新增專業版語音的訓練資料集
當您準備好為應用程式建立自訂文字轉換語音的語音時,第一個步驟是收集音訊錄製和相關聯的腳本,以開始定型語音模型。 如需錄製語音範例的詳細資訊,請參閱教學課程。 語音服務會使用此資料來建立調整過的獨特語音,以符合錄製中的語音。 在定型語音之後,您就可以開始在應用程式中合成語音。
您上傳的所有資料都必須符合您所選擇資料類型的需求。 在資料上傳之前,請務必正確地將資料格式化,以確保語音服務可正確地處理資料。 若要確認已正確地將您的資料格式化,請參閱定型資料類型。
注意
- 標準訂用帳戶 (S0) 使用者可同時上傳五個資料檔案。 若達到限制,請等候直到至少其中一個資料檔案完成匯入。 然後再試一次。
- 針對標準訂閱 (S0) 使用者,每個訂閱允許匯入的資料檔案數目上限為 500 個 .zip 檔案。 如需詳細資訊,請參閱語音服務配額和限制。
上傳您的資料
當您準備好上傳資料時,請移至 [準備定型資料] 索引標籤,以新增您的第一個定型集並上傳資料。 「訓練集」是一組音訊語句,以及用於訓練語音模型的對應指令碼。 您可以使用定型集來組織定型資料。 該服務會依每個訓練集來檢查資料整備程度。 您可以將多個資料匯入定型集。
若要上傳定型資料,請遵循下列步驟:
- 登入 Speech Studio。
- 選取自訂語音> 您的專案名稱>準備定型資料>上傳資料。
- 在 [上傳資料] 精靈中,選擇資料類型,然後選取 [下一步]。
- 從您的電腦選取本機檔案,或輸入 Azure Blob 儲存體 URL 以上傳資料。
- 在 [指定目標訓練集] 底下,選取現有的訓練集或建立新的訓練集。 如果您已建立新的訓練集,請先確定已在下拉式清單中選取該訓練集,再繼續進行。
- 選取 [下一步]。
- 輸入您的資料名稱和描述,然後選取 [下一步]。
- 檢閱上傳詳細資料,然後選取 [提交]。
注意
不接受重複的識別碼。 將會移除具有相同識別碼的語句。
會從訓練中移除重複的音訊名稱。 請確定您選取的資料不包含 .zip 檔案內或跨多個 .zip 檔案的相同音訊名稱。 若語句識別碼 (在音訊或指令檔中) 重複,則會遭到拒絕。
當您選取 [提交] 時,會自動驗證資料檔案。 資料驗證包括對音訊檔案的一連串檢查,以驗證其檔案格式、大小和取樣率。 若發生任何錯誤,請加以修正並再次提交。
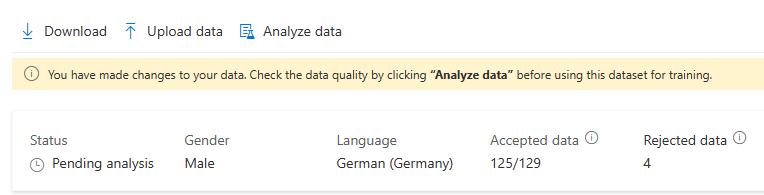
上傳資料之後,您可以在訓練集詳細資料檢視中檢查詳細資料。 您可以在詳細資料頁面上進一步檢查每個資料的發音問題和雜音程度。 句子等級的發音分數範圍從 0 到 100。 70 以下的分數通常表示語音錯誤或腳本不符。 整體分數低於 70 的表達將會遭拒。 大量腔調字可能會降低您的發音分數,並影響產生的數位語音。
線上解決資料問題
上船後,您可以檢查訓練集的資料詳細資料。 在繼續定型語音模型之前,您應該先嘗試解決任何資料問題。
您可以在 Speech Studio 中識別和解決每個語句的資料問題。
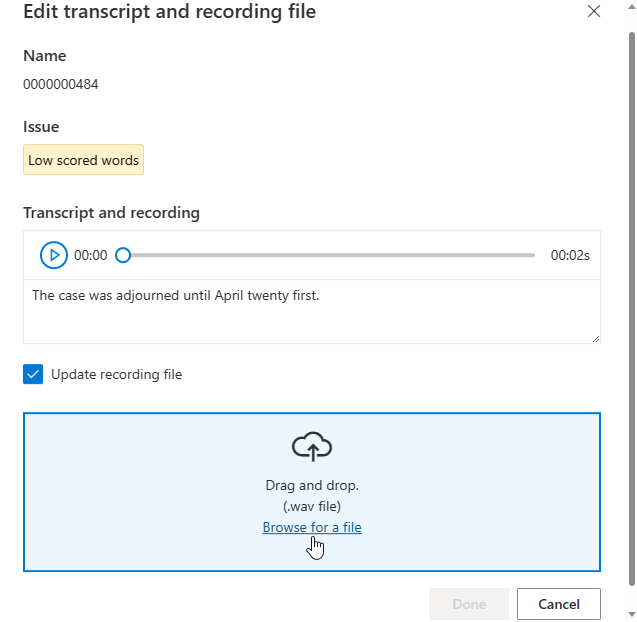
在詳細資料頁面上,移至 [已接受的資料] 或 [已拒絕的資料] 頁面。 選取您想要變更的個別表達,然後選取 [編輯]。
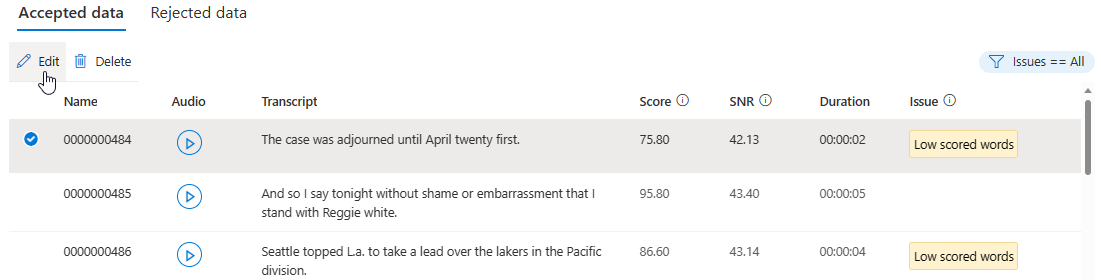
您可以根據準則選擇要顯示哪些資料問題。
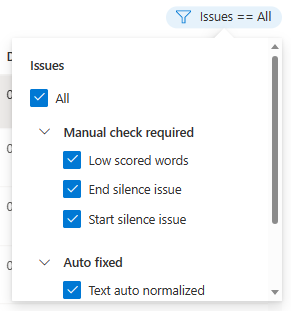
