Azure AI Studio 中的內容篩選
Azure AI Studio 包含內容篩選系統,可搭配核心模型和 DALL-E 影像產生器執行。
重要
內容篩選系統不適用於 Azure OpenAI 服務中 Whisper 模型處理的提示和完成。 深入了解 Azure OpenAI 中的 Whisper 模型。
運作方式
此內容篩選系統是由 Azure AI 內容安全所提供,現在可透過一組分類模型來執行提示輸入和完成輸出,旨在偵測並防止有害內容的輸出。 API 設定和應用程式設計的變化可能會影響完成,因而篩選行為。
透過 Azure OpenAI 模型部署,您可以使用預設內容篩選,或建立您自己的內容篩選器 (稍後所述)。 在模型目錄中,Azure AI 所策劃的其他文字模型也可以使用預設內容篩選,但這些模型尚無法使用自定義內容篩選。 透過模型即服務提供的模型,預設會啟用內容篩選,且無法設定。
語言支援
內容篩選模型已針對下列語言進行訓練及測試:英文、德文、日文、西班牙文、法文、義大利文、葡萄牙文和中文。 不過,服務可在許多其他語言下運作,但品質會有所不同。 在所有情況下,您應該執行自己的測試,以確保其適用於您的應用程式。
建立內容篩選
對於 Azure AI Studio 中的任何模型部署,您可以直接使用預設內容篩選器,但您可能想要擁有更多控制權。 例如,您可以讓篩選更嚴格或更寬鬆,或啟用更進階的功能,例如提示盾牌和受保護的內容偵測。
請遵循這些步驟建立內容篩選器:
移至 AI Studio 並導覽至您的中樞。 然後選取左側導覽的 [內容篩選] 索引標籤,然後選取 [建立內容篩選] 按鈕。

在 [基本資訊] 頁面上,輸入內容篩選的名稱。 選取要與內容篩選相關聯的連線。 然後選取下一步。

在 [輸入篩選] 頁面上,您可以設定輸入提示的篩選條件。 設定每個篩選類型的動作和嚴重性層級閾值。 您會在此頁面上設定預設篩選和其他篩選條件 (例如提示盾牌以進行越獄攻擊)。 然後選取下一步。

內容會依類別加上批注,並根據您設定的閾值封鎖。 針對暴力、仇恨、性及自我傷害類別,調整滑桿以阻止高、中或低嚴重性的內容。
在 [輸出篩選] 頁面上,您可以設定輸出篩選,這會套用至模型所產生的所有輸出內容。 和之前一樣設定個別篩選。 此頁面也提供 [串流模式] 選項,可讓您在模型產生的內容時,以近乎即時的方式篩選內容,以減少延遲。 完成之後,選取 [下一步]。
內容會依類別加上批注,並根據閾值封鎖。 針對暴力內容、仇恨內容、性內容和自殘內容類別,調整閾值,以封鎖同等或更高嚴重性等級的有害內容。
或者,在 [部署] 頁面上,您可以將內容篩選條件與部署產生關聯。 如果選取的部署已附加篩選,您必須確認要取代。 您也可以稍後將內容篩選與部署產生關聯。 選取 建立。

內容篩選組態是在 AI Studio 中的中樞層級建立。 深入了解 Azure OpenAI 文件中的可設定性。
在 [檢閱] 頁面上檢閱設定,然後選取 [建立篩選器]。




使用封鎖清單作為篩選
您可以將封鎖清單套用為輸入或輸出篩選條件,或兩者皆可套用。 在 [輸入篩選] 和/或 [輸出篩選] 頁面上,啟用 [封鎖清單] 選項。 從下拉式清單中選取一或多個封鎖清單,或使用內建粗話封鎖清單。 您可以將多個封鎖清單合併到相同的篩選。
套用內容篩選
篩選建立程序可讓您選擇將篩選套用至您想要的部署。 您也可以隨時變更或移除部署中的內容篩選。
請遵循下列步驟,將內容篩選套用至部署:
移至 AI Studio 並選取項目。
選取 [部署] 並選擇其中一個部署,然後選取 [編輯]。

