Azure Cosmos DB Java SDK v4 的效能秘訣
適用於:![]() NoSQL
NoSQL
重要
本文提供的效能秘訣僅適用於 Azure Cosmos DB JAVA SDK v4。 如需更多資訊,請參閱 Azure Cosmos DB Java SDK v4 版本資訊、Maven 存放庫和 Azure Cosmos DB Java SDK v4 疑難排解指南。 如果您目前使用的版本比 v4 舊,請參閱遷移至 Azure Cosmos DB Java SDK v4 指南,以取得升級至 v4 的協助。
Azure Cosmos DB 是一個既快速又彈性的分散式資料庫,可在獲得延遲與輸送量保證的情況下順暢地調整。 使用 Azure Cosmos DB 時,您不必進行主要的架構變更,或是撰寫複雜的程式碼來調整您的資料庫。 相應增加和減少就像進行單一 API 呼叫或 SDK 方法呼叫一樣簡單。 不過,由於 Azure Cosmos DB 是透過網路呼叫存取,所以您可以在使用 Azure Cosmos DB Java SDK v4 時,進行用戶端最佳化以達到最高效能。
因此,如果您是問:「如何改善資料庫效能?」,請考慮下列選項:
網路
可能的話,請將任何呼叫 Azure Cosmos DB 的應用程式放在與 Azure Cosmos DB 資料庫相同的區域中。 以約略的比較來說,在相同區域內對 Azure Cosmos DB 進行的呼叫會在 1-2 毫秒內完成,但美國西岸和美國東岸之間的延遲則會 >50 毫秒。 視要求所採用的路由而定,各項要求從用戶端傳遞至 Azure 資料中心界限時的這類延遲可能有所不同。 確保呼叫端應用程式與佈建的 Azure Cosmos DB 端點位於相同的 Azure 區域中,將可能達到最低的延遲。 如需可用區域的清單,請參閱 Azure 區域。
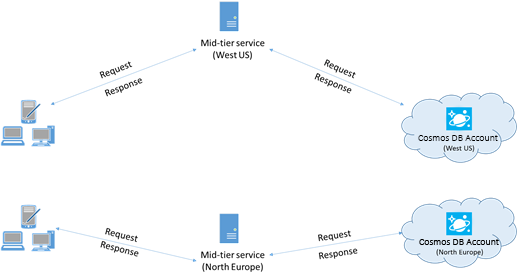
與多重區域 Azure Cosmos DB 帳戶互動的應用程式必須設定慣用位置,以確保要求會進入共置區域。
啟用加速網路以降低延遲和 CPU 抖動
強烈建議遵循指示,在 Windows (選取以取得指示) 或 Linux (選取以取得指示) Azure VM 中啟用加速網路,藉由降低延遲和 CPU 抖動來將效能最大化。
如果沒有加速網路,在 Azure VM 和其他 Azure 資源之間傳輸的 IO,可能反而會透過位於 VM 和其網路卡之間的主機和虛擬交換器來路由傳送。 將主機和虛擬交換器內嵌在資料路徑中,不僅會增加通道的延遲和抖動,還會佔用 VM 的 CPU 週期。 使用加速網路時,VM 會直接與 NIC 相連,而不需要媒介。 所有網路原則詳細資料都會在 NIC 的硬體中處理,略過主機和虛擬交換器。 一般來說可以預期降低延遲並提高輸送量,而且啟用加速網路時,延遲情形會更為一致,CPU 使用率也會降低。
限制:VM OS 必須支援加速網路,而且只有在 VM 停止並解除配置時,才能啟用加速網路。 無法使用 Azure Resource Manager 部署 VM。 App Service 未啟用加速網路。
如需詳細資訊,請參閱 Windows 和 Linux 指示。
高可用性
如需在 Azure Cosmos DB 中設定高可用性的一般指導,請參閱 Azure Cosmos DB 中的高可用性。
除了資料庫平台中良好的基礎設定之外,還有可在 JAVA SDK 本身實作的特定技術,這有助於中斷案例。 兩個值得注意的策略是閾值型可用性策略和分割區層級斷路器。
這些技術提供進階機制來解決特定延遲和可用性挑戰,超越 SDK 預設內建的跨區域重試功能。 透過主動管理要求和分割區層級的潛在問題,這些策略可以大幅增強應用程式的復原能力和效能,特別是在高負載或降級的情況下。
閾值型可用性策略
閾值型可用性策略可以藉由將平行讀取要求傳送至次要區域,並接受最快的回應,從而改善尾端延遲和可用性。 這種方法可以大幅降低區域中斷或高延遲情況對應用程式效能的影響。 此外,可以運用主動式連線管理,藉由將目前讀取區域和慣用遠端區域的連線和快取熱身來進一步提升效能。
設定範例:
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("sample_region_1", "sample_region_2"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
