本文提供您為專業語音微調準備高品質語音範例的最佳做法。 若要了解數據的處理方式,以及數據接受的最低需求,請參閱 上傳您的數據。
從頭開始打造高品質的專業聲音並不是一項休閒事業。 自訂語音的核心元件是人類語音的大量音訊樣本集合。 這些錄音具有高品質至關重要。 選擇具備製作這類錄音經驗的語音配音員,並由錄音工程師使用專業的設備錄音。
但是在製作這些錄音之前,您需要一個腳本:您的配音員為建立音訊樣本而說出的字詞。
製作專業的錄音涉及許多小而重要的細節。 本指南是協助您獲得良好且一致結果之程序的藍圖。
準備高品質語音資料的祕訣
高度自然的自定義語音取決於數個因素,例如訓練數據的品質和大小。
定型資料的品質是主要因素。 例如,在相同的定型集中,一致的音量、說話速率、說話音調和說話風格對於建立高品質的自定義語音至關重要。 您也應該避免錄製中的背景雜訊,並確定腳本和錄製相符。 若要確保資料的品質,您必須遵循腳本選取準則和錄製需求。
關於定型數據的大小,在大部分情況下,您可以使用 300 個語句來建置合理的自定義語音。 根據我們的測試,在大部分語言中新增更多定型資料不一定能改善語音本身的自然性 (使用 MOS 分數測試)。不過,使用涵蓋更多單字實例的定型資料,您有可能降低語音不滿意部分的比率,例如問題。 若要聽聽語音音效的不滿意部分,請參閱 GitHub 範例。
在某些情況下,您可能會想要具有獨特特性的語音角色。 例如,卡通人物需要具有特殊說話樣式的語音,或是動態的語調。 針對這類情況,建議您至少準備 1000 個 (最好是 2000 個) 表達,並在專業錄製工作室中加以錄製。 若要深入瞭解如何改善語音模型的品質,請參閱 使用自定義語音的特性和限制。
錄音角色
自訂語音錄製專案中有四個基本角色:
| 角色 | 目的 |
|---|---|
| 配音員 | 此人的語音構成了自定義語音的基礎。 |
| 錄音工程師 | 監看錄音的技術層面,並操作錄音設備。 |
| 主管 | 準備腳本並指導配音員的表演。 |
| 編輯器 | 確定音訊檔案已完成準備,並將它們上傳到語音服務。 |
一個人能夠擔任多個角色。 本指南假設您擔任導演角色,並雇用語音配音員和錄音工程師。 如果您想要自行錄音,本文中也提供錄音工程師角色的相關資訊。 在錄製工作階段會話之後,才需要編輯器角色。 同時,導演或錄音工程師可以填補這個角色。
選擇您的配音員
擁有配音、聲優工作、廣播或新聞播音經驗的演員可以成為優秀的語音配音員。 選擇您喜歡的自然語音的配音員。 您可以創造獨特的「角色」聲音,但對於大多數的配音員來說,要始終如一地表現這些聲音更為困難,而且這樣配音可能會造成聲音過勞。 選擇配音員最重要的因素是一致性。 您的錄音應該聽起來像是在同一天、同一個房間錄製的相同語音風格。 您可以透過良好的錄音方法實踐和工程策劃來實現這個理想。
您的語音配音員必須能夠以聽寫清楚的一致速度、音量、音高和音調說話。 他們還需要能夠控制音高變化、情緒影響和言語舉止。 錄製語音樣本可能比其他類型的語音工作更加勞累,因此大多數語音配音員一天只能錄製兩到三小時。 將錄音工作限制為每週三到四天,如果可能的話,兩次錄音之間休息一天。
與您的語音人才合作,開發一個能夠定義自定義聲音整體音質和情感基調的角色。 定義角色的說話樣式,並要求您的語音人才以符合您所需樣式的方式閱讀腳本。 請確定一組定型數據的錄音中,說話樣式會保持一致。
例如,具有自然樂觀個性的角色會以自己的聲音表達樂觀情緒。 不過,對於一組訓練數據,此個性應該以一致的方式表達所有錄製內容。 聆聽現有的聲音,以瞭解您的目標是什麼。
提示
通常您會想要擁有自己製作的錄音。 您的配音員應該同意遵守該專案的僱傭合約。
建立腳本
任何自定義語音錄製會話的起點是腳本,其中包含由您的語音人才表達的語句。 「語句」一詞包含完整的句子和較短的片語。 建置自定義語音需要至少 300 個錄製的語句作為定型數據。
您腳本中的語句可能來自任一處:小說、非小說、演講稿、新聞報導,以及印刷形式的其他任何內容。 如需潛在法律問題的簡短討論,請參閱<合法性>一節。 您也可以撰寫自己的文字。
您的語句不需要來自相同的來源或相同類型的來源,彼此之間也不需要有任何關係。 不過,如果您在語音應用程式中使用設定的片語 (例如「您已成功登入」),請務必將其包含在腳本中。 它可以提升您的自定義聲音在發音這些片語時的準確性。
我們建議錄製腳本包含一般句子和特定領域句子。 例如,如果您打算錄製 2000 個句子,其中 1000 個可能是一般句子,而另外 1000 個則可能是您的目標領域或應用程式使用案例中的句子。
我們會提供每個語言的「一般」、「聊天」和「客戶服務」網域中的範例腳本,以協助您準備錄製腳本。 您可以直接使用這些 Microsoft 共用腳本進行錄製,或使用其作為參考以建立您自己的內容。
腳本選取準則
以下是一些一般指導方針,您可以遵循這些方針,為專業語音微調建立良好的語料庫(錄音樣本)。
在大部分的使用案例中,建議句子長度介於 2 到 15 秒之間,包含拉丁語言的 5 到 30 個單字,非拉丁語言則包含 4 到 80 個單字。 旨在平衡您的腳本,以包含各種句子類型和長度。 請確定您的文稿不包含任何重複的句子。
如果您的使用案例需要特別地混合長短句子並高度強調疑問句或感歎句,建議納入相當比例的句子作為疑問句或感歎句,以及長度可達 20 秒的簡短短語和較長的長句。
若要了解如何平衡不同的句子類型,請參閱下表:
句子類型 涵蓋範圍 語句句子 直述句應該佔 70-80% 的腳本。 簡短單字/片語 簡短單字/片語腳本應該佔語句總計的大約 10%,每個案例 5 到 7 個單字。
短字或片語應該以逗號分隔,以協助提醒語音人才在閱讀時短暫暫停。問題句子(選擇性) 問句應該佔大約 10%-20% 的領域腳本,包括 5%-10% 的上揚語調,以及 5%-10% 的下降語調。
如果您想要產生的語音準確地傳達問題,則需要這些句子。驚嘆號句子 (選擇性) 驚嘆句應該佔大約 10%-20% 的腳本。
如果您想要產生的語音準確傳達驚嘆號,則需要這些句子。注意
您可以根據語言,以每秒單字為單位假設語音速率,以估計句子中的字數。
最佳做法包括:
- 部分語音的對稱涵蓋範圍,例如動詞、名詞、形容詞等。
- 發音的對稱涵蓋範圍。 包括 A 到 Z 的所有字母,讓文字轉換語音引擎學習如何以您的風格來發音每個字母。
- 可讀取、可理解、可讓說話者讀出來的常識腳本。
- 避免單字/片語出現太多類似的模式,例如「簡單」和「更簡單」。
- 在所有句子類型中包含不同格式的數字:地址、單位、電話、數量、日期等。
- 如果這是您自定義語音將讀到的內容,請包含拼字句子。 例如,「Apple 的拼寫是 A P P L E」。
注意
對於情境式處理模式,提供更自然的語調和更好的交談功能。
- 使用段落級文字,而非句子級文字進行錄音。 這種方法有助於擷取句子之間的自然語音流程,並保留內容資訊。
- 理想情況下,每段錄音應該超過 30 秒(拉丁語系中需包含超過 60 個字或非拉丁語系中包含160個字)。
- 具有超過 30 分鐘的總音訊或 300 個語句的情境訓練集可用於訓練自定義語音。
請勿將多個句子放入一行/一個語句中。 每個語句分隔一行。
請確定句子清楚。 一般而言,請勿包含太多非標準的單字,例如數字或縮寫,因為這些單字很難閱讀。 某些應用程式可能需要讀取許多數字或縮寫。 在此情況下,您可以包含這些字組,但是以其口語形式將其正規化。
以下是一些最佳做法範例:
- 對於具有縮寫的行,請寫入 "by the way",而不是 "BTW"。
- 對於具有數字的行,請寫入 "nine one one",而不是 "911"。
- 對於具有縮略字的行,請寫入 "A B C",而不是 "ABC"。
然後,確定您的語音配音員能以預期的方式發音這些字組。 在定型過程中,保持您的腳本和錄製內容相符。
您的腳本應該包含許多不同的單字和句子,其中包含不同類型的句子長度、結構和情緒。
請仔細檢查腳本中是否有錯誤。 若有可能,也讓其他人檢查一下。 當您與您的語音配音員一起瀏覽腳本時,可能會發現到更多錯誤。
語音配音員腳本與定型腳本之間的差異
定型腳本可以與語音配音員腳本不同,特別是針對包含數字、符號、縮寫、日期和時間的腳本。 為語音配音員準備的腳本必須遵循原生閱讀慣例,例如 50% 和 $45。 用於定型的腳本必須正規化,以符合音訊錄製內容,例如「百分之五」和「45 美元」。
注意
我們提供 GitHub 上語音配音員的一些範例腳本。 若要使用範例腳本進行定型,您必須先根據語音配音員的錄製內容來標準化這些腳本,再上傳檔案。
下表顯示語音配音員的腳本與標準化定型腳本之間的差異。
| 類別 | 語音配音員腳本範例 | 定型腳本範例 (標準化) |
|---|---|---|
| 數字 | 123 | 一百二十三 |
| 符號 | 50% | 百分之五十 |
| 縮寫 | 立即 | 盡快 |
| 日期和時間 | 3 月 3 日下午 5 點 | 3 月 3 日下午 5 點 |
腳本的一般瑕疵
腳本品質不良可能會對定型結果造成負面影響。 若要達到高品質的定型結果,請務必避免瑕疵。
腳本瑕疵通常分成下列類別:
| 類別 | 範例 |
|---|---|
| 無意義的內容。 | 「無色彩的綠色想法狂暴地入眠。」 |
| 不完整的句子。 | -「這是我的上個前夕」(沒有主旨,沒有特定意義) -「他們已經有趣 (結尾沒有引號,這並不是完整的句子) |
| 句子中的錯字。 | - 以小寫開頭 - 沒有需要的結束標點符號 - 拼字錯誤 - 缺少標點符號:結尾沒有句點 (新聞標題除外) - 以符號結尾,逗號、問號、驚嘆號除外 - 格式錯誤,例如: - 45$ (應該是 $45) - 單字/標點符號之間沒有空格或有多餘空格 |
| 類似格式重複,每個模式各一個已足夠。 | -「現在紐約是下午 1 點」 -「現在紐約是下午 2 點」 -「現在紐約是下午 3 點」 -「現在西雅圖是下午 1 點」 -「現在華盛頓特區是下午 1 點」 |
| 不常見的外國字詞:腳本中只接受常用的外國字詞。 | 在英文中,使用者可能會在一般會話中用到法文 "faux",但 "coincer la bulle" 之類的法文表達則不常見。 |
| 表情符號或任何其他不常見的符號 |
腳本格式
腳本是在錄音工作期間使用,因此您可以透過任何易於使用的方式設定。 個別建立 Speech Studio 所需的文字檔。
基本腳本格式包含三欄:
- 語句的編號,從 1 開始。 編號會讓錄音室中的每個人輕鬆提及特定的語句 (「讓我們再試一次 356 號」)。 您可以使用 Microsoft Word 的段落編號功能,自動為表格列編號。
- 空白欄,您可以在其中寫下每個語句的錄音段落編號或時間代碼,以協助您在完成錄音後可以找到它。
- 語句本身的文字。
注意
大部分的錄音室都會以簡短的片段錄音,稱為「錄音段落」。 每個錄音段落通常包含 10 到 24 個語句。 只要記下錄音段落編號,就足以在事後找出某個語句。 如果您所在的錄音室喜歡錄製時間較長的錄音,則需要記下時間代碼。 錄音室將會有顯眼的時間顯示。
在每一列之後保留足夠的空間來寫筆記。 請確保語句沒有分隔在頁面之間。 為頁面編號,並將腳本列印在紙張的單面上。
列印三份腳本:一份給語音配音員、一份給錄音工程師,另一份給導演 (您)。 使用迴紋針代替訂書針:經驗豐富的配音員會將頁面分開,以避免在翻頁時產生噪音。
語音配音員聲明
若要訓練神經語音,您必須建立語音人才配置檔,並使用語音人才已同意用於微調專業語音模型的語音數據錄製音訊檔案。 準備錄製腳本時,請確定您包含聲明語句。
合法性
根據著作權法,演員朗讀受著作權保護的文字可視為演出該作者 (應獲得報酬者) 的作品。 此效能無法在最終產品自定義語音中辨識。 即便如此,為此目的使用受著作權保護的作品的合法性尚未完善。 Microsoft 無法針對這個問題提供法律意見;請向您自己的法律顧問諮詢。
還好您可以完全避免這些問題。 有許多您可以使用的文字來源,而不需要權限或授權。
| 文字來源 | 描述 |
|---|---|
| CMU Arctic 語料庫 \(英文\) | 大約有 1100 個都是從已不受著作權保護的作品中選出,且特別適合用於語音合成專案的句子。 絕佳的起點。 |
| 作品不再 受著作權保護 |
作品通常是在 1923 年之前出版。 Project Gutenberg \(英文\) 提供成千上萬個英文版的這類作品。 您可能希望專注在較新的作品上,因為語言更接近現代英文。 |
| 政府工作 | 美國政府的著作在美國境內不受著作權保護,但政府可以在其他國家/區域宣告著作權。 |
| 公眾領域 | 著作權明確放棄或專用於公眾領域的作品。 可能無法在部分司法管轄區完全放棄著作權。 |
| 獲得授權許可的作品 | 根據 Creative Commons 或 GNU 自由文件授權 (GFDL) 散佈的作品。 維基百科使用 GFDL。 不過,某些授權可能會對可能影響建立自定義語音模型之授權內容的效能施加限制,因此請仔細閱讀授權。 |
錄製腳本
請在專門從事語音工作的專業錄音室錄製腳本。 這種錄音室有一個錄音房間、合適的設備和合適的人員來操作它。 建議在錄製上不要吝嗇。
請與錄音室的錄音工程師討論您的專案,並聆聽他們的建議。 錄音的動態範圍壓縮率應該很低或完全沒有 (最多為 4:1)。 音訊具有一致的音量和高信噪比至關重要,同時沒有不必要的聲音。
錄製需求
若要達到高品質的定型結果,請在錄製或資料準備期間遵循下列需求:
清楚且良好的發音
自然速度:音訊檔案之間的速度不要太慢或太快。
適當的音量、韻律和停頓:在相同句子或句子之間保持穩定,正確的標點符號停頓。
錄製期間無雜訊
符合您的角色設計
沒有錯誤的重音:符合目標設計
沒有錯誤的發音
您可以參考以下規格,為音訊樣本做好準備來作為最佳做法。
| 屬性 | 值 |
|---|---|
| 檔案格式 | *.wav、Mono |
| 取樣率 | 24 KHz |
| 樣本格式 | 16 位元、PCM |
| 尖峰音量層級 | -3 dB 到 -6 dB |
| 訊噪比 | > 35 dB |
| 靜音 | - 在開頭和結尾應該有一些靜音時間 (建議 100 毫秒),但是不超過 200 毫秒 - 在單字或片語之間靜音 <-30 dB - 最後一個單字被讀出之後聲波中的靜音 <-60 dB |
| 環境雜訊或回音 | - 說話前聲波開始的雜訊等級 <-70 dB |
注意
您可以用較高的取樣率和位元深度來錄製,例如,以 48 KHz 24 位元 PCM 的格式錄製。 在專業語音調校期間,我們會自動將它降取樣到 24 KHz 16 位 PCM。
信噪比 (SNR) 愈高表示您音訊中的雜音愈低。 在專業錄音室中,通常可達到 35+ SNR。 SNR 低於 20 的音訊可能會在您產生的語音中導致明顯的雜音。
請考慮以較低的發音分數或較差的信噪比來重新錄製任何語句。 如果您無法重新錄製,請考慮從您的資料中排除這些語句。
典型音訊錯誤
為了達到高品質的定型結果,強烈建議您避免音訊錯誤。 音訊錯誤通常分為下列幾類:
音訊檔案名稱與腳本識別碼不相符。
WAR 檔案的格式無效,且無法讀取。
音訊取樣率低於 16 KHz。 建議 wav 檔案取樣率等於或大於 24 KHz,以獲得高品質的神經語音。
音量尖峰不在 -3 dB (最大音量的 70%) 至 -6 dB (50%) 範圍內。
波形溢位:尖峰值的波形會遭到切割,因此不完整。
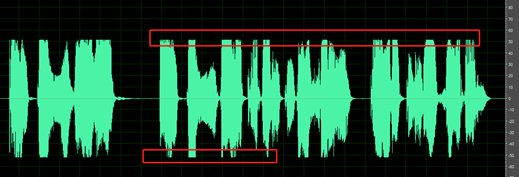
錄製的無聲段落並不乾淨;您可能聽到環境雜訊、人聲噪音和回音等聲音。
例如,以下音訊包含語音之間的環境雜訊。
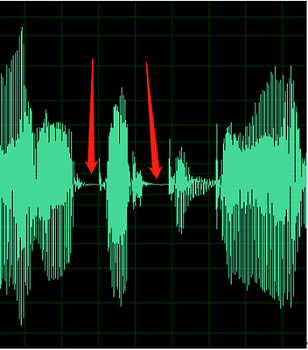
以下樣本包含 DC 位移或回音的跡象。
整體音量太低。 如果音量低於 -18 dB (最大音量的 10%),您的資料會標記為問題。 請確定所有音訊檔案都維持在相同的音量層級。
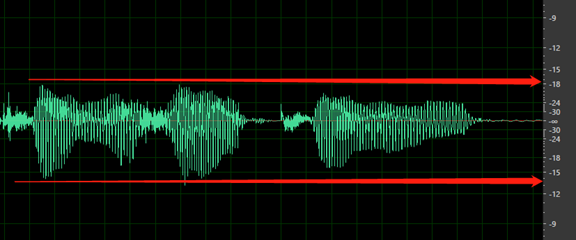
第一個單字之前或最後一個單字之後沒有任何靜音。 此外,開始或結束靜音不應超過 200 毫秒或短於 100 毫秒。
親自動手做
如果您想要自己錄音,而不想要去錄音室,以下是簡短入門。 由於家庭錄音和播客的興起,在網路上找到好的錄音建議和資源比以往更為容易。
您的「錄音室」應該是一個沒有明顯回音或「室內環境音」的小房間。應該盡可能地安靜而且隔音效果良好。 牆上的窗簾可用於減少回音,並能中和或「消除」室內環境的聲音。
錄音時,請使用高品質的錄音室電容式麥克風 (簡稱「麥克風」)。 Sennheiser、AKG,甚至更新的 Zoom 麥克風都可以產生良好的效果。 您可以購買一支麥克風,或從當地的視聽租賃公司租用一支麥克風。 請尋找具有 USB 介面的麥克風。 這種類型的麥克風便利地將麥克風元件、前置放大器和類比數位轉換器結合成一個套件,可簡化線路的連接。
您也可以使用類比式麥克風。 許多出租屋提供以其語音特徵而聞名的「老式」麥克風。 專業的類比式設備使用平衡的 XLR 接頭,而不是消費類設備中使用的 1/4 吋插頭。 如果您使用類比式,您還需要前置放大器,以及包含這些接頭的電腦音訊介面。
將麥克風安裝在支架或吊桿上,並在麥克風前方安裝防噴罩,以消除「爆裂子音」(如 "p" 和 "b") 中的雜訊。有些麥克風配有懸掛支架,可以隔離支架的震動,這很有幫助。
配音員必須與麥克風維持一致的距離。 在地板上使用膠帶標記他們應該站立的位置。 如果配音員比較喜歡坐著,請特別注意監控麥克風距離並避免椅子發出的噪音。
使用支架托住腳本。 避免使支架傾斜,如此可能會將聲音反射到麥克風上。
操作錄音設備的人員,也就是錄音工程師,應該和配音員在不同的房間,以某種方式與錄音室的配音員說話 (「對講電路」)。
