将语音识别和文本转语音(也称为 TTS 或语音合成)直接集成到应用的用户体验中。
语音识别 语音识别将用户说出的字词转换为表单输入的文本、文本听写、指定作或命令以及完成任务。 它支持用于自由文本听写和 Web 搜索的预定义语法,以及使用语音识别语法规范 (SRGS) 版本 1.0 创作的自定义语法。
语音合成/Text to Speech(TTS) TTS 是使用语音合成引擎(声音)将文本字符串转换为口语。 输入字符串可以是基本文本、未经修饰的文本,也可以是更复杂的语音合成标记语言(SSML)。 SSML 提供了一种标准方法来控制语音输出的特征,例如发音、音量、音调、速率或速度以及强调。
语音交互设计
在深思熟虑地设计和实现语音时,它可以是用户与Windows应用程序交互的有效、可访问和自然的方式,补充甚至替换基于鼠标、键盘、控制器或触摸的传统交互体验。
这些指南和建议介绍了如何最好地将语音识别和 TTS 集成到应用的交互体验中。
如果你正在考虑在应用中支持语音交互,请问自己以下问题:
- 用户可以通过语音执行哪些操作? 它们是否可以在页面之间导航、调用命令或以文本字段、简短笔记或长消息的形式输入数据?
- 语音输入是否是完成任务的好选择?
- 用户如何知道语音输入何时可用?
- 应用是否始终侦听,还是用户需要采取操作以便应用进入侦听模式?
- 哪些短语启动作或行为? 是否需要在屏幕上枚举短语和动作?
- 是否需要提示、确认和消除歧义屏幕或 TTS?
- 应用和用户之间的交互对话框是什么?
- 应用上下文是否需要自定义或受约束的词汇(如医学、科学或区域设置) ?
- 是否需要网络连接?
文本输入
文本输入的范围可以是短格式输入(如单个单词或短语),也可以是长格式输入,例如多个短语、段落或连续听写。 短表单输入的长度通常小于 10 秒,而较长的表单输入会话长度可达 2 分钟。 长表单输入可以在无需用户干预的情况下重启,呈现连续听写的效果。
提供视觉提示以指示语音识别受支持且可供用户使用,以及用户是否需要打开它。 例如,使用带有麦克风标志符号的命令栏按钮(请参阅 命令栏)显示可用性和状态。
提供持续识别反馈,以最大程度地减少执行识别时任何明显的响应缺失。
让用户使用键盘输入、消除歧义提示、建议或其他语音识别来修改识别文本。
如果从语音识别以外的设备(如触摸或键盘)检测到输入,请停止识别。 此输入可能表示用户已转到另一个任务,例如更正识别文本或与其他表单字段交互。
指定没有语音输入指示识别结束的时间长度。 在此时间段后,不要自动重启识别,因为它通常表示用户停止与应用交互。
在某些情况下,可能需要网络连接才能支持语音识别。 如果没有可用的识别资源,请禁用所有连续识别界面并终止识别会话。
统率
语音输入可以启动作、调用命令和完成任务。
如果空间允许,请考虑使用有效输入的示例显示当前应用上下文支持的响应。 此方法可减少应用需要处理的潜在响应,并消除用户的混淆。
尝试制定问题框架,以尽可能具体地引起响应。 例如,“你今天要做什么?”是非常开放的,需要一个非常大的语法定义,因为响应的差别有多大。 或者,“是否要玩游戏或听音乐?” 将响应限制为两个有效答案中的一个,其语法定义相应较小。 小语法更易于编写,并生成更准确的识别结果。
语音识别置信度较低时,请求用户确认。 如果用户的意图不清楚,最好得到澄清,而不是启动意外的操作。
提供视觉提示以指示语音识别受支持且可供用户使用,以及用户是否需要打开它。 例如,使用带有麦克风标志符号的命令栏按钮(请参阅 命令栏指南)显示可用性和状态。