[編輯] 視窗隨即顯示。
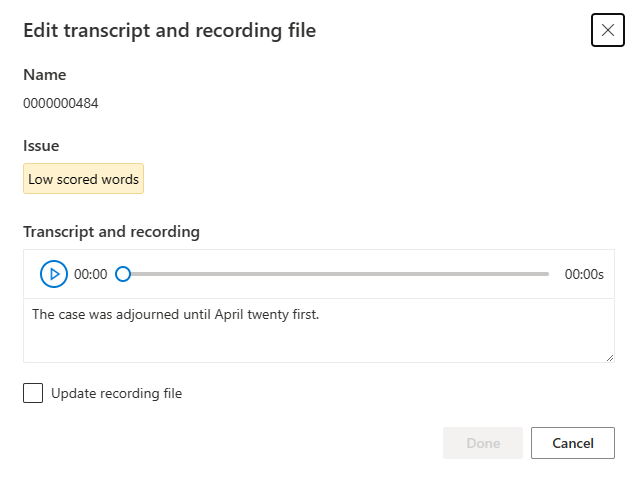
根據編輯視窗的問題描述來更新文字記錄或錄製檔案。
您可以在文字方塊中編輯文字記錄,然後選取 [完成]
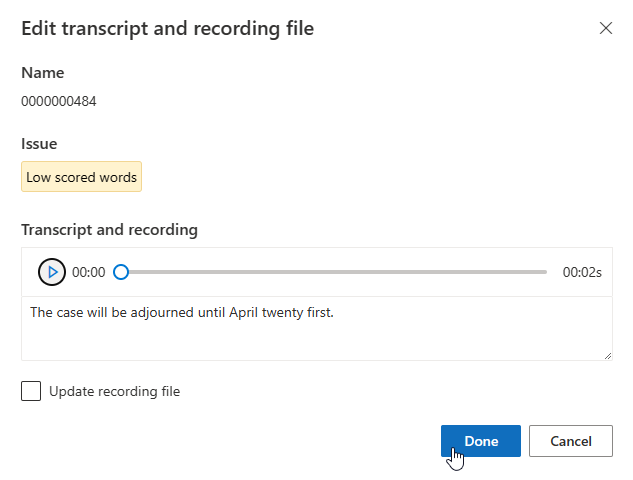
若您必須更新錄製檔案,請選取 [Update recording file] \(更新錄製檔案\),然後上傳已修正的錄製檔案 (.wav)。
對資料進行變更之後,您必須按一下 [分析資料] 來檢查資料品質,再使用此資料集進行定型。
在分析完成之前,您無法針對訓練模型選取此訓練集。
您也可以選取問題語句,然後按一下 [刪除] 加以刪除。
一般資料問題
這些問題分為三種類型。 參閱下列資料表來檢查各別的錯誤類型。
自動拒絕
這些錯誤的資料將不會用於訓練。 具有錯誤的已匯入資料將遭到忽略,因此您不必加以刪除。 您可以在線上修正這些資料錯誤,或再次上傳更正的資料以進行定型。
| 類別 | 名稱 | 描述 |
|---|---|---|
| 指令碼 | 無效的分隔符號 | 您必須以定位字元分隔語句識別碼與指令碼內容。 |
| 指令碼 | 無效的腳本識別碼 | 指令碼行識別碼必須是數值。 |
| 指令碼 | 重複的腳本 | 腳本內容的每一行都必須是唯一的。 這一行是重複的 {}。 |
| 指令碼 | 腳本太長 | 腳本必須少於 1000 個字元。 |
| 指令碼 | 沒有相符的音訊 | 每一個語句 (腳本檔案的每一行) 的識別碼必須符合音訊識別碼。 |
| 指令碼 | 沒有有效的腳本 | 在此資料集中找不到有效的指令碼。 修正詳細問題清單中出現的腳本行。 |
| 音訊 | 沒有相符的腳本 | 沒有音訊檔案符合腳本識別碼。 .wav 檔案的名稱必須與指令檔中的識別碼相符。 |
| 音訊 | 無效的音訊格式 | .wav 檔案的音訊格式無效。 使用像是 SoX 的音訊工具來檢查 .wav 檔案格式。 |
| 音訊 | 低取樣率 | .wav 檔案的取樣率不能低於 16 KHz。 |
| 音訊 | 音訊太長 | 音訊持續時間超過 30 秒。 將長音訊分割成多個檔案。 建議語句的長度小於 15 秒。 |
| 音訊 | 沒有有效的音訊 | 在此資料集中找不到有效的音訊。 請檢查您的音訊資料,然後再次上傳。 |
| 不相符 | 評分較低的語句 | 句子層級發音分數低於 70。 檢閱指令碼與音訊內容,以確定其相符。 |
自動修正
下列錯誤會自動修正,但您應該檢閱並確認已正確進行修正。
| 類別 | 名稱 | 描述 |
|---|---|---|
| 不相符 | 無聲自動修正 | 偵測到開始時無聲的時間短於 100 毫秒,且已自動延長為 100 毫秒。 下載正規化資料集,並加以檢閱。 |
| 不相符 | 無聲自動修正 | 偵測到結束時無聲的時間短於 100 毫秒,且已自動延長為 100 毫秒。 下載正規化資料集,並加以檢閱。 |
| 指令碼 | 自動正規化的文字 | 文字會自動針對數位、符號和縮寫進行正規化。 檢閱指令碼與音訊,以確定其相符。 |
需要手動檢查
下一個資料表中所列的未解決錯誤會影響訓練品質,但在訓練期間不會排除具有這些錯誤的資料。 為了有高品質的訓練,建議手動修正這些錯誤。
| 類別 | 名稱 | 描述 |
|---|---|---|
| 指令碼 | 非正規化文字 | 此指令碼包含符號。 將符號正規化以符合音訊。 例如,將 / 正規化為 斜線。 |
