使用本文中的信息排查存储空间直通部署问题。
一般情况下,请从以下步骤开始:
- 使用 Windows Server Catalog 确认 SSD 的制造商和型号是否已通过 Windows Server 2016 和 Windows Server 2019 认证。 与供应商确认存储空间直通是否支持这些驱动器。
- 检查存储中是否存在任何有故障的驱动器。 使用存储管理软件检查驱动器的状态。 如果任何驱动器出现故障,请咨询供应商。
- 根据需要更新存储和驱动器固件。 确保所有节点上安装了最新的 Windows 更新。 可以从 Windows 10 和 Windows Server 2016 更新历史记录获取 Windows Server 2016 的最新更新。 从 Windows 10 和 Windows Server 2019 更新历史记录获取 Windows Server 2019 的最新更新。
- 更新网络适配器驱动程序和固件。
- 运行群集验证并查看“存储空间直通”部分。 确保你用于缓存的驱动器被正确报告,并且没有错误。
如果仍遇到问题,请查看本文中每个特定问题的故障排除信息。
虚拟磁盘资源处于“无冗余”状态
由于崩溃或电源故障,存储空间直通系统的节点意外重启。 然后,一个或多个虚拟磁盘可能无法联机,并且出现说明:“没有足够的冗余信息”。
| FriendlyName | ResiliencySettingName | OperationalStatus | HealthStatus | IsManualAttach | Size | PSComputerName |
|---|---|---|---|---|---|---|
| Disk4 | Mirror | OK | Healthy | True | 10 兆字节 | Node-01.conto... |
| Disk3 | Mirror | OK | Healthy | True | 10 兆字节 | Node-01.contoso. |
| Disk2 | Mirror | 无冗余 | Unhealthy | True | 10 兆字节 | Node-01.contoso. |
| Disk1 | Mirror | {无冗余,服务中} | Unhealthy | True | 10 兆字节 | Node-01.contoso. |
因此,在尝试将虚拟磁盘联机后,群集日志 (DiskRecoveryAction) 中记录了以下信息。
[Verbose] 00002904.00001040::YYYY/MM/DD-12:03:44.891 INFO [RES] Physical Disk <DiskName>: OnlineThread: SuGetSpace returned 0.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 WARN [RES] Physical Disk < DiskName>: Underlying virtual disk is in 'no redundancy' state; its volume(s) may fail to mount.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 ERR [RES] Physical Disk <DiskName>: Failing online due to virtual disk in 'no redundancy' state. If you would like to attempt to online the disk anyway, first set this resource's private property 'DiskRecoveryAction' to 1. We will try to bring the disk online for recovery, but even if successful, its volume(s) or CSV may be unavailable.
如果磁盘出现故障或系统无法访问虚拟磁盘上的数据,则会出现“无冗余操作状态”。 如果在节点维护期间在节点上进行重启,则可能会发生此问题。
要解决此问题,请执行以下步骤:
从 CSV 中删除受影响的虚拟磁盘。 这会将它们放入群集中的可用存储组,并开始显示
Physical Disk资源类型。Remove-ClusterSharedVolume -Name "CSV Name"在拥有可用存储组的节点上,对处于“无冗余”状态的每个磁盘运行以下命令。 要确定可用存储组位于哪个节点上,可运行此命令:
Get-ClusterGroup设置磁盘恢复操作,然后启动磁盘。
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 1 Start-ClusterResource -Name "Physical Disk Resource Name"修复应会自动开始。 等待修复完成。 它可能会进入暂停状态,然后重新启动。 要监视进度,请执行以下操作:
- 运行
Get-StorageJob以监视修复状态并查看修复何时完成。 - 运行
Get-VirtualDisk并验证空间返回的“运行状态”是否为“正常”。
- 运行
修复完成并且虚拟磁盘进入正常状态后,改回虚拟磁盘参数。
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 0使磁盘脱机,然后再次联机,使
DiskRecoveryAction生效:Stop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"将受影响的虚拟磁盘添加回 CSV。
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"