如果语音识别开关通常不显示视图,请考虑在应用的内容区域中显示状态指示器。
如果用户启动识别,请考虑使用内置的识别体验实现一致性。 内置功能体验包括可自定义的界面,界面中包括提示、示例、消除歧义、确认和错误信息。
屏幕因指定的约束而异:
预定义语法(听写或网页搜索)
- 监听屏幕。
- 智能屏幕。
- Heard you say屏幕或错误屏幕。
字词或短语列表,或 SRGS 语法文件
- 监听屏幕。
- 你说的屏幕,如果用户说的内容可以解释为多个潜在结果。
- Heard you say屏幕或错误屏幕。
在监听屏幕上,您可以:
- 自定义标题文本。
- 提供用户可以说出的内容的示例文本。
- 指定是否显示“听到你说”界面。
- 在 “听到你说” 屏幕上,将识别的字符串读回给用户。
下图显示了使用 SRGS 定义的约束的语音识别器内置识别流的示例。 在此示例中,语音识别成功。
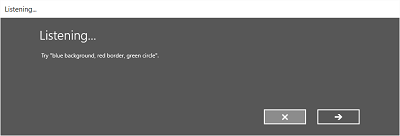
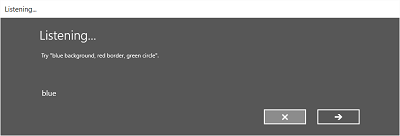
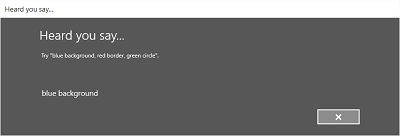
一直监听
应用可以在应用启动时立即侦听和识别语音输入,而无需用户干预。
根据应用上下文自定义语法约束。 此方法使语音识别体验非常有针对性且与当前任务相关,并最大程度地减少错误。
“我能说什么?
启用语音输入时,帮助用户了解应用可以理解的内容及其可执行哪些作。
如果用户启用语音识别,请考虑使用命令栏或菜单命令显示当前上下文中支持的所有字词和短语。
如果语音识别始终处于打开状态,请考虑将短语“我可以说什么?”添加到每一页。 当用户说出此短语时,显示当前上下文中支持的所有字词和短语。 使用此短语为用户提供一致的方式来发现系统中的语音功能。
识别失败
语音识别可能失败。 当音频质量差、识别器仅检测短语的一部分或识别器完全未检测到输入时,将发生故障。
正常处理故障,帮助用户了解识别失败的原因,并恢复。
你的应用应通知用户识别器不了解它们,并且他们需要重试。
请考虑提供一个或多个受支持的短语的示例。 用户可能会重复建议的短语,从而提高识别成功。
显示供用户选择的潜在匹配项列表。 这种方法比再次执行识别过程要高效得多。
始终支持替代输入类型,这对于处理重复识别失败尤其有用。 例如,可以建议用户尝试使用键盘,或使用触摸或鼠标从潜在匹配项列表中选择。
使用内置的语音识别体验,因为它包括通知用户识别不成功的屏幕,并允许用户进行另一次识别尝试。
侦听并尝试更正音频输入中的问题。 语音识别器可以检测音频质量问题,这些问题可能会对语音识别准确度产生不利影响。 可以使用语音识别器提供的信息通知用户问题,并让他们尽可能采取纠正措施。 例如,如果麦克风上的音量设置太低,则可以提示用户朗声或调高音量。
限制条件
约束或语法定义语音识别器可以匹配的口语和短语。 可以指定预定义的 Web 服务语法之一,也可以创建随应用一起安装的自定义语法。
预定义语法
预定义听写和 Web 搜索语法为应用提供语音识别,而无需创建语法。 使用这些语法时,远程 Web 服务执行语音识别并将结果返回到设备。
- 默认的自由文本听写语法可识别用户可以使用特定语言说出的大部分字词和短语。 它经过优化,可以识别短短语。 如果不想限制用户可以说出的内容类型,请使用自由文本听写。 典型用法包括创建笔记或听写邮件的内容。
- Web 搜索语法(如听写语法)包含用户可能说的大量字词和短语。 但是,它经过优化,可以识别人们在搜索 Web 时通常使用的术语。
注释
由于预定义听写和 Web 搜索语法可能很大,并且因为它们处于联机状态(不在设备上),因此性能可能不如设备上安装的自定义语法那么快。
这些预定义的语法最多可以识别 10 秒的语音输入,无需任何创作工作。 但是,它们确实需要连接到网络。
自定义语法
设计和创作自定义语法,并将其与应用一起安装。 设备使用自定义约束执行语音识别。
编程列表约束提供了使用字词或短语列表创建简单语法的轻型方法。 列表约束非常适用于识别短而不同的短语。 显式指定语法中的所有字词也会提高识别准确性,因为语音识别引擎必须仅处理语音才能确认匹配。 还可以以编程方式更新列表。
SRGS 语法是一个静态文档,与编程列表约束不同,它使用 SRGS 版本 1.0 定义的 XML 格式。 SRGS 语法允许在单个识别中捕获多个语义含义,从而提供对语音识别体验的最大控制。
下面是编写 SRGS 语法的一些提示:
- 保持每个语法较小。 包含较少短语的语法往往比包含许多短语的更大语法提供更准确的识别。 对于特定方案,最好有多个较小的语法,而不是对整个应用使用单个语法。
- 让用户了解每个应用上下文的内容,并根据需要启用和禁用语法。
- 设计每个语法,以便用户可以以多种方式朗讲命令。 例如,使用 GARBAGE 规则匹配语法未定义的语音输入。 此规则允许用户讲对应用没有意义的其他字词。 例如,“给我”、“和”、“呃”、“也许”等。
- 使用 sapi:subset 元素来帮助匹配语音输入。 此元素是 SRGS 规范的Microsoft扩展,可帮助匹配部分短语。
- 尝试避免在语法中定义仅包含一个音节的短语。 对于包含两个或多个音节的短语,识别往往更准确。
- 避免使用听起来相似的短语。 例如,短语(如“hello”、“bellow”和“fellow”)可能会混淆识别引擎并导致识别准确度不佳。
注释
所使用的约束类型取决于要创建的识别体验的复杂性。 任何类型都可能是特定识别任务的最佳选择,此外,你可能会在应用中找到所有类型约束的用处。
自定义发音
如果你的应用包含具有异常或虚构字词的专用词汇,或者具有不常见发音的字词,则可以通过定义自定义发音来提高这些单词的识别性能。
对于字词和短语的小型列表,或不经常使用的字词和短语列表,请在 SRGS 语法中创建自定义发音。 有关详细信息,请参阅 token Element 。
对于较大的字词和短语列表,或常用字词和短语,请创建单独的发音词典文档。 有关详细信息,请参阅 “关于词典”和“拼音字母 表”。
Testing
使用应用程序的目标受众测试语音识别的准确性及其相关支持UI。 此方法可帮助你确定语音交互体验在应用中的有效性。 例如,用户是否因为您的应用程序没有识别常见语句而得到不佳的识别结果?
修改语法以支持此短语,或者为用户提供受支持的短语列表。 如果已提供受支持的短语列表,请确保用户可以轻松找到它。
文本转语音 (TTS)
TTS 从纯文本或 SSML 生成语音输出。
尝试设计礼貌和鼓励性的提示。
请考虑是否应读取长字符串文本。 听短信是一回事,但听一长串难以记住的搜索结果是另一回事。
提供媒体控件,让用户暂停或停止 TTS。
试听所有 TTS 字符串,以确保它们可理解且听起来自然。
- 将不同寻常的单词序列或说话部分数字或标点符号组合在一起可能会导致短语变得不可理解。
- 当语音的重音或节奏与母语者的说话方式不同时,会显得不自然。
可以使用 SSML 而不是纯文本作为语音合成器输入来解决这两个问题。 有关 SSML 的详细信息,请参阅 使用 SSML 控制合成语音 和 语音合成标记语言参考。