| 指令碼 | 沒有足夠的問題語句 | 至少 10% 的總語句應該是問句。 這可協助語音模型正確表達質疑的語氣。 |
| 指令碼 | 沒有足夠的驚嘆語句 | 至少 10% 的總語句應該是驚嘆句。 這可協助語音模型正確表達令人興奮的語氣。 |
| 指令碼 | 沒有有效的結束標點符號 | 在行尾新增下列其中一項:句號 (半形「.」或全角「。」)、驚嘆號 (半形「!」或全形「!」) 或問號 (半形「?」或全形「?」)。 |
| 音訊 | 神經語音的低取樣率 | 建議您的 .wav 檔案的取樣率應該為 24 KHz 或更高,才能建立神經語音。 若低於此取樣率,則會自動提升至 24 KHz。 |
| 體積 | 整體音量太低 | 音量不應低於 -18 dB (最大音量的 10%)。 在取樣錄製或資料準備期間,將音量平均層級控制在適當範圍內。 |
| 體積 | 音量溢位 | 在 {}s 偵測到溢位音量。 調整錄製設備以避免音量溢位到尖峰值。 |
| 體積 | 開始時無聲問題 | 前 100 毫秒的無聲並未清除。 減少錄製底噪位準,並保留前 100 毫秒的開頭無聲。 |
| 體積 | 結束時無聲問題 | 最後 100 毫秒的無聲並未清除。 減少錄製底噪位準,並保留最後 100 毫秒的結束無聲。 |
| 不相符 | 評分較低的單字 | 請檢閱指令碼與音訊內容,以確定其相符並控制底噪位準。 減少完整無聲的長度,或在無聲時間太長時將音訊分割成多個語句。 |
| 不相符 | 開始時無聲問題 | 第一個單字前面聽到額外音訊。 請檢閱腳本和音訊內容,以確定其相符、控制本底噪音層級,並且讓前 100 毫秒無聲。 |
| 不相符 | 結束時無聲問題 | 最後一個單字後面聽到額外音訊。 請檢閱腳本和音訊內容,以確定其相符、控制本底噪音層級,並且讓最後 100 毫秒無聲。 |
| 不相符 | 低訊號雜訊比 | 音訊 SNR 等級低於 20 dB。 建議至少 35 dB。 |
| 不相符 | 沒有任何可用的分數 | 無法辨識此音訊中的語音內容。 請檢查音訊和腳本內容以確定音訊有效,並且與腳本相符。 |
下一步
您需要訓練資料集來建立專業版語音。 訓練資料集包含音訊和腳本檔案。 音訊檔案是語音配音員讀取腳本檔案的錄製內容。 腳本檔案是音訊檔案的文字。
在本文中,您會建立訓練集並取得其資源識別碼。 然後,使用資源識別碼,您可以上傳一組音訊和腳本檔案。
建立訓練集
若要建立訓練集,請使用自訂語音 API 的 TrainingSets_Create 作業。 根據下列指示來建構要求本文:
- 設定必要的
projectId屬性。 請參閱 建立專案。 - 將必要的
voiceKind屬性設定為Male或Female。 稍後無法變更種類。 - 設定必要的
locale屬性。 這應該是訓練集資料內容的地區設定。 訓練集的地區設定應該與 同意陳述式的地區設定相同。 稍後無法變更此地區設定。 您可以在這裡找到文字轉換語音的地區設定清單。 - (選用) 設定訓練集描述的
description屬性。 稍後可以變更訓練集描述。
使用 URI 提出 HTTP PUT 要求,如下列 TrainingSets_Create 範例所示。
- 以您的語音資源金鑰取代
YourResourceKey。 - 將
YourResourceRegion取代為您的語音資源區域。 - 將