DiskRecoveryAction 是一个替代开关,允许你在读写模式下附加空间卷,而无需进行任何检查。 使用该属性可以诊断卷未联机的原因。 它与维护模式相似,但你可以对处于故障状态的资源调用它。 它还使你能够访问数据,以便可以复制它。 此访问在无冗余情况下很有用。
DiskRecoveryAction 属性是在 2018 年 2 月 22 日的更新 KB 4077525 中添加的。
群集中的分离状态
运行 Get-VirtualDisk cmdlet 时,会拆离一个或多个存储空间直通虚拟磁盘的 OperationalStatus。 但是,Get-PhysicalDisk cmdlet 报告的“运行状态”指示所有物理磁盘都处于“正常”状态。
此示例显示 Get-VirtualDisk cmdlet 的输出。
| FriendlyName | ResiliencySettingName | OperationalStatus | HealthStatus | IsManualAttach | Size | PSComputerName |
|---|---|---|---|---|---|---|
| Disk4 | Mirror | OK | Healthy | True | 10 兆字节 | Node-01.contoso. |
| Disk3 | Mirror | OK | Healthy | True | 10 兆字节 | Node-01.contoso. |
| Disk2 | Mirror | Detached | Unknown | True | 10 兆字节 | Node-01.contoso. |
| Disk1 | Mirror | Detached | Unknown | True | 10 兆字节 | Node-01.contoso. |
此外,可能会在节点上记录以下事件:
Log Name: Microsoft-Windows-StorageSpaces-Driver/Operational
Source: Microsoft-Windows-StorageSpaces-Driver
Event ID: 311
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: Virtual disk {GUID} requires a data integrity scan.
Data on the disk is out-of-sync and a data integrity scan is required.
To start the scan, run this command:
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTask
Once you have resolved that condition, you can online the disk by using these commands in PowerShell:
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsReadOnly $false
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsOffline $false
------------------------------------------------------------
Log Name: System
Source: Microsoft-Windows-ReFS
Event ID: 134
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: The file system was unable to write metadata to the media backing volume <VolumeId>. A write failed with status "A device which does not exist was specified." ReFS will take the volume offline. It might be mounted again automatically.
------------------------------------------------------------
Log Name: Microsoft-Windows-ReFS/Operational
Source: Microsoft-Windows-ReFS
Event ID: 5
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: ReFS failed to mount the volume.
Context: 0xffffbb89f53f4180
Error: A device which does not exist was specified.
Volume GUID:{00000000-0000-0000-0000-000000000000}
DeviceName:
Volume Name:
如果脏区域跟踪 (DRT) 日志已满,则会发生 Detached Operational Status。 存储空间对镜像空间使用脏区域跟踪 (DRT),以确保在发生电力故障时,任何正在进行的元数据更新都会被记录下来。 记录的更新可确保存储空间可以恢复或撤消操作。 在电力恢复且系统重新上线后,它们会将存储空间返回到灵活且一致的状态。 如果 DRT 日志已满,则在同步和刷新 DRT 元数据之前无法使虚拟磁盘联机。 此过程需要运行完整扫描,这可能需要几个小时才能完成。
要解决此问题,请执行以下步骤:
从 CSV 中删除受影响的虚拟磁盘。
Remove-ClusterSharedVolume -Name "CSV Name"在每个未联机的磁盘上运行这些命令。
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 7 Start-ClusterResource -Name "Physical Disk Resource Name"在分离卷处于联机状态的每个节点上运行以下命令。
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTask在已拆离卷处于联机状态的所有节点上启动此任务。 修复应会自动开始。 等待修复完成。 它可能会进入暂停状态,然后重新启动。 要监视进度,请执行以下操作:
- 运行
Get-StorageJob以监视修复状态并查看修复何时完成。 - 运行
Get-VirtualDisk并验证空间返回的“运行状态”是否为“正常”。“用于故障恢复的数据完整性扫描”是一项不会显示为存储作业的任务,并且没有进度指示器。 如果该任务显示为正在运行,那么它就正在运行。 完成后,它会显示为已完成。
此外,还可以使用此 cmdlet 查看正在运行的计划任务的状态:
Get-ScheduledTask | ? State -eq running
- 运行
“用于故障恢复的数据完整性扫描”完成后,修复就完成了,虚拟磁盘会正常运行。 将虚拟磁盘参数改回去。
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 0使磁盘脱机,然后再次联机,使
DiskRecoveryAction生效:Stop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"将受影响的虚拟磁盘添加回 CSV。
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"使用
DiskRunChkdsk value 7附加空间卷并将分区设置为只读模式。 这样一来,空间便可以通过触发修复来进行自我发现和自我修复。 修复将在装载后自动运行。 它还使你能够访问数据以复制它。 对于某些故障状态(例如 DRT 日志已满),需要运行计划任务“用于故障恢复的数据完整性扫描”。
使用“用于故障恢复的数据完整性扫描”任务来同步和清除已填满的脏区域跟踪 (DRT) 日志。 此任务可能需要几个小时才能完成。 “用于故障恢复的数据完整性扫描”是一项不会显示为存储作业的任务,并且没有进度指示器。 如果该任务显示为正在运行,那么它就正在运行。 完成后,它会显示为已完成。 如果在此任务运行时将它取消或重启节点,此任务则需要从头开始运行。
有关详细信息,请参阅排查存储空间直通运行状况和操作状态问题。
带有 STATUS_IO_TIMEOUT c00000b5 的事件 5120
Important
对于 Windows Server 2016:为了减少在应用修复更新时遇到这些症状的可能性,当节点目前安装了从 2018 年 5 月 8 日到 2018 年 10 月 9 日发布的 Windows Server 2016 累积更新时,建议使用“存储维护模式”过程来安装 Windows Server 2016 的 2018 年 10 月 18 日累积更新或更高版本。
在安装了 2018 年 5 月 8 日 KB 4103723 到 2018 年 10 月 9 日 KB 4462917 累积更新的 Windows Server 2016 上重启某个节点后,你可能会收到带有 STATUS_IO_TIMEOUT c00000b5 的事件 5120。
重启节点时,事件 5120 会记录在系统事件日志中,并包含以下某个错误代码:
Event Source: Microsoft-Windows-FailoverClustering
Event ID: 5120
Description: Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_IO_TIMEOUT(c00000b5)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_CONNECTION_DISCONNECTED(c000020c)'. All I/O will temporarily be queued until a path to the volume is reestablished.
记录事件 5120 时,会生成实时转储以收集调试信息,这些信息可能导致其他症状或影响性能。 实时转储生成时,会导致短暂的暂停。 该暂停使内存快照能够写入转储文件。 内存量特别大且具有压力的系统可能会导致节点放弃群集成员身份,并导致记录下面的事件 1135。
Event source: Microsoft-Windows-FailoverClustering
Event ID: 1135
Description: Cluster node 'NODENAME'was removed from the active failover cluster membership. The Cluster service on this node might have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
2018 年 5 月 8 日在 Windows Server 2016 中引入了一项更改,它是一项为存储空间直通群集内 SMB 网络会话添加 SMB 可复原句柄的累积更新。 此项更新旨在提高发生暂时性网络故障后的复原能力,并改进 RoCE 处理网络拥塞状况的方式。 这些改进也无意中增加了 SMB 连接尝试重新连接时的超时,以及在重启节点时等待的超时。 这些问题可能会影响承受压力的系统。 在计划外停机期间,当系统等待连接超时时,还观察到出现了长达 60 秒的 IO 暂停。要解决此问题,请安装 Windows Server 2016 的 2018 年 10 月 18 日累积更新或更高版本。
Note
此项更新使 CSV 超时与 SMB 连接超时保持一致,从而解决了该问题。 它不会实现更改来禁用“解决方法”部分中提到的实时转储生成。
关闭过程流
运行 Get-VirtualDisk cmdlet,并确保 HealthStatus 值为 Healthy。
通过运行此 cmdlet 来清空节点:
Suspend-ClusterNode -Drain运行此 cmdlet,在存储维护模式中将磁盘放置在该节点上:
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Enable-StorageMaintenanceMode运行
Get-PhysicalDiskcmdlet,并确保OperationalStatus值为In Maintenance模式。运行
Restart-Computercmdlet 以重启节点。节点重启后,运行此 cmdlet 以从存储维护模式中删除该节点上的磁盘:
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Disable-StorageMaintenanceMode通过运行此 cmdlet 恢复节点:
Resume-ClusterNode通过运行此 cmdlet 检查重新同步作业的状态:
Get-StorageJob
禁用实时转储
要缓解实时转储生成对内存量巨大且承受压力的系统的影响,可以禁用实时转储生成。 下面提供了三个选项:
Caution
此过程可能会阻止收集 Microsoft 支持部门在调查此问题时所需的诊断信息。 支持代理可能会要求你根据特定的故障排除方案重新启用实时转储生成。
禁用所有转储
要完全禁用所有转储,包括系统范围的实时转储,请执行以下步骤。 对于此方案,请使用此过程:
- 创建以下注册表项:HKLM\System\CurrentControlSet\Control\CrashControl\ForceDumpsDisabled
- 在新的 ForceDumpsDisabled 键下,创建一个REG_DWORD属性作为 GuardedHost,然后将其值设置为0x10000000。
- 将新注册表项应用于每个群集节点。
Note
必须重启计算机才能使注册表更改生效。
设置此注册表项后,实时转储创建将失败并生成 STATUS_NOT_SUPPORTED 错误。
仅允许一个实时转储
默认情况下,Windows 错误报告仅允许每 7 天为每种报告类型创建 1 个 LiveDump,每 5 天为每台计算机创建 1 个 LiveDump。 你可以更改此设置,方法是将以下注册表项设置为永远只允许在计算机上创建一个 LiveDump。
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v SystemThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v ComponentThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
Note
要使更改生效,必须重新启动计算机。
禁用群集生成
要禁用群集生成实时转储(例如在记录事件 5120 时),请运行此 cmdlet:
(Get-Cluster).DumpPolicy = ((Get-Cluster).DumpPolicy -Band 0xFFFFFFFFFFFFFFFE)
此 cmdlet 对所有群集节点立即生效,而无需重启计算机。
IO 性能缓慢
如果你发现 IO 性能缓慢,请检查存储空间直通配置中是否启用了缓存。
可通过两种方式进行检查:
使用群集日志。 使用所选的文本编辑器打开群集日志,然后搜索“[=== SBL Disks ===]”。 可以看到日志生成的节点上的磁盘列表。
缓存启用的磁盘示例:请注意,状态为
CacheDiskStateInitializedAndBound且此处存在 GUID。[=== SBL Disks ===] {26e2e40f-a243-1196-49e3-8522f987df76},3,false,true,1,48,{1ff348f1-d10d-7a1a-d781-4734f4440481},CacheDiskStateInitializedAndBound,1,8087,54,false,false,HGST,HUH721010AL4200,7PG3N2ER,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],缓存未启用:可以看到此处不存在 GUID 且状态为
CacheDiskStateNonHybrid。[=== SBL Disks ===] {426f7f04-e975-fc9d-28fd-72a32f811b7d},12,false,true,1,24,{00000000-0000-0000-0000-000000000000},CacheDiskStateNonHybrid,0,0,0,false,false,HGST,HUH721010AL4200,7PGXXG6C,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],缓存未启用:当所有磁盘的类型相同时,默认不启用缓存。 可以看到这里不存在 GUID 且状态为
CacheDiskStateIneligibleDataPartition。{d543f90c-798b-d2fe-7f0a-cb226c77eeed},10,false,false,1,20,{00000000-0000-0000-0000-000000000000},CacheDiskStateIneligibleDataPartition,0,0,0,false,false,NVMe,INTEL SSDPE7KX02,PHLF7330004V2P0LGN,0170,{79b4d631-976f-4c94-a783-df950389fd38},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],使用 SDDCDiagnosticInfo 中的 Get-PhysicalDisk.xml。