運作方式:
初始要求:在 T1 時,會向主要區域提出讀取要求 (例如美國東部)。 SDK 會等候最多 500 毫秒的回應 (
threshold值)。第二個要求:如果主要區域在 500 毫秒內沒有回應,則會將平行要求傳送至下一個慣用區域 (例如美國東部 2)。
第三個要求:如果主要區域和次要區域在 600 毫秒 (500 毫秒 + 100 毫秒,即
thresholdStep值) 內都沒有回應,則 SDK 會將另一個平行要求傳送至第三個慣用區域 (例如美國西部)。最快回應優先:無論哪個區域先回應都會接受該回應,並忽略其他平行要求。
主動式連線管理可協助在慣用區域中為容器提供連線和快取,減少故障轉移案例的冷啟動延遲,或在多區域設定中寫入。
此策略可在特定區域緩慢或暫時無法使用的情況下大幅改善延遲,但在需要平行跨區域要求時,可能會產生更多要求單位的成本。
注意
如果第一個慣用區域傳回非暫時性錯誤狀態代碼 (例如找不到文件、授權錯誤、衝突等),作業本身將會都未檢錯,因為可用性策略在此案例中沒有任何好處。
分割區層級斷路器
分割區層級斷路器藉由追蹤對狀況不良實體分割區的要求並尋找最短路徑,以增強尾端延遲和寫入可用性。 它可藉由避免已知有問題的分割區,並將要求重新導向至狀況更良好的區域,藉以改善效能。
設定範例:
若要啟用分割區層級斷路器:
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
若要設定檢查無法使用區域的背景處理頻率:
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
若要設定分割區可能維持無法使用的持續時間:
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
運作方式:
追蹤失敗:SDK 會追蹤特定區域中個別分割區的終端機失敗 (例如 503s、500s、逾時)。
標示為無法使用:如果區域中的分割區超過設定的失敗閾值,則會標示為「無法使用」。此分割區的後續要求會尋找最短路徑,並重新導向至其他狀況較良好的區域。
自動化復原:背景處理會定期檢查無法使用的分割區。 在特定持續時間之後,這些分割區會暫定標示為「HealthyTentative」,並接受測試要求來驗證復原。
健康情況升階/降級:根據這些測試要求的成功或失敗,分割區的狀態會升階回「狀況良好」,或再次降級為「無法使用」。
此機制有助於持續監視分割區健康情況,並確保要求會以最低的延遲和最大的可用性提供,而不會因為有問題的分割區而陷入停滯。
注意
斷路器只適用於多重區域寫入帳戶,就像分割區標示為 Unavailable 時,讀取和寫入都會移至下一個慣用的區域。 這是為了避免從相同用戶端執行個體提供來自不同區域的讀取和寫入,因為這會是反模式。
重要
您必須使用 JAVA SDK 4.63.0 版或更新版本,才能啟動分割區層級斷路器。
比較可用性最佳化
閾值型可用性策略:
- 優點:藉由將平行讀取要求傳送至次要區域來減少尾端延遲,並藉由預先處理會導致網路逾時的要求來提高可用性。
- 取捨:與斷路器相比,由於額外的平行跨區域要求 (儘管僅在違反閾值期間),因此會產生額外的 RU (要求單位) 成本。
- 使用案例:最適合大量讀取工作負載,其中降低延遲十分重要,而一些額外的成本 (就 RU 費用和用戶端 CPU 壓力而言) 是可接受的。 如果選擇使用非等冪寫入重試原則,且帳戶具有多重區域寫入,則寫入作業也可以受益。
分割區層級斷路器:
- 優點:藉由避免狀況不良的分割區來改善可用性和延遲,確保要求會路由傳送至狀況更良好的區域。
- 取捨:不會產生額外的 RU 成本,但仍可能因會導致網路逾時的要求而引起一些初始的可用性損失。
- 使用案例:適用於一致效能很重要的大量寫入或混合工作負載,尤其是在處理可能間歇性變成狀況不良的分割區時。
這兩種策略可以一起使用,以增強讀寫可用性並減少尾端延遲。 分割區層級斷路器可以處理各種暫時性的失效情況,包括那些可能導致複本執行緩慢的情況,而無需執行平行要求。 此外,如果額外的 RU 成本可以接受,則新增閾值型可用性策略會進一步將尾端延遲降到最低,並消除可用性損失。
藉由實作這些策略,開發人員可以確保其應用程式保持復原能力、維持高效能,並在區域性中斷或高延遲狀況期間提供更好的使用者體驗。