JessicaTrainingSetId取代為您選擇的訓練集識別碼。 區分大小寫的識別碼將會用於訓練集的 URI 中,且稍後無法變更。
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2023-12-01-preview"
您應該會收到下列格式的回應本文:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
上傳訓練集資料
若要上傳一組音訊和腳本,請使用自訂語音 API 的 TrainingSets_UploadData 作業。
呼叫此 API 之前,請先將錄製內容和腳本檔案儲存在 Azure Blob 中。 在下列範例中,錄製內容檔案為 https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.wav,腳本檔案為 https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt。
根據下列指示來建構要求本文:
- 將必要的
kind屬性設定為AudioAndScript。 此種類會決定訓練集的類型。 - 設定必要的
audios屬性。 在audios屬性內,設定下列屬性:- 將必要的
containerUrl屬性設定為包含音訊檔案的 Azure Blob 儲存體容器 URL。 針對具有讀取和清單權限的容器使用 共用存取簽章 (SAS)。 - 將必要的
extensions屬性設定為音訊檔案的副檔名。 - 或者,設定
prefix屬性,以設定 Blob 名稱的前置詞。
- 將必要的
- 設定必要的
scripts屬性。 在scripts屬性內,設定下列屬性:- 將必要的
containerUrl屬性設定為包含腳本檔案的 Azure Blob 儲存體容器 URL。 針對具有讀取和清單權限的容器使用 共用存取簽章 (SAS)。 - 將必要的
extensions屬性設定為腳本檔案的副檔名。 - 或者,設定
prefix屬性,以設定 Blob 名稱的前置詞。
- 將必要的
使用 URI 提出 HTTP POST 要求,如下列 TrainingSets_UploadData 範例所示。
- 以您的語音資源金鑰取代
YourResourceKey。 - 將
YourResourceRegion取代為您的語音資源區域。 - 如果您在上一個步驟中指定了不同的訓練集識別碼,請取代
JessicaTrainingSetId。
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2023-12-01-preview"
回應標頭包含 Operation-Location 屬性。 使用此 URI 來取得 TrainingSets_UploadData 作業的詳細資料。 以下是回應標頭的範例:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2023-12-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345
下一步
意見反映
即將推出:我們會在 2024 年淘汰 GitHub 問題,並以全新的意見反應系統取代並作為內容意見反應的渠道。 如需更多資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交及檢視以下的意見反映: