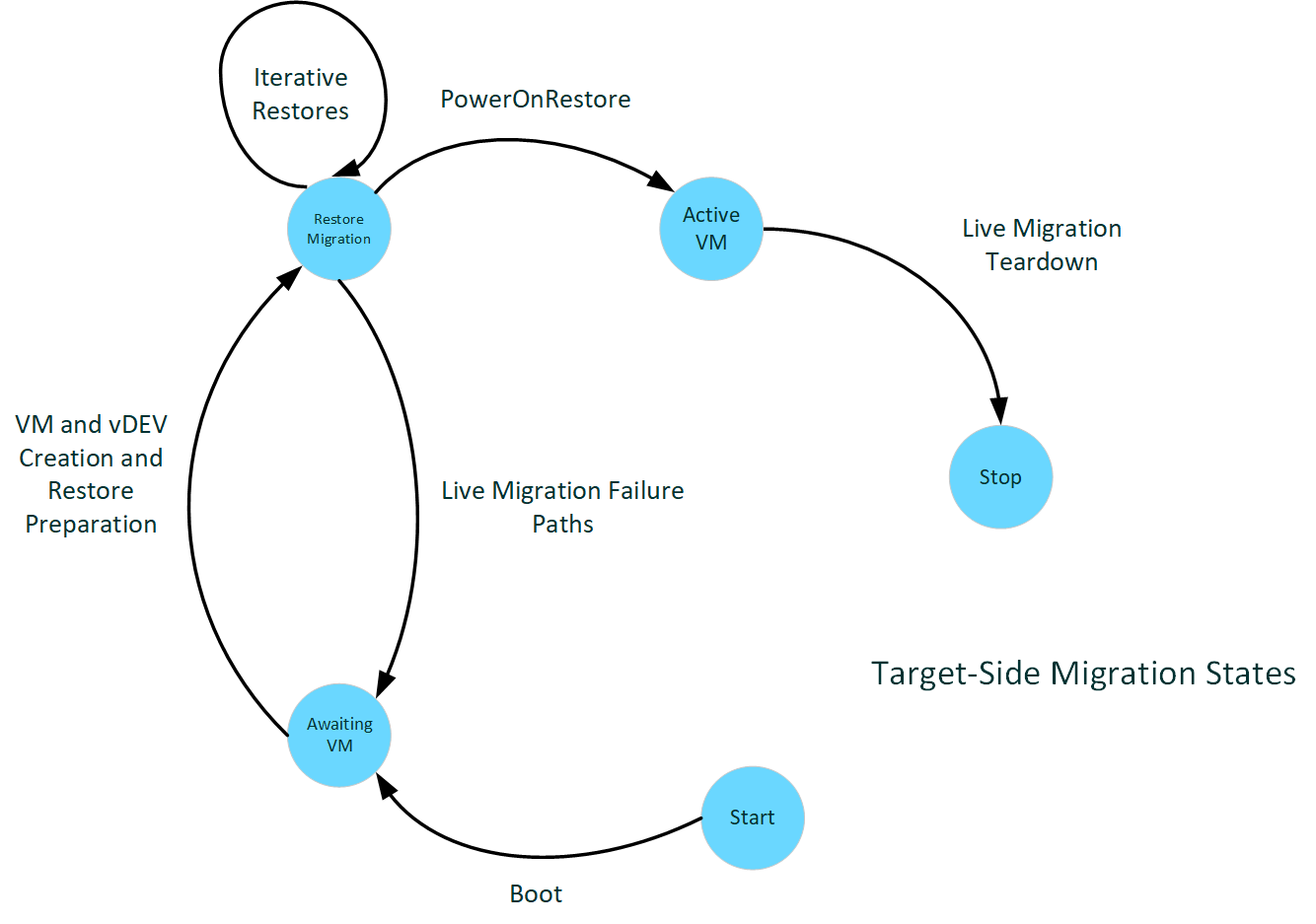
目标端启动
目标机上的启动与源机上的启动相同。 启动是针对整个系统的,在整个生命周期中,系统可以是不同 VM 的源和目标。 驱动程序只需指定支持实时迁移即可参与。
实时迁移接收准备
在目标端,VM 将像新 VM 一样开始构建。 创建 VM 和虚拟设备。 此创建过程包括虚拟 GPU,创建时所用的参数与在源端创建时相同。 创建完成后,会收到验证数据并将其传递给驱动程序,以验证目标端是否与源端兼容,从而还原 VM。 此时,应确保任何可能影响兼容性的因素,包括驱动程序版本、固件版本以及目标系统和驱动程序的其他环境状态。 驱动程序将配置为允许 PF 访问通常分配给 VF 的分页的所有时间,而 VF 尚未处于活动状态。
实时迁移接收
:
接收脏页数据的过程与源阶段类似,只是分页方向是从 CPU 缓冲区到 VRAM。 所有传输都是在 VF 暂停时进行的,因此整个传输都可以在 VF 预算内完成。
VM 启动和拆解
完成所有 VRAM 迁移后,vGPU 将有机会设置需要传输的其他状态(最终可变保存数据)。 然后,我们在目标机上启动 VM 并拆解迁移状态,包括用于传输的缓冲区。
性能目标
实时迁移的一个重要部分是其响应能力。 具体而言,它会最大程度地减少虚拟化的停机时间,因为虚拟化不会在外部做出响应(无论是对虚拟化的用户,还是可能进一步连接到的任何终结点)。 许多网络堆栈协议在重试/重建失败前,远程机器上的超时时间都很短,因此一旦超时,就会对用户造成干扰。 作为一个常见的固定目标,传输和启动的总停顿时间应低于四分之三秒(750 毫秒),这样就能将脱离接触的时间降低到许多最常见的堆栈超时时间之下。
此外,如果可能,活动系统的性能变化不应引发其他终端用户的中断。 在使用这些 DDI 的设备中,系统不应通过减慢时间片计划来显著提高 TDR 的速率。 现在,我们预计大多数 TDR 都不是长数据包,而是挂起的设备,执行数据包的时间增加一倍或两倍应该不会使大多数数据包达到超过数秒的明显超时。 但需要注意的是,在总体性能情况下,不要触发超时。
设备驱动程序接口
一般来说,实时迁移 DDI 指的是 WDDM 和 MCDM DDI 的一般概念,尤其是 GPU-P 虚拟化 DDI。
hAdapter 通常是指表示此驱动程序管理的特定设备的句柄令牌。 系统枚举了多个物理设备的系统可能会让一个驱动程序管理多个 hAdapter,因此 hAdapter 会本地化到特定设备。
vfIndex 标识引用的是哪个虚拟函数/vDEV。 它本地化到特定的虚拟设备。 它有时也被称为分区 ID。
DeviceLuid 还会本地化特定的虚拟设备,但仅限于使用虚拟设备管理 UMED 界面的语言。
在引用存储在设备上的内容(如 VRAM 储备)时,SegmentId 可识别特定的 VidMm 段曝光。
关于接口定义的说明
本文指的是动态调整大小的结构。 这些结构是通过动态大小的数组实现的,参考页描述如下:
size_t ArraySize;
ElementType Array[ArraySize];
其中,接口在结构的前面传递了一个数组的大小,然后当提供数组时,接口对象的解析就会遍历这个数组中的元素。 这些声明在 C/C++ 语言中无效,因为这些语言表达的是静态大小的片段。 首先读入静态大小的结构,然后在代码中进行动态解析。