- 使用“$d = Import-Clixml GetPhysicalDisk.XML”打开 XML 文件。
- 运行
ipmo storage。 - 运行
$d。 请注意,使用情况是自动选择,而不是日记。
你应该会看到与它类似的输出:
FriendlyName SerialNumber MediaType CanPool OperationalStatus HealthStatus Usage Size NVMe INTEL SSDPE7KX02 PHLF733000372P0LGN SSD False OK Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7504008J2P0LGN SSD False OK Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7504005F2P0LGN SSD False OK Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7504002A2P0LGN SSD False OK Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7504004T2P0LGN SSD False OK Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7504002E2P0LGN SSD False OK Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7330002Z2P0LGN SSD False OK Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF733000272P0LGN SSD False OK Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7330001J2P0LGN SSD False OK Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF733000302P0LGN SSD False OK Healthy Auto-Select 1.82 TB NVMe INTEL SSDPE7KX02 PHLF7330004D2P0LGN SSD False OK Healthy Auto-Select 1.82 TB
如何销毁现有群集以便再次使用相同的磁盘
在存储空间直通群集中,禁用存储空间直通并使用 清理驱动器中所述的清理过程。 群集存储池仍处于脱机状态,运行状况服务已从群集中删除。
下一步是删除虚构存储池:
Get-ClusterResource -Name "Cluster Pool 1" | Remove-ClusterResource
现在,如果在任一节点上运行 Get-PhysicalDisk ,则会看到池中的所有磁盘。 例如,某实验室中有一个 4 节点群集,包含 4 个 SAS 磁盘,为每个节点提供了 100 GB。 在这种情况下,禁用存储空间直通后,会删除 SBL(存储总线层),但离开筛选器(如果运行 Get-PhysicalDisk),则它应报告 4 个磁盘(不包括本地 OS 磁盘)。 相反,它报告了16。 对于群集中的所有节点,此行为都是一样的。 运行 Get-Disk 命令时,会看到本地附加的磁盘编号为 0、1、2 等,如此示例输出所示:
| Number | 友好名称 | 序列号 | HealthStatus | OperationalStatus | 总大小 | 分区样式 |
|---|---|---|---|---|---|---|
| 0 | Msft Virtual | Healthy | Online | 127 GB | GPT | |
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| 1 | Msft Virtual | Healthy | Offline | 100 GB | RAW | |
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| 2 | Msft Virtual | Healthy | Offline | 100 GB | RAW | |
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| 4 | Msft Virtual | Healthy | Offline | 100 GB | RAW | |
| 3 | Msft Virtual | Healthy | Offline | 100 GB | RAW | |
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW |
使用 Enable-ClusterS2D 创建存储空间直通群集时出现“不受支持的媒体类型”错误消息
运行 Enable-ClusterS2D cmdlet 时,可能会看到类似的错误:
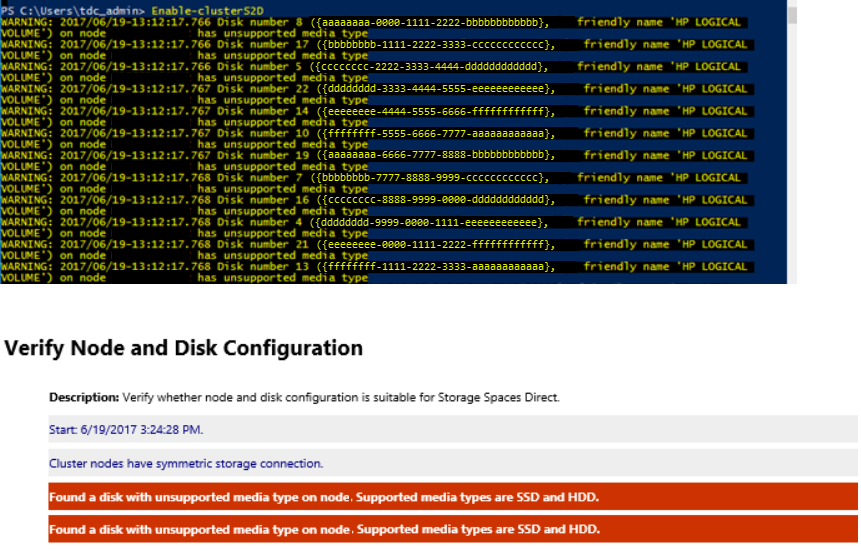
要解决此问题,请确保以 HBA 模式配置 HBA 适配器。 不应以 RAID 模式配置 HBA。
Enable-ClusterStorageSpacesDirect 在“正在等待显示 SBL 磁盘”阶段或进度为 27% 时挂起
你将在验证报告中看到以下信息:
连接到节点 <identifier> 的磁盘 <nodename> 返回了 SCSI 端口关联,并且找不到相应的机箱设备。 硬件与存储空间直通 (S2D) 不兼容。 请联系硬件供应商,验证对 SCSI 机箱服务 (SES) 的支持。
问题与磁盘和 HBA 卡之间的 HPE SAS 扩展卡有关。 SAS 扩展卡会在连接到该扩展卡的第一个驱动器与该扩展卡本身之间创建重复 ID。 此问题已在 HPE 智能阵列控制器 SAS 扩展卡固件:4.02 中得到解决。
Intel SSD DC P4600 系列有一个非唯一的 NGUID
你可能会遇到以下问题:对于多个命名空间,Intel SSD DC P4600 系列设备似乎报告类似的 16 字节 NGUID,例如此示例中的 0100000001000000E4D25C000014E214 或 0100000001000000E4D25C0000EEE214。
| UniqueId | DeviceId | MediaType | BusType | SerialNumber | Size | CanPool | FriendlyName | OperationalStatus |
|---|---|---|---|---|---|---|---|---|
| 5000CCA251D12E30 | 0 | HDD | SAS | 7PKR197G | 10000831348736 | False | HGST | HUH721010AL4200 |
| eui.0100000001000000E4D25C000014E214 | 4 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C000014E214 | 5 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C0000EEE214 | 6 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C0000EEE214 | 7 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | True | INTEL | SSDPE2KE016T7 |
要解决此问题,请将 Intel 驱动器上的固件更新到最新版本。 2018 年 5 月发布的固件版本 QDV101B1 可以解决此问题。
Intel SSD 数据中心工具 2018 年 5 月版包含适用于 Intel SSD DC P4600 系列的固件更新 QDV101B1。
物理磁盘的运行状态和操作状态
在 Windows Server 2016 存储空间直通群集中,你可能会看到一个或多个物理磁盘的 HealthStatus 为 正常,而 OperationalStatus 正在从池中删除,正常。
“正在从池中删除”状态是调用 Remove-PhysicalDisk 时设置的意向,但此状态存储在运行状况中以维护状态,并使用户能够在删除操作失败时进行恢复。 可使用以下某个方法手动将操作状态更改为“正常”:
- 从池中删除物理磁盘,然后将其添加回来。
- Import-Module Clear-PhysicalDiskHealthData.ps1。
- 运行 Clear-PhysicalDiskHealthData.ps1 脚本 以清除意向。 此脚本可作为 .txt 文件下载。 必须先将其保存为 ps1 文件,然后才能运行它。
以下示例演示如何运行该脚本:
使用
SerialNumber参数指定要设置为“正常”的磁盘。 可以从WMI MSFT_PhysicalDisk或Get-PhysicalDisk中获取序列号。 此示例使用零表示序列号。Clear-PhysicalDiskHealthData -Intent -Policy -SerialNumber 000000000000000 -Verbose -Force使用
UniqueId参数指定磁盘,还是通过WMI MSFT_PhysicalDisk或Get-PhysicalDisk。Clear-PhysicalDiskHealthData -Intent -Policy -UniqueId 00000000000000000 -Verbose -Force
文件复制速度缓慢
使用文件资源管理器将大型 VHD 复制到虚拟磁盘时,你可能会看到文件复制所需的时间比预期长。
不建议使用文件资源管理器、Robocopy 或 Xcopy 将大型 VHD 复制到虚拟磁盘。 这会导致性能低于预期。 复制过程不会经过存储堆栈下面的存储空间直通堆栈,而是类似于本地复制过程。
如果你要测试存储空间直通的性能,我们建议使用 VMFleet 和 Diskspd 对服务器进行负载和压力测试,以获得基线并设置预期的存储空间直通性能。
在节点重启期间,其余节点上预期会发生的事件
可以放心地忽略这些事件:
Event ID 205: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Event ID 203: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
如果运行的是 Azure VM,可以忽略此事件:事件 ID 32:驱动程序检测到设备 \Device\Harddisk5\DR5 已启用写入缓存。可能会发生数据损坏。
对于使用 Intel P3x00 NVMe 设备的部署,出现性能缓慢或“通信中断”、“IO 错误”、“已分离”或“无冗余”错误
我们发现了一个严重问题,它会影响某些使用基于 Intel P3x00 系列 NVM Express (NVMe) 设备且固件版本低于“维护版本 8”的硬件的存储空间直通用户。
Note
个别 OEM 的设备可能基于带有独特固件版本字符串的 Intel P3x00 系列 NVMe 设备。 有关最新固件版本的详细信息,请与 OEM 联系。
如果你在部署中使用基于 Intel P3x00 系列 NVMe 设备的硬件,我们建议立即应用最新可用固件(至少为维护版本 8)。