InkAnalysis API 为平板电脑开发人员提供了强大的工具来以编程方式检查墨迹输入。 API 将墨迹分类为有意义的类别,例如字词、线条、段落和绘图。
可以通过多种方式使用每个分类,包括改进手写的识别结果。
墨迹分析基础知识
本部分介绍平板电脑平台墨迹分析技术,并说明何时以及如何使用它。
InkAnalysis API 有效地结合了两种不同但互不相同的技术:手写识别和布局分类。 将这两种技术组合在一起,可以得出比单独拍摄的部件更大的结果。
手写识别是手写数字墨迹的计算分析,用于返回给定语言中基于字符的解释。 也就是说,手写识别是计算机如何“读取”一个人的手写。
墨迹分析可以进一步细分为墨迹分类和版式分析。 墨迹分类是墨迹在语义上有意义的单元(如段落、线条、字词和绘图)的计算划分。 版式分析是墨迹输入的计算检查,用于确定墨迹在墨迹表面上的位置,以及笔划在空间上甚至语义上如何相互关联。 例如,布局分析可以告知特定墨迹是批注或标注。
识别
在 InkAnalysis API 中将识别与墨迹分析相结合如何帮助开发人员的一个示例是识别结果的改进。 Tablet PC 手写识别引擎主要用于识别单个水平墨迹线。 但是,人们在做笔记时往往会写多行,并且不保证这些行相对于页面水平。 使用 InkAnalysis API 时,墨迹分析器会预处理墨迹,然后再发送到识别器。 在识别之前,分析的墨迹会转换为水平墨迹,从而改善识别结果。
识别的其他好处是通过让墨迹分析器在将墨迹发送到识别器之前更正不正确的笔划顺序信息来得出的。 此外,识别结果现在以选择性方式提供。 也就是说,开发人员可以在一次调用中快速检索单个单词、行或段落的识别结果。
墨迹分类
当然,在多种方案中,你可以保持墨迹数据不变,而不是立即将其转换为文本。 墨迹分析在这里也带来了好处。 具体而言,InkAnalysis API 提供根据笔划墨迹是书写还是绘图来拆分墨迹的功能。 分类为书写的墨迹笔划是构成单词或字符的笔划。 所有其他笔划都是绘图。 这提供了一种访问墨迹数据的新方法,支持新的用户方案。 例如,你可以实现选择,以便根据用户点击的笔划类型而有所不同;如果用户点击书写笔划,应用程序会选择构成该单词的整个笔划集,如果用户点击绘图笔划,应用程序将仅选择该笔划。
布局分析
有用的版式分析实际上远远超出了将墨迹分解成书写和绘图组件的相对简单。
墨迹分析还包括更丰富的笔划书写和绘图细目。 作为一个非常简单的示例,采用一个墨迹 blob,如下图所示。

平台分析这些笔划后,将返回这些笔划的树表示形式,如下图所示。 对于此简单情况,树仅包含段落、行和单词信息,但随着墨迹文档复杂性的增加,此树的丰富性也随之增加。
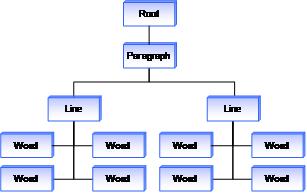
由于此信息现在分为可管理的单元,因此现在可以创建更强大的功能。 例如,应用程序可以扩展用户点击以选择单词的功能,在该功能中,用户点击一次以选择单词,点击两次以选择整行,点击三次以选择整个段落。 通过利用分析操作返回的树结构,应用程序可以将点击的区域关联回树中的笔划。 应用程序找到笔划后,可以向上浏览树,以确定如何以及要选择哪些相邻笔划。
选择整行是墨迹分析优点的简单示例,但当考虑墨迹分析器能够检测不同类型的分层结构时,这种可能性就变得很大:
- 有序列表和无序列表
- 形状
- 与文本内联编写的批注注释
功能类型因应用程序而异,具体取决于要求和可用的墨迹分析和识别引擎。
关键墨迹分析功能
InkAnalysis API 的主要功能包括以下功能:
- 增量分析
- 持久性
- 数据代理
- 和解
- 扩展性
增量分析
当最终用户使用墨迹时,他们通常将其视为手写。 墨迹会持续执行编辑操作,例如添加新墨迹、删除现有墨迹和修改墨迹属性,所有操作都以持续编辑手写的方式完成。 这些编辑操作会影响分析结果。 进行编辑时,通常可以在特定时间点将其隔离到文档的各个部分。 例如,假设用户写入五行墨迹。 应用程序分析墨迹的标准方法是等到用户写完所有五行墨迹(例如段落),然后以同步或异步方式分析结果。
可以通过隔离写入时分析的区域,然后仅重新分析已更改的结果部分,来优化分析这五行所花费的总时间。 分析第一行后,除非最终用户对其进行修改,否则它永远不会再次被识别。 识别第二行被视为独立的识别操作。