设备启动和上限报告
DXGK_GPUPCAPS 中添加了以下功能:
- LiveMigration 上限表示驱动程序支持实时迁移功能(通常,本文中提到的新增 DDI 不包括 DxgkDdiSetVirtualGpuResources2)。
- ScatterMapReserve 上限表示驱动程序支持 DxgkDdiSetVirtualGpuResources2,该功能将在未来的版本中添加。
当 OS 通过 DXGKQAITYPE_GPUPCAPS 请求调用 DxgkDdiQueryAdapterInfo 时,KMD 必须填写这些上限。 在调用 DxgkDdiStartDevice 后以及适配器支持 GPU 分区时,OS 会在设备初始化过程中查询上限。
如果驱动程序返回 ScatterMapReserve 上限,则需要公开新增的 DXGKQAITYPE_SCATTER_RESERVE 类型和以下相关结构,以便 OS 可以查询驱动程序的散点储备功能:
- pInputData 的 DXGK_QUERYSCATTERRESERVEIN
- pOutputData 的 DXGK_QUERYSCATTERRESERVEOUT
散点分页支持
为了支持将非连续的脏页面传输到帧缓冲或从帧缓冲中传输出脏页面,该功能是首批使用非连续物理地址支持的 GPU-VA 映射的功能之一。 目前的分页接口不需要为这种支持而更新,因为分页表一直都支持这种可能性。 但是,任何对连续性做出假设的潜在实施细节都可能因这一变化而显露出来。 因此,了解 OS 的这一机制、它是如何执行虚拟分页接口的,并确保分页对这一变化的稳健性非常重要。
特别是,TransferVirtual 接口现在可以传递帧缓冲上未连续映射的 VA 范围。
实时迁移开始发送端
当系统启动迁移的实时组件时,需要调用添加的 的 DxgkDdiPrepareLiveMigration DDI。 此调用会通知驱动程序该时期已经开始,并允许驱动程序为迁移配置 VF 调度策略,该策略应分配部分空闲和迁移 VF 预算用于 PF 分页。
Dxgkrnl 然后调用 KMD 的 DxgkDdiSaveImmutableMigrationData DDI 来收集要在目标端还原的设备信息。
在系统收集并发送不可变数据和验证数据后,脏数据发送的主要迭代循环就会开始。
迭代保存/发送
如概述部分所述,迭代保存操作使用 DxgkDdiQueryDirtyBitData 在每次迭代开始时为 VF 的当前脏位平面拍摄快照,并使用标准 DXGK_OPERATION_VIRTUAL_TRANSFER 操作对报告的脏页进行分页。 如果此操作发生在设备上,而该设备的脏追踪功能报告称其性能影响不容忽视,则系统的迭代控制会首先启用脏追踪功能,然后在首次调用查询脏位平面之前传输整个帧缓冲。
对于虚拟传输,主要的更新行为是映射不是连续的 VA 到连续的 PA。 相反,在映射下可能存在互不相连的 PA 页面。 否则,该行为将与原始分页和脏位平面跟踪文档中描述的一样,而该功能并不会对此产生任何影响。
实时迁移结束发送端