錄製時的雜訊越少越好,目標是 -80 dB。
仔細聆聽「錄音室」中沉默時的錄音,找出噪音來源,並消除原因。 常見的噪音來源是通風口、日光燈鎮流器、鄰近道路的交通,以及設備風扇 (甚至筆記型電腦可能也有風扇)。 麥克風和接線可以從鄰近的交流電線接收電噪音,通常是嗡嗡聲或唧唧聲。 「接地迴路 (ground loop)」也會造成唧唧聲,這因為設備插入一個以上的電路所造成。
提示
在某些情況下,您可以使用等化器或降噪軟體外掛程式來幫助消除錄音中的噪音,但最好的方式終究是消除噪音的來源。
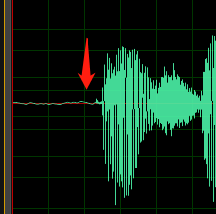
請設定等級,以便在不過載的情況下,使用大多數可用數位錄音的動態範圍。 這表示將音訊調大聲,但不要大聲到失真。 良好的錄音波形範例如下圖所示:
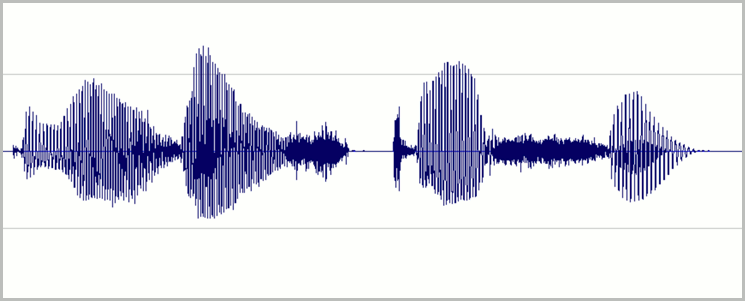
這裡使用大部分的範圍 (高度),但訊號的最高峰未達到視窗的最上方或最下方。 您也可以看到錄音中的靜音近似於細長的水平線,表示背景噪音低。 此錄音具有可接受的動態範圍和信噪比。
根據您所使用的麥克風,可以透過高品質的音訊介面或 USB 連接埠,直接錄製到電腦中。 若是類比式麥克風,則保持音訊鏈簡單:麥克風、前置放大器、音訊介面、電腦。 您可以在合理成本的條件下,取得 Avid Pro Tools 和 Adobe Audition 的每月授權。 如果您的預算緊迫,請嘗試免費的 Audacity \(英文\)。
以 44.1 KHz 16 位元單聲道 (CD 品質) 或更好效果錄音。 如果您的設備支援,目前最先進的是 48 KHz 24 位元。 將音訊提交到 Speech Studio 之前,您可以將音訊降低取樣至 24 KHz 16 位元。 儘管如此,若要獲得高品質的原始錄音檔,仍然需要編輯。
在理想的情況下,讓不同的人擔任導演、工程師和配音員的角色。 請不要嘗試全部自己來。 在緊要關頭,導演和工程師可以是同一個人。
在錄音工作之前
為避免浪費錄音室時間,請在錄音工作之前,與配音員一起瀏覽腳本。 當語音配音員熟悉文本時,他們就可以釐清任何陌生單字的發音。
注意
大多數的錄音室都會在錄音室中提供電子版的腳本。 在此情況下,請直接在腳本的文件中輸入您的筆記大綱。 但是,您仍然希望在錄音工作期間使用紙本副本做筆記。 大多數的工程師也會想要有紙本副本。 此外,您仍然需要為配音員準備另一份紙本副本備用,以防電腦當機。
您的配音員可能會詢問您在一個語句中想要強調哪個詞 (也就是「關鍵詞」)。 告訴他們您想要自然朗讀,而不需要特別強調。 合成語音時可以加入強調,但這不應該是原始錄音的一部分。
指導配音員清晰地發音。 腳本的每個字都應該如所撰寫的字發音。 聲音不應該被省略或混淆在一起,這在非正式交談中很常見,「除非在腳本中就是如此撰寫」。
| 書面文字 | 不想要的非正式發音 |
|---|---|
| 永遠不會放棄你 | 永遠不會放棄你 |
| 有四個燈 | 有四個燈 |
| 今天天氣如何 | 今天天氣如何 |
| 向我的小朋友打聲招呼 | 向我的小老弟打個招呼 |
聲音專業人士不應該在單字之間加入明顯的暫停。 即使聽起來有一點正式,句子仍然應該自然流暢。 這種精細的區分可能需要練習才能做到正確。
錄音工作
在錄音工作開始時,建立典型語句的參考錄音或「匹配檔案」。 要求配音員大約在每一頁中重複這一行。 每次都將新錄音與參考值進行比較。 這種練習有助於配音員在音量、節奏、音調和語調方面保持一致。 同時,工程師可以使用匹配檔案作為音量和整體一致性的參考。
在休息之後或於其他日繼續錄音時,匹配檔案尤其重要。 為語音配音員播放幾次,並讓他們每次都重複,直到他們配合得很好為止。
若要記錄具有特定樣式的主體,請仔細選擇展示所需風格的腳本。 在錄製期間,確保配音員在音量、節奏、音高和音調中保持一致,以達到體現預期風格的錄音。
指導配音員深呼吸,並在每個語句之前停頓一下。 在語句之間錄製幾秒鐘的沉默。 每次出現同樣字組時,應以同樣的方式發音,但需考慮上下文。 例如,作為動詞的「record」,其發音就與作為名詞的「record」不同。
在第一次錄音之前,錄製大約五秒鐘的靜音以捕捉「室內環境音」。 這種做法可協助 Speech Studio 彌補錄製中的雜訊。
提示
您需要捕捉的是語音配音員,因此您可以只製作他們台詞的單聲道 (單頻道) 錄音。 但是,如果以立體聲錄製,則可以使用第二個頻道錄製控制室中的談話,以擷取對特定台詞或錄音段落的討論。 從上傳至 Speech Studio 的版本中移除此音軌。
使用耳機仔細聆聽配音員的表演。 您要尋找良好但自然的發音、正確的發音,而且沒有不必要的聲音。 不要猶豫,立即要求配音員重新錄製不符合這些標準的語句。
提示
如果您使用大量語句,單一語句可能不會對產生的自定義語音產生明顯影響。 只要記下問題的任何語句、將其從數據集中排除,以及查看自定義語音的顯示方式,可能更方便。您隨時可以回到工作室,稍後再錄製遺漏的範例。
請記下腳本上每個語句的錄音段落編號或時間代碼。 要求工程師也在錄音的中繼資料或提示表中標記每個語句。
定期休息並提供飲料,以協助語音配音員保持良好的聲音。
在錄音工作之後
現代的錄音室是在電腦上執行。 在錄音工作結束時,您會收到一或多個音訊檔案,而不是錄音帶。 這些檔案可能是 WAV 或 AIFF 格式的 CD 品質 (44.1 KHz 16 位元) 或是更好的品質。 24 kHz 16 位元是常見且令人滿意的品質。 自定義語音的預設取樣率為 24 KHz。 建議您針對定型數據使用 24 KHz 和更高的取樣率。 通常不需要更高的取樣率,例如 96 KHz。
Speech Studio 要求每個提供的語句都位於自己的檔案中。 錄音室提供的每個音訊檔都包含多個語句。 因此,主要的後製工作是拆分錄音並準備提交。 錄音工程師可能已經在檔案中放入標記 (或提供不同的提示表) 來表示每個語句的開始位置。
使用您的筆記尋找所需的確切錄音段落,然後使用音效編輯公用程式 (例如 Avid Pro Tools \(英文\)、Adobe Audition 或免費的 Audacity \(英文\)),將每個語句複製到一個新檔案。
請仔細聆聽每個檔案。 在這個階段,您可以編輯您在錄音過程中遺漏的多餘微小聲音 (例如,措辭之前輕微的咂嘴),但要注意不要移除任何實際的語音。 如果您無法修正檔案,則請將其從您的資料集移除,並記下您已經移除。
將每個檔案轉換成 16 位,並在儲存之前將取樣率 24 KHz 和更高,而且如果您錄製了工作室聊天,請移除第二個通道。 以 WAV 格式儲存每個檔案,並以腳本中的語句編號為檔案命名。
最後,建立與每個 WAV 檔案相關聯的文字記錄,其中包含對應語句的文字版本。 定型您的語音模型包括所需格式的詳細資料。 您可以直接從腳本複製文字。 然後建立 WAV 檔案和文字記錄的 Zip 檔案。
請將原始錄音保存在安全的地方,以防日後需要。 請同時保留您的腳本和筆記。
下一步
您已準備好上傳錄製內容,並建立您的自定義語音。