在 [更新部署] 視窗中,選取您要套用至部署的內容篩選器。
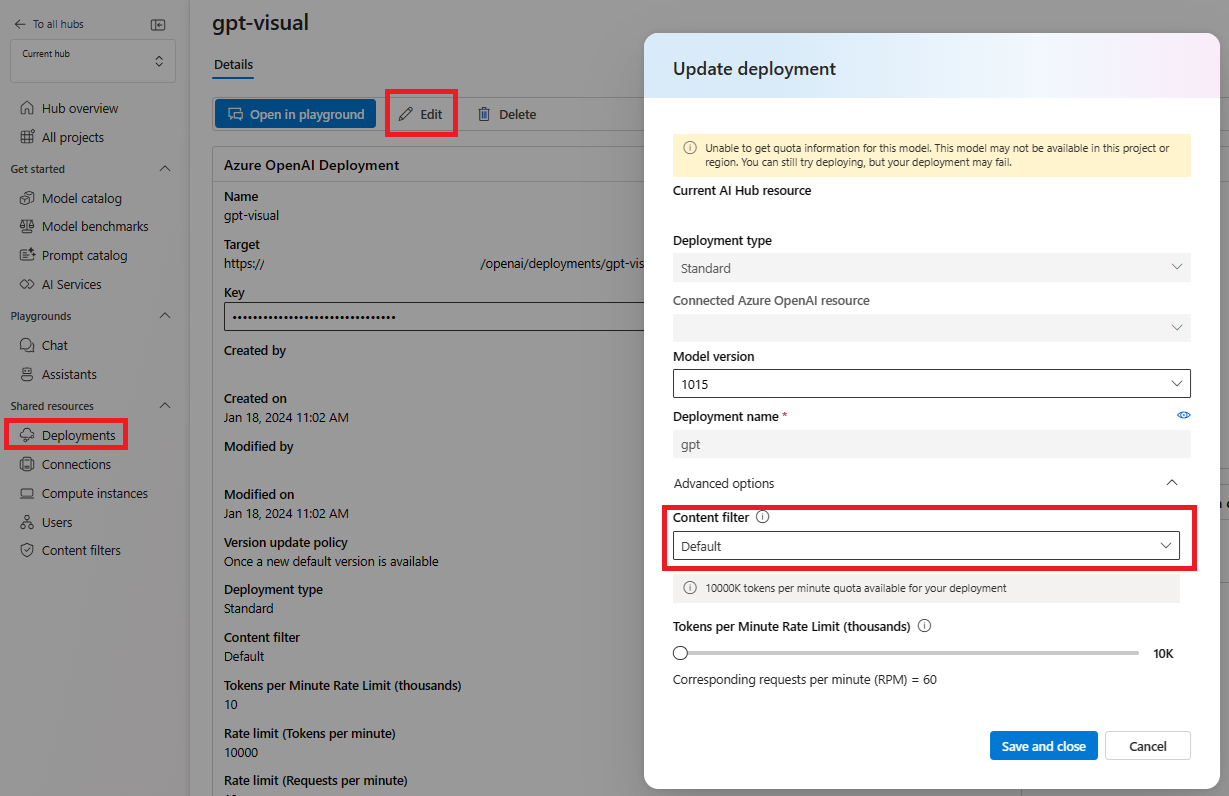


現在,您可以至遊樂場測試內容篩選是否如預期般運作。
類別
| 類別 | 描述 |
|---|---|
| 仇恨 | 仇恨類別描述語言攻擊或使用,其包括基於群體的某些差異特性,包括但不限於種族、族群、國籍、性別認同和表現、性取向、宗教、移民身分、能力狀態、個人外表和體型,而產生與個人或身分群體有關的貶抑或歧視性語言。 |
| 色情 | 色情類別描述與生理器官和生殖器、情愛關係、以性愛或親暱詞彙描繪行為、身體性行為相關的語言,包括描繪為違反個人意願的侵犯或強迫性暴力行為、賣淫、色情片和虐待。 |
| 暴力 | 暴力類別描述與意圖損害、傷害、毀壞或殺害某人或某物;描述武器等身體動作相關的語言。 |
| 自殘 | 自殘類別描述的語言與身體動作相關,其意圖為刻意損害、傷害或毀壞某人自己的身體或自殺。 |
嚴重性層級
| 類別 | 描述 |
|---|---|
| Safe | 內容可能與暴力、自殘、色情或仇恨類別相關,但詞彙用於一般、新聞、科學、醫學和類似的專業內容,適合大多數受眾。 |
| 低 | 表達偏見、評判性或固執觀點的內容,包括使用冒犯性的語言、刻板印象、探索虛構世界的使用案例 (例如遊戲、文學),以及低強度的描寫。 |
| 中 | 針對特定身分群體使用攻擊性、侮辱性、嘲笑、恐嚇或貶低性語言的內容,包括以中等強度描寫尋求和執行有害指示、幻想、頌揚、宣揚傷害。 |
| 高 | 顯示明確和嚴重有害指示、動作、損害或虐待的內容,包括贊同、頌揚或宣揚嚴重有害行為、極端或非法形式的傷害、激進或未經同意的權力交換或濫用。 |
可設定性 (預覽)
GPT 模型系列的預設內容篩選組態會設定為針對所有四個內容傷害類別 (仇恨、暴力、性及自我傷害) 的中等嚴重性閾值進行篩選,並同時適用於提示 (文字、多強制回應文字/影像) 和完成 (文字)。 這表示偵測到嚴重性層級為中或高的內容將被篩選,而偵測到嚴重性層級為低的內容則不會被篩選。 針對 DALL-E,預設嚴重性閾值會針對提示 (文字) 和完成 (影像) 設定為低,因此在嚴重性層級低、中或高時偵測到的內容會經過篩選。
可設定性功能允許客戶分別調整提示和完成的設定,以篩選不同嚴重性層級的每個內容類別之內容,如下表所示:
| 篩選的嚴重性 | 可針對提示設定 | 可針對完成設定 | Description |
|---|---|---|---|
| 低、中等、高 | Yes | Yes | 最嚴格的篩選設定。 偵測到的嚴重性層級為低、中和高的內容將被篩選。 |
| 中、高 | Yes | Yes | 偵測到嚴重性層級為低的內容不會被篩選,中和高的內容將被篩選。 |
| 高 | Yes | Yes | 偵測到嚴重性層級為低和中的內容不會被篩選。 僅篩選嚴重性層級為高的內容。 需要核准1。 |
| 沒有篩選 | 如果已核准1 | 如果已核准1 | 無論偵測到的嚴重性層級如何,都不會篩選任何內容。 需要核准1。 |
1 針對 Azure OpenAI 模型,只有獲核准內容篩選的客戶才有完整的內容篩選控制,包括將內容篩選設定為僅高嚴重性層級或關閉內容篩選。 透過此表單申請已修改的內容篩選:Azure OpenAI 有限存取權檢閱:修改的內容篩選和濫用監視 (microsoft.com) (英文)
客戶須負責確保整合 Azure OpenAI 的應用程式符合規範。
其他輸入篩選器
您也可以為生成式 AI 案例啟用特殊篩選:
- 越獄攻擊:越獄攻擊是使用者提示,其設計目的是要引發產生 AI 模型,以展示其定型的行為,以避免或打破系統訊息中設定的規則。
- 間接攻擊:間接攻擊又稱為間接提示攻擊或跨網域提示插入攻擊,是潛在的弱點,其中第三方將惡意指示放在生成式 AI 系統可以存取和處理的文件內。
其他輸出篩選器
您也可以開啟下列特殊輸出篩選:
- 受保護的文字內容:受保護的內容文字描述已知的文字內容 (例如歌曲歌詞、文章、食譜和選取的 Web 內容),這些內容可由大型語言模型輸出。
- 程式碼的受保護資料:受保護的材料程式碼描述與公用存放庫的一組原始程式碼相符的原始程式碼,這些原始程式碼可由大型語言模型輸出,而不需要適當的來源存放庫引文。
- 基礎性:地面偵測篩選器會偵測大型語言模型 (LLM) 的文字回應是否以使用者所提供的來源資料為根據。
下一步
- 深入了解驅動 Azure OpenAI 的基礎模型。
- Azure AI Studio 內容篩選是由 Azure AI 內容安全所提供。
- 深入了解以了解並降低與應用程式相關聯的風險:Azure OpenAI 模型的負責任 AI 做法概觀。