在迁移结束时,系统需要收集所有设备和驱动程序状态,以完成重建状态和尚未转移的跟踪。 这些数据无法传输,因为它们不符合早期迁移数据的不变性要求,也不是 VRAM 脏内容。 Dxgkrnl 会调用添加的 DxgkDdiSaveMutableMigrationData DDI 来执行此操作。 此 DDI 的用法与 DxgkDdiSaveImmutableMigrationData 类似。
最终,当该 VF 不再需要迁移配置时,DxgkDdiEndLiveMigration 将被调用。 所有调度和状态都应恢复到非迁移配置。
实时迁移开始接收端
当接收端收到不可变数据时,系统会通过调用 DxgkDdiRestoreImmutableMigrationData 将其直接传递给 KMD。
只有当前暂停的 VF 才能调用此 DDI。
迭代还原/接收
散点分页会再次以迭代方式运行,但这次不需要调用检查与 VF 保留的帧缓冲区相关的脏位平面,因为目标上的脏位平面是由分页构建的。 分页的方向是相反的。 接收到的缓冲区中的内容被传输到 VRAM,而页面的位置由 VRAM 决定。
实时迁移结束接收端
一旦迁移即将结束,接收端系统就会调用驱动程序的 DxgkDdiRestoreMutableMigrationData 函数,还原最终的状态包。 此包应提供所有留待驱动程序转移的内容,以便恢复其状态和跟踪,以及恢复 VF 状态的其余部分。
只有当前暂停的 VF 才能调用此 DDI。
在调用后,系统会调用 KMD 的 DxgkDdiEndLiveMigration 函数,让目标机端知道要清理实时迁移周围的任何状态,包括恢复正常的 VF 调度。
与 UMED 通信
用户模式仿真 DLL (UMED) 接口通过 IGPUPMigration 接口进行了扩展,以便在实时迁移过程中保存和验证内容。
HRESULT SaveImmutableGpup(
[in] PLUID DeviceLuid,
[in,out] UINT64 * Length,
[in,out] BYTE * SaveBuffer
);
HRESULT RestoreImmutableGpup(
[in] PLUID DeviceLuid,
[in] UINT64 Length,
[in] BYTE * RestoreBuffer
);
在类似调用 KMD 的实时迁移准备过程中,UMED 有机会发送任何对 UMED 迁移准备有用的信息,或验证环境是否支持 UMED 级别的迁移。 它是 UMED 的可选接口,具有 UMED 的标准接口合约(线程和进程上下文、受限 OS 公开等)。 它的调用模式与 KMD DDI 相似,具有两阶段保存功能。 与其他保存/恢复 UMED 接口一样,这些调用中没有状态标志,因为这些标志应在设备及其 LUID 的整个生命周期内有效且保持不变。
UMED 的可变状态通过现有的“保存/还原”接口进行传输。 过去,GPU-P 驱动程序会阻止该接口的执行,但当 KMD 报告支持 LiveMigration 时,该接口就会被取消阻止。 将 UMED 标注函数与 KMD 功能绑定在一起是有意的。 实时迁移是系统实现这些设备虚拟化快速迁移的方式。 快速迁移(保存/还原)是实时迁移的一种特殊情况,在这种情况下不会进行主动迁移。 支持保存/还原的 UMED 仍需要有一个支持实时迁移 DDI 的 KMD。 同样,UMED 也必须了解 IGPUPMigration 接口,并评估在其设计中是否有必要在 KMD 进行实时迁移。
中断虚拟化
来宾中断管理的物理寻址必须虚拟化,以便在迁移过程中底层硬件发生变化时为 MSI-X 表访问提供正确服务。 UMED 必须拦截所有支持实时迁移的驱动程序的 MSI-X 中断表。 对“消息高位地址”和“消息地址”字段的任何读取或写入都需要映射到实际硬件值。 Dxgkrnl 维护虚拟化(或来宾)地址的映射,并在调用堆栈需要时执行替换。
OS 管理虚拟化/来宾物理地址的映射,表的读取或写入可能会将来宾物理地址与实际中断服务所需的主机物理地址进行映射。 这种通用路径不需要单独的 UMED 实现或内核转发,OS 截获表时也不会通知 UMED。 对 UMED 的唯一要求是,需要为表格的 BAR 页面设置设备的缓解措施。
但在内核中,Dxgkrnl 希望 KMD 为实际写入提供服务。 KMD 通过实现新增的 DxgkDdiWriteVirtualizedInterrupt 回调函数来实现这一功能。
由于 UMD 本地跟踪写入(以虚拟化/来宾转换的形式),所以不需要昂贵的内核跳转,因此也永远不需要读取。 此跟踪会随虚拟设备一起迁移。
DDI 同步和 IRQL 上下文
| DDI | 同步级别 | IRQL |
|---|---|---|
| DxgkDdiPrepareLiveMigration | 0 | PASSIVE |
| DxgkDdiEndLiveMigration | 0 | PASSIVE |
| DxgkDdiSaveImmutableMigrationData | 0 | PASSIVE |
| DxgkDdiSaveMutableMigrationData | 0 | PASSIVE |
| DxgkDdiRestoreImmutableMigrationData | 0 | PASSIVE |
| DxgkDdiRestoreMutableMigrationData | 0 | PASSIVE |
| DxgkDdiWriteVirtualizedInterrupt | 0 | PASSIVE |
| DxgkDdiSetVirtualGpuResources2 | 0 | PASSIVE |
| DxgkDdiSetVirtualFunctionPauseState | 0 | PASSIVE |
| IGPUPMigration::SaveImmutableGpup | 0 | PASSIVE |
| IGPUPMigration::RestoreImmutableGpup | 0 | PASSIVE |
VF 调度的重要考虑因素
PF 上的分页传输调度在很大程度上决定了传输效率。 PF 对设备分页引擎的访问越多,总线就越饱和,吞吐量就越高,传输性能就越好,特别是暂停传输。 在给定时间内捕获并发送的内容越多越好;并且至少要达到网络饱和状态。
调度的变化最好只影响分页引擎,而不影响其他设备资源,但并不是所有的 VF 调度设计都允许这样做。 调度至少需要:
- 只从正在迁移的 VF 或未分配的 VF 调度中提取预算。
- 不会降低计算机上任何其他虚拟化的性能。
请注意,这些条件在目标端更容易满足,因为 VF 暂停了整个传输,而且整个预算都可用。 在源端,需要平衡迁移需求和 VM 需求,最终实现暂停转移目标。