此增量方法适用于识别操作的行级别,但它需要在更高级别的墨迹分析操作中工作。 例如,由于墨迹分析器可以检测这五行墨迹 (的不同更高级别分类,因此它可以是标准段落或列表中的五个项) ,因此墨迹分析器的增量方法是必须分析这些更高的结构。 也就是说,在墨迹分析器将第一行墨迹分类为线条后,它会在对第二行进行分类时仔细检查它是否仍然是一行。 但是,墨迹分析器会将此双重检查隔离到段落,并在分析第二段时忽略第一段,将第二段视为独立的墨迹分析器操作。 当应用程序中已存在大量墨迹时,这种增量分析方法可显著节省处理时间。
持久性
增量分析在 InkAnalyzer 对象的给定会话或实例中非常有效。 但是,将墨迹保存到磁盘后,第一代平板电脑平台 API 无法执行增量分析。 InkAnalysis API 支持将墨迹与分析结果的持久形式一起保存到磁盘。 可以在加载墨迹时加载分析结果,并且可以将分析结果注入 到 InkAnalyzer 的新实例中。 然后,InkAnalyzer 对象的新实例具有与之前相同的结果状态,现在可以接受任何修改作为对现有状态的增量更改,而不是再次分析所有内容。
数据代理
许多应用程序在其应用程序中已有某种现有的文档结构;例如,图形或数据库。 InkAnalyzer 还在 ContextNode 对象的树中以结构化形式显示结果。 InkAnalyzer 结构和应用程序的现有结构需要从两个方向进行互操作:结果从 InkAnalyzer 拉取到应用程序中,状态从应用程序推送到 InkAnalyzer。
如果只需将 结果从 InkAnalyzer 提取到应用程序的结构中,就相对简单。 应用程序将循环访问结果树并复制 (将) 所需的结果的所有部分集成到其现有数据结构中。 但是,由于许多水平应用程序需要增量分析和对磁盘的持久性,因此问题变得双向。 状态 (过去的结果) 需要从应用程序的结构中拉取并推送到 InkAnalyzer 中。
为了满足此要求, InkAnalyzer 包含一系列在分析操作期间在适当时间引发的事件,以允许应用程序将数据请求代理回其现有结构。 仅针对增量操作所需的 ContextNode 对象引发这些事件。
和解
大多数应用程序都希望分析后台的墨迹,以尽量减少用户界面中断。 但是,如果用户更改正在分析的墨迹 (或相邻墨迹) ,则分析后台墨迹会导致问题。 例如,如果用户在后台操作期间删除墨迹,则生成的结构将反映文档在后台操作开始时的状态,而不是在后台操作完成时的状态。
为了帮助应用程序, InkAnalyzer 协调分析操作开始和结束之间的文档状态差异。 在后台运行分析时,用户或应用程序所做的更改始终覆盖在后台计算的结果。 对帐后,仅报告与文档更改不冲突的结果结构部分,并标记冲突的笔划以供将来分析。 下次运行后台分析操作时,将根据新状态重新计算结果。
下图展示了此过程。 时间在关系图中以线性方式从上到下表示。
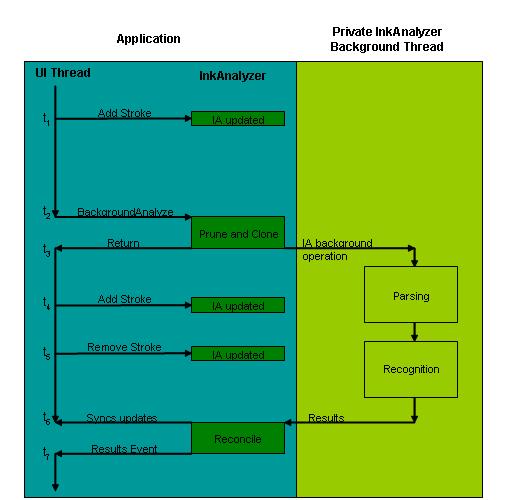
- 在 1 (t1) 时,应用程序从最终用户收集墨迹,包括任何类型的墨迹修改,例如添加、删除或修改。
- 在 t2,应用程序调用后台分析操作。 InkAnalyzer 确定哪些墨迹没有结果,哪些墨迹需要仔细检查。 它复制所需的墨迹数据,以允许后台线程独立执行。
- 在 t3, InkAnalyzer 将用户界面线程执行返回到应用程序。 InkAnalyzer 创建第二个线程、后台分析线程,墨迹分析和识别引擎将分析复制的墨迹数据。
- 当分析操作发生在第二个后台线程上时,最终用户将继续编辑文档,在 t4 和 t5 处添加和删除笔划数据。 这些编辑可能会与后台正在处理的工作冲突。
- 在 t6 中,后台线程已完成分析操作,结果已准备就绪。 在 InkAnalyzer 将结果传达给应用程序之前,它会运行一种对帐算法,以确定用户在计算分析操作时所做的编辑是否 (t4 和 t5) 与结果冲突。 如果检测到任何冲突,则会标记碰撞笔划以供重新分析,这在应用程序下次调用后台分析操作时发生。
- 最后,在 t7,检测到所有冲突后, InkAnalyzer 会将结果呈现给应用程序。
扩展性
InkAnalysis API 允许应用程序使用新型分析引擎,从而防止应用程序不得不重写 InkAnalysis API 的所有优点,包括对帐、数据代理、持久性和增量分析。
相关主题