上一个主题(资源管理系统如何匹配和选择资源)对限定符匹配进行了总体概括。 本主题主要对语言标记匹配进行详细介绍。
介绍
使用语言标记限定符的资源根据应用运行时语言列表进行比较和评分。 有关不同语言列表的定义,请参阅了解用户配置文件语言和应用清单语言。 优先匹配列表中的第一种语言,然后是第二语言,也适用于其他区域变体。 例如,如果应用运行时语言为 en-US,则选择 en-GB 资源而不是 fr-CA 资源。 仅在没有 en 形式的资源时选择 fr-CA 的资源(请注意,在这种情况下,无法将应用的默认语言设置为任意形式的en)。
评分机制使用 BCP-47 子标记注册表和其他数据源中包含的数据。 该机制允许对不同匹配质量进行评分,并且当有多个候选项可用时,会选择具有最佳匹配分数的候选项。
因此,可以用泛型术语标记语言内容,但仍可以按需指定特定内容。 例如,你的应用可能有许多英语字符串,这些字符串适用于美国、英国和其他区域。 将这些字符串标记为“en”(英语)可节省空间和本地化开销。 需要区分时(例如,在包含“color/colour”字符串中),美国和英国版本可以分别使用语言和区域子标记(如“en-US”和“en-GB”)进行标记。
语言标记
使用规范化格式良好的 BCP-47 语言标记标识语言。 子标记组件在 BCP-47 子标记注册表中定义。 BCP-47 语言标记的正常结构由以下一个或多个子标记元素组成。
- 语言子标记(必需)。
- 脚本子标记(可以使用子标记注册表中指定的默认值推断)。
- 区域子标记(可选)。
- 变体子标记(可选)。
可能存在其他子标记元素,但它们对语言匹配影响较小。 使用通配符 (“”) 时,不定义语言范围,例如“en-”。
匹配两种语言
Windows 对两种语言的比较,通常是在更长的流程中完成的。 它可能处于评估多种语言的上下文中,例如当 Windows 生成应用程序语言列表时(请参阅了解用户配置文件语言和应用清单语言)。 Windows 通过将用户首选项中的多个语言与应用清单中指定的语言匹配来执行此操作。 比较还可能发生在为某个资源评估语言和其他限定符时。 例如,当 Windows 将某个文件资源解析为资源上下文时,会将用户的主页位置或设备的当前比例或 dpi 作为语言外的其他因素纳入资源选择中。
比较两个语言标记时,Windows 将根据匹配的接近程度进行评分。
| 匹配 | 分数 | 示例 |
|---|---|---|
| 完全匹配 | 最高 | en-AU : en-AU |
| 变体匹配(语言、脚本、区域、变体) | en-AU-variant1 : en-AU-variant1-t-ja | |
| 区域匹配(语言、脚本、区域) | en-AU : en-AU-variant1 | |
| 部分匹配(语言、脚本) | ||
| - 宏区域匹配 | en-AU : en-053 | |
| - 中性区域匹配 | en-AU : en | |
| - 正交相关性匹配(有限支持) | en-AU : en-GB | |
| - 首选区域匹配 | en-AU : en-US | |
| - 任何区域匹配 | en-AU : en-CA | |
| 不确定的语言(任何语言匹配) | en-AU : und | |
| 不匹配(脚本不匹配或主要语言标记不匹配) | 最低 | en-AU : fr-FR |
完全匹配
标记完全相等(所有子标记元素匹配)。 可以从变体或区域匹配将比较提升为此匹配类型。 例如,en-US 匹配 en-US。
变体匹配
标记在语言、脚本、区域和变体子标记方面匹配,但在其他方面有所不同。
区域匹配
标记在语言、脚本、区域和变体子标记方面匹配,但在其他方面有所不同。 例如,de-DE-1996 匹配 de-DE,en-US-x-Pirate 匹配 en-US。
部分匹配
标记在语言和脚本子标记方面匹配,但在区域或其他一些子标记方面有所不同。 例如,en-US 与 en 匹配,或 en-US 与 en-* 匹配。
宏区域匹配
标记在语言和脚本子标记方面匹配;两个标记都有区域子标记,其中一个标记代表的宏区域包含了另一个标记代表的区域。 宏区域子标记始终为数字,派生自联合国统计司 M.49 国家/地区和地区代码。 有关包含关系的详细信息,请参阅 宏观地理(大陆)区域、地理子区域以及选定经济和其他分组的组成。
注意,BCP-47 不支持联合国“经济分组”或“其他分组”的代码。
注意,带有宏区域子标记“001”的标记等效于中性区域标记。 例如,“es-001”和“es”为同义词。
中性区域匹配
标记在语言和脚本子标记方面匹配,其中一个标记具有区域标记。 父匹配优先于其他部分匹配项。
正交相关性匹配
标记在语言和脚本子标记方面匹配,在区域子标记方面具有正交相关性。 相关性依赖于 Windows 维护的数据,这些数据定义了特定语言的相关区域,例如“en-IE”和“en-GB”。
首选区域匹配
标记在语言和脚本子标记方面匹配,其中一个区域子标记是语言的默认区域子标记。 例如,“fr-FR”是“fr”子标记的默认区域。 因此,对于 fr-BE,fr-FR 是 比 fr-CA 更好的匹配项。 这依赖于 Windows 维护的数据,这些数据为每种语言定义了 Windows 所在的默认区域。
同级匹配
标记在语言和脚本子标记方面匹配,两者都具有区域子标记,但两者之间没有其他定义的关系。 在多个同级匹配事件中,如果没有更高的匹配项,那么以最后枚举的匹配为准。
不确定的语言
资源被标记为“und”,说明它不匹配任何语言。 此标记还可用于脚本标记,以根据脚本筛选匹配项。 例如,“und-Latn”将匹配所有使用拉丁语脚本的语言标记。 有关详细信息,请参阅下文。
脚本不匹配
当标记仅在主语言标记方面匹配,在脚本方面不匹配时,将被判定为不匹配,并且评分低于有效匹配级别。
无匹配
不匹配的主要语言子标记评分低于有效匹配级别。 例如,zh-Hant 与 zh-Hans 不匹配。
示例
用户语言“zh-Hans-CN”(简体中文(中国))按照以下优先级顺序匹配资源。 X 表示没有匹配项。
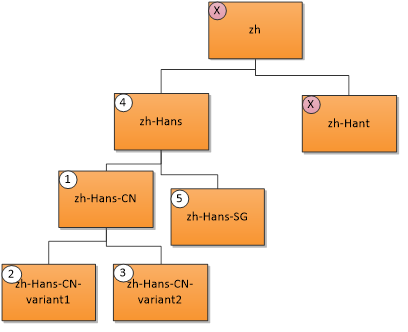
- 完全匹配;2。 &3。 区域匹配;4。 父匹配;5。 同级匹配。
当语言子标记包含 BCP-47 子标记注册表定义的 Suppress-Script 值时,会发生相应的匹配,并采用禁用脚本代码值。 例如,en-Latn-US 匹配 en-US。 在下一个示例中,用户语言为“en-AU”(英语(澳大利亚))。
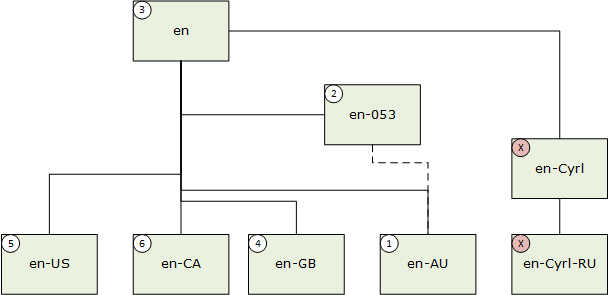
- 完全匹配;2。 宏区域匹配;3。 中性区域匹配;4。 正交相关性匹配;5。 首选区域匹配;6。 同级匹配。
将语言与语言列表匹配
有时,配对发生在单语言与一系列语言匹配的更长过程中。 例如,基于单个语言的资源可能匹配应用语言列表。 匹配的分数按列表中第一匹配语言的位置加权。 语言在列表中越靠后,分数越低。
当语言列表包含两个或多个区域变体,且都具有相同语言和脚本子标记时,第一个语言标记只会在变体和区域方面完全匹配时获得评分。 部分匹配评分将顺延到最后一个区域变体。 这能让用户精细控制其语言列表的匹配行为。 这种匹配行为可能会在列表中第三项与第一项在语言和脚本方面匹配时,允许第二项完全匹配优先于第一项部分匹配。 下面是一个示例。
- 语言列表(顺序):“pt-PT”(葡萄牙语(葡萄牙))、“en-US”(英语(美国))、“pt-BR”(葡萄牙语(巴西))。
- 资源:“en-US”、“pt-BR”。
- 分数较高的资源:“en-US”。
- 说明:从“pt-PT”开始比较,但未找到完全匹配项。 由于用户语言列表中存在“pt-BR”,部分匹配顺延到比较“pt-BR”时。 下一个语言比较是“en-US”,结果完全匹配。 因此,获胜的资源是“en-US”。
OR
- 语言列表(按顺序):“es-MX”(西班牙语(墨西哥))、“es-HO”(西班牙语(洪都拉斯))。
- 资源:“en-ES”、“es-HO”。
- 分数较高的资源:“es-HO”。
不确定的语言(“und”)
语言标记“und”可用于在缺少更好匹配的情况下指定匹配任何语言的资源。 可以将其视为类似于 BCP-47 语言范围“”或“-<脚本>”。 下面是一个示例。
- 语言列表:“en-US”、“zh-Hans-CN”。
- 资源:"zh-Hans-CN", "und"。
- 分数较高的资源:“und”。
- 说明:从“en-US”开始比较,但找不到基于“en”(部分或更好的)匹配项。 由于带有“und”标记的资源存在,因此匹配算法使用该资源。
标记“und”允许多种语言共享单个资源,并允许将单个语言视为例外。 例如:
- 语言列表:“zh-Hans-CN”、“en-US”。
- 资源:"zh-Hans-CN", "und"。
- 得分较高的资源:“zh-Hans-CN”。
- 说明:比较查找第一项的完全匹配项,因此不会为标记为“und”的资源检查。
可以将“und”与脚本标记配合使用,以按脚本筛选资源。 例如:
- 语言列表:“ru”。
- 资源:“und-Latn”、“und-Cyrl”、“und-Arab”。
- 分数较高的资源:“und-Cyrl”。
- 说明:比较后找不到“ru”(部分或更好)的匹配项,因此与语言标记“und”匹配。 与语言标记“ru”资源关联的禁止脚本值“Cyrl”匹配资源“und-Cyrl”。
正交区域相关性
如果匹配具有区域子标记差异的两个语言互相匹配,特定区域对之间的相关性可能高于它们与其他区域的相关性。 唯一受支持的相关组适用于英语(“en”)。 区域子标记“PH”(菲律宾)和“LR”(利比里亚)具有与“美国”区域子标记的正交关系。 所有其他区域子标记都与“GB”(英国)区域子标记相关。 因此,当“en-US”和“en-GB”资源都可用时,“en-HK”(英语(香港特别行政区)的语言列表将获得比“en-US”资源更高的分数。
处理具有许多区域变体的语言
对于某些语言,不同区域均有庞大的语言使用群体,不同区域使用该语言的不同变体,诸如英语、法语和西班牙语等语言就在多语言应用最常支持的语言之列。 区域差异可以为正交关系(例如,“color”与“colour”),或词汇等方言差异(例如,“truck”与“lorry”)。
这些具有重要区域变体的语言在创建全球范围适用的应用时面临一些挑战:“应支持多少个不同的区域变体?”“具体是哪些?”“为应用管理这些区域变体资产最经济高效的方法是什么?”对所有这些问题的解答超出了本主题的范畴。 但是,Windows 中的语言匹配机制提供了有助于处理区域变体的功能。
应用通常仅给定语言的单个变体。 假设某个应用只有一种类型的英语资源,对所有区域的英语使用者通用。 在这种情况下,应该使用不包含任何区域子标记的标记“en”。 但应用可能以前曾使用过包含区域子标记的标记,例如“en-US”。 这种情况通用适用该机制:该应用只使用一种类型的英语,Windows 处理匹配一个区域变体标记的资源,并采用适当的方式将不同区域变体与用户语言首选项匹配。
但是,如果支持两个或多个区域类型语言,则“en”与“en-US”等差异可能会对用户体验产生重大影响,因此应慎重考虑要使用的区域子标记。
假设你想要为加拿大和欧洲法语中使用的法语提供单独的法语本地化。 对于加拿大法语,可以使用“fr-CA”。 对于来自欧洲法语使用者,本地化将使用法语(法国),因此“fr-FR”是可用的。 但是,如果某个用户来自比利时,其语言首选项为“fr-BE”,他们将看到哪种语言? “FR”和“CA”都与区域“BE”不同,说明两者与“任何区域”匹配。 然而,法国恰好是法国的首选地区,因此“fr-FR”将被视为在这种情况下的最佳匹配项。
假设你首先将应用本地化为一种法语,使用法语(法国)字符串,但只笼统称为“fr”,然后你想要添加对加拿大法语的支持。 此时你可能只需要为加拿大法语重新翻译某些资源。 你可以继续使用所有原始资产,并保持“fr”名称,只需使用“fr-CA”添加一小组新资产即可。 如果用户语言首选项为“fr-CA”,则“fr-CA”资产的匹配分数将高于“fr”资产。 但是,如果用户语言首选项适用于任何其他类型法语,则区域中性资产“fr”匹配度将高于“fr-CA”资产。
另一个示例是,假设你想要为来自西班牙和拉丁美洲的西班牙语使用者提供单独的西班牙语本地化。 假设拉丁美洲的翻译由墨西哥的供应商提供。 是否应将“es-ES”(西班牙)和“es-MX”(墨西哥)用于两组资源? 这样做可能会给来自阿根廷或哥伦比亚等其他拉丁美洲地区的西班牙语使用者带来问题,因为他们看到的会是“es-ES”资源。 在这种情况下更好的选择是:使用宏区域子标记“es-419”,表示资产由来自拉丁美洲任何地区或加勒比的用户使用。
如果要支持多个区域类型语言,则区域中性语言标记和宏区域子标记可能非常有效。 为了尽量减少需要的单独资产数量,可以采用适用性最广泛的方式限定某个资产。 然后根据需要,利用具体的变体对补广泛适用资产进行补充。 具有中性区域语言限定符的资产将广泛用于各区域用户,除非用户应用了更具区域性的区域限定符。 例如,“en”资产可与澳大利亚英语用户匹配,但“en-053”(澳大利亚或新西兰使用的英语)的资产对用户来说是更好的匹配项,而“en-AU”的资产将是最佳匹配项。
英语需要特殊考虑。 如果应用对两种类型的英语进行本地化,这两种类型可能是美国英语和英国(或“国际”)英语。 如上所述,美国以外的某些区域遵循美国拼写约定,Windows 语言匹配会考虑到这一点。 在此场景中,不建议对其中一个变体使用中性区域标记“en”;请改用“en-GB”和“en-US”。 (如果给定资源不需要单独的变体,则可以使用“en”。)如果将“en-GB”或“en-US”替换为“en”,将干扰 Windows 提供的正交区域相关性。 如果使用了第三种英语本地化,则在需要时对其他变体使用特定或宏区域子标记(例如,“en-CA”、“en-AU”或“en-053”),同时继续使用“en-GB”和“en-US”。