區域範圍工作階段一致性
概觀
如需一般一致性設定的詳細資訊,請參閱 Azure Cosmos DB 中的一致性層級。 JAVA SDK 藉由允許區域範圍,為多區域寫入帳戶的工作階段一致性提供最佳化。 如此可透過將用戶端重試降次數至最低,藉此降低跨區域複寫延遲,從而提升效能。 這是藉由在區域層級 (而不是全域) 管理工作階段權杖來達成。 如果您應用程式中的一致性可以限定範圍為較少的區域,則藉由實作區域範圍的工作階段一致性,您可以透過將跨區域複寫延遲和重試次數降至最低,以達到多寫入帳戶中讀取和寫入作業的更佳效能和可靠性。
福利
- 降低延遲:藉由將工作階段權杖驗證當地語系化為區域層級,降低成本高昂的跨區域重試機會。
- 增強的效能:將區域容錯移轉和複寫延遲的影響降到最低,提供較高的讀取/寫入一致性和較低的 CPU 使用率。
- 最佳化資源使用率:藉由限制重試和跨區域呼叫的需求,減少用戶端應用程式的 CPU 和網路額外負荷,進而最佳化資源使用狀況。
- 高可用性:藉由維護區域範圍的工作階段權杖,即使某些區域遇到較高的延遲或暫時失敗,應用程式仍可繼續順暢地運作。
- 一致性保證:確保工作階段一致性 (讀取您的寫入、單純讀取) 保證更可靠地符合,而不需要重試。
- 成本效益:減少跨區域呼叫的數目,進而降低與區域之間資料傳輸相關聯的成本。
- 延展性:可讓應用程式藉由減少與維護全域工作階段權杖相關聯的爭用和額外負荷,特別是在多區域設定中,以更有效率地調整規模。
取捨
- 增加記憶體使用量:Bloom 篩選和區域特定的工作階段權杖儲存體需要額外的記憶體,這可能是資源有限應用程式的考量。
- 設定複雜度:微調 Bloom 篩選的預期插入計數和誤判率,會為設定程序增加一層複雜性。
- 誤判可能性:雖然 Bloom 篩選會將跨區域重試次數降至最低,儘管可以控制速率,但仍有些微可能誤判對工作階段權杖驗證的影響。 誤判表示全域工作階段權杖已解決,因此,如果本地區域未趕上此全域工作階段,就會增加跨區域重試的機會。 即使在出現誤判的情況下也會符合工作階段保證。
- 適用性:這項功能對邏輯分割區高基數和定期重新啟動的應用程式最有利。 邏輯分割區較少或不常重新啟動的應用程式可能不會看到顯著的優點。
運作方式
設定工作階段權杖
- 要求完成:完成要求之後,SDK 會擷取工作階段權杖,並將其與區域和分割區索引鍵產生關聯。
- 區域層級記憶體:工作階段權杖會儲存在巢狀
ConcurrentHashMap結構中,以維護分割區索引鍵範圍與區域層級進度之間的對應。 - Bloom 篩選:Bloom 篩選條件會追蹤每個邏輯分割區已存取哪些區域,以協助當地語系化工作階段權杖驗證。
解析工作階段權杖
- 要求初始化:傳送要求之前,SDK 會嘗試解析適當區域的工作階段權杖。
- 權杖檢查:權杖會針對區域特定資料進行檢查,以確保要求會路由傳送至最新的複本。
- 重試邏輯:如果未在目前區域內驗證工作階段權杖,SDK 會使用其他區域重試,但考慮到本地化的儲存體,這會較不頻繁。
使用 SDK
以下說明如何使用區域範圍的工作階段一致性來初始化 CosmosClient:
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
啟用區域範圍的工作階段一致性
若要在應用程式中啟用區域範圍的工作階段擷取,請設定下列系統屬性:
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
設定 Bloom 篩選
藉由設定 Bloom 篩選的預期插入和誤判率來微調效能:
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
記憶體含意
以下是內部工作階段容器 (由 SDK 管理) 的保留大小 (物件大小,以及它所依賴項目的大小),並將不同的預期插入到 Bloom 篩選中。
| 預期的插入 | 誤判率 | 保留大小 |
|---|---|---|
| 10, 000 | 0.001 | 21 KB |
| 100, 000 | 0.001 | 183 KB |
| 100 萬 | 0.001 | 1.8 MB |
| 1000 萬 | 0.001 | 17.9 MB |
| 1 億 | 0.001 | 179 MB |
| 10 億 | 0.001 | 1.8 GB |
重要
您必須使用 JAVA SDK 4.60.0 版或更新版本,才能啟用區域範圍的工作階段一致性。
調整直接和閘道連線設定
若要最佳化直接和閘道模式連線設定,請參閱如何調整 JAVA SDK v4 的連線設定。
SDK 使用方式
- 安裝最新的 SDK
Azure Cosmos DB SDK 會持續改善以提供最佳效能。 若要判斷最新的 SDK 改進功能,請造訪 Azure Cosmos DB SDK。
每個 Azure Cosmos DB 用戶端執行個體都是安全執行緒,並且會有效率地執行連線管理和位址快取處理。 若要藉由 Azure Cosmos DB 用戶端獲得有效率的連線管理和更佳的效能,建議在應用程式存留期內,使用單一 Azure Cosmos DB 用戶端的執行個體。
建立 CosmosClient 時,如果未明確設定為工作階段,則會使用預設的一致性。 如果您的應用程式邏輯不需要工作階段一致性,請將 [一致性] 設定為 [最終]。 注意:建議您在採用 Azure Cosmos DB 變更摘要處理器的應用程式中,至少使用「工作階段」一致性。
- 使用非同步 API 盡可能利用佈建的輸送量
Azure Cosmos DB JAVA SDK v4 會組合兩個 API,也就是同步和非同步。 大致來說,非同步 API 會實作 SDK 功能,而同步 API 則是對非同步 API 發出封鎖呼叫的精簡包裝函式。 這與舊版 Azure Cosmos DB 非同步 JAVA SDK v2 (僅限非同步) 和舊版 Azure Cosmos DB 同步 JAVA SDK v2 (僅限同步處理,並具有獨立的實作方式) 相反。
在用戶端初始化期間要決定所選擇的 API;CosmosAsyncClient 支援非同步 API,而 CosmosClient 支援同步 API。
非同步 API 會實作非封鎖 IO,而且如果目標是在對 Azure Cosmos DB 發出要求時,要達到最大的輸送量,這是最佳選擇。
如果想要或需要 API 封鎖對每個要求的回應,或如果同步作業是應用程式中的主要架構,則使用同步 API 會是正確選擇。 舉例來說,如果輸送量並非重點,在微服務應用程式中將資料保存到 Azure Cosmos DB 時,建議使用同步 API。
請注意,同步 API 輸送量會隨著要求的回應時間增加而降低,而非同步 API 會使硬體的所有頻寬達到飽和。
您使用同步 API 時,可透過地理共置獲得更高且更一致的輸送量 (請參閱為了效能在相同 Azure 區域中共置用戶端),但仍不應超過非同步 API 可達成的輸送量。
某些使用者可能也不太熟悉 Project Reactor,這是用來實作 Azure Cosmos DB JAVA SDK v4 Async API 的回應式串流架構。 如果對此有所顧慮,建議參閱我們的簡介反應器模式指南 (英文),然後查看回應式程式設計簡介 (英文),提高自己的熟悉度。 如果您已使用 Azure Cosmos DB 搭配非同步介面,而且您使用的 SDK 是 Azure Cosmos DB 非同步 JAVA SDK v2,則您可能熟知 ReactiveX/RxJava,但不確定 Project Reactor 有哪些變更。 在此情況下,請參閱我們的反應器與RxJava 指南 (英文) 加深了解。
下列程式碼片段示範了如何分別針對非同步 API 或同步 API 作業初始化 Azure Cosmos DB 用戶端:
Java SDK V4 (Maven com.azure::azure-cosmos) 非同步 API
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- 擴增用戶端工作負載
如果您是以高輸送量層級進行測試,用戶端應用程式可能會成為瓶頸,因為電腦對 CPU 或網路的使用率將達到上限。 如果到了這一刻,您可以將用戶端應用程式向外延展至多部伺服器,以繼續將 Azure Cosmos DB 帳戶再往前推進一步。
根據理想的經驗法則,建議不要超過任何指定伺服器上 >50% 的 CPU 使用率,以保持低延遲。
- 使用適當排程器 (避免竊取事件迴圈 IO Netty 執行緒)
Azure Cosmos DB JAVA SDK 的非同步功能是以 netty 非封鎖 IO 為基礎。 SDK 會使用固定數目的 IO netty 事件迴圈執行緒 (和您電腦所擁有的 CPU 核心數一樣多) 來執行 IO 作業。 API 所傳回的 Flux 會在其中一個共用的 IO 事件迴圈 netty 執行緒上發出結果。 因此,請切勿封鎖共用的 IO 事件迴圈 netty 執行緒。 若執行 CPU 密集工作或封鎖 IO 事件迴圈 netty 執行緒上的作業,可能會導致鎖死或大幅降低 SDK 輸送量。
例如,下列程式碼會在事件迴圈 IO netty 執行緒上執行 CPU 密集工作:
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
收到結果之後,您應該避免在事件迴圈 IO netty 執行緒上對結果執行任何 CPU 密集工作。 您可以改為提供您自己的排程器,以提供自己的執行緒來執行工作,如下所示 (需要 import reactor.core.scheduler.Schedulers)。
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
根據您的工作類型,您應該將適當的現有 Reactor 排程器用於您的工作。 請閱讀這裡 Schedulers。
若要進一步瞭解 Project Reactor 的執行緒和排程模型,請參閱 Project Reactor 的這篇部落格文章。
如需 Azure Cosmos DB JAVA SDK v4 的詳細資訊,請參閱 GitHub 上 Azure SDK for Java 單一存放庫中的 Azure Cosmos DB 目錄。
- 將應用程式中的記錄設定最佳化
基於各種原因,您應該在產生高要求輸送量的執行緒中新增記錄。 如果您的目標是使用此執行緒產生的要求,使容器的佈建輸送量完全飽和,記錄最佳化即可大幅提升效能。
- 設定非同步記錄器
同步記錄器的延遲一定會影響到產生要求的執行緒的整體延遲計算。 建議使用非同步記錄器 (例如 log4j2),從高效能應用程式執行緒將將記錄作業的額外負荷分離出去。
- 停用 netty 的記錄
Netty 程式庫記錄通訊頻繁,而且必須加以關閉 (隱藏組態中的登入可能不夠) 以避免額外的 CPU 成本。 如果您不是在偵錯模式中,請停用 netty 全部的記錄。 因此,如果您要使用 log4j 來移除 netty 中的 org.apache.log4j.Category.callAppenders() 所產生的額外 CPU 成本,請將下列行新增至程式碼基底:
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- OS 開啟檔案資源限制
某些 Linux 系統 (例如 Red Hat) 有開啟檔案數目的上限,因此有連線總數的上限。 執行下列命令來檢視目前的限制:
ulimit -a
開啟檔案 (nofile) 的數目必須夠大,才能有足夠空間供您設定的連線集區大小和 OS 的其他開啟檔案使用。 您可以進行修改,以允許較大的連線集區大小。
開啟 limits.conf 檔案:
vim /etc/security/limits.conf
新增/修改下列幾行:
* - nofile 100000
- 在點寫入中指定分割區索引鍵
若要改善點寫入的效能,請在點寫入 API 呼叫中指定項目分割區索引鍵,如下所示:
Java SDK V4 (Maven com.azure::azure-cosmos) 非同步 API
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
而不只是提供項目執行個體,如下所示:
Java SDK V4 (Maven com.azure::azure-cosmos) 非同步 API
asyncContainer.createItem(item).block();
後者受到支援,但會導致應用程式增加延遲;SDK 必須剖析項目,並將分割區索引鍵解壓縮。
查詢作業
如需查詢作業,請參閱查詢的效能秘訣。
編製索引原則
- 將未使用的路徑排除於索引編製外以加快寫入速度
Azure Cosmos DB 的編製索引原則可讓您使用編製索引路徑 (setIncludedPaths 和 setExcludedPaths),指定要在編製索引中包含或排除的文件路徑。 在事先知道查詢模式的案例中,使用檢索路徑可改善寫入效能並降低索引儲存空間,因為檢索成本與檢索的唯一路徑數目直接相互關聯。 例如,下列程式碼示範如何使用 "*" 萬用字元,將文件的整個區段 (亦稱為樹狀子目錄) 從索引編製作業中併入和排除。
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
如需詳細資訊,請參閱 Azure Cosmos DB 索引編製原則。
輸送量
- 測量和調整較低的要求單位/秒使用量
Azure Cosmos DB 提供許多的資料庫作業,包括使用 UDF、預存程序和觸發程序進行關聯式和階層式查詢,而這些作業全都是對資料庫集合內的文件來進行。 與上述各項作業相關聯的成本,會因為完成作業所需的 CPU、IO 和記憶體而不同。 您不需要考慮和管理硬體資源,您可以將要求單位 (RU) 想成是執行各種資料庫作業以及服務應用程式要求時所需的資源數量。
輸送量是根據為每個容器所設定的要求單位數量來佈建。 要求單位消耗量是以每秒的速率來計算。 如果應用程式的速率超過為其容器佈建的要求單位速率,便會受到限制,直到該速率降到容器的佈建層級以下。 如果您的應用程式需要較高的輸送量,您可以藉由佈建其他的要求單位來增加輸送量。
查詢的複雜性會影響針對作業所耗用的要求單位數量。 述詞數目、述詞性質、UDF 數目,以及來源資料集的大小,全都會影響查詢作業的成本。
若要測量任何作業 (建立、更新或刪除) 的額外負荷,請檢查 x-ms-request-charge 標頭,來測量這些作業所耗用的要求單位數量。 您也可以查看 ResourceResponse<T> 或 FeedResponse<T> 中的對等 RequestCharge 屬性。
Java SDK V4 (Maven com.azure::azure-cosmos) 非同步 API
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
在此標頭中傳回的要求費用是佈建輸送量的一小部分。 例如,如果您佈建了 2000 RU/秒,且前述查詢傳回 1,000 份 1KB 文件,則作業成本會是 1000。 因此在一秒內,伺服器在對後續要求進行速率限制前,只會接受兩個這類要求。 如需詳細資訊,請參閱要求單位和要求單位計算機。
- 處理速率限制/要求速率太大
當用戶端嘗試超過帳戶保留的輸送量時,伺服器的效能不會降低,而且不會使用超過保留層級的輸送量容量。 伺服器將預先使用 RequestRateTooLarge (HTTP 狀態碼 429) 來結束要求,並傳回 x-ms-retry-after-ms 標頭,以指出使用者重試要求之前必須等候的時間量 (毫秒)。
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK 全都隱含地攔截這個回應,採用伺服器指定的 retry-after 標頭,並重試此要求。 除非有多個用戶端同時存取您的帳戶,否則下次重試將會成功。
如果您有多個用戶端都以高於要求速率的方式累積運作,則用戶端在內部設定為 9 的預設重試計數可能會不敷使用;在此情況下,用戶端會擲回 CosmosClientException (狀態碼 429) 到應用程式。 預設重試計數可以使用 ThrottlingRetryOptions 執行個體上的 setMaxRetryAttemptsOnThrottledRequests() 進行變更。 根據預設,如果要求繼續以高於要求速率的方式運作,則會在 30 秒的累計等候時間後傳回 CosmosClientException (狀態碼 429)。 即使目前的重試計數小於最大重試計數 (預設值 9 或使用者定義的值),也會發生這種情況。
雖然自動重試行為有助於改善大部分應用程式的恢復功能和可用性,但是在進行效能基準測試時可能會有所歧異 (尤其是在測量延遲時)。 如果實驗達到伺服器節流並導致用戶端 SDK 以無訊息模式重試,則用戶端觀察到的延遲將會突然增加。 若要避免效能實驗期間的延遲尖峰,測量每個作業所傳回的費用,並確保要求是以低於保留要求速率的方式運作。 如需詳細資訊,請參閱 要求單位。
- 輸送量較高之少量文件的設計
指定之作業的要求費用 (要求處理成本) 與文件大小直接相互關聯。 大型文件的作業成本高於小型文件的作業成本。 在理想情況下,架構應用程式和工作流程時,請讓項目大小約為 1KB 或類似的順序或大小。 對於注重延遲的應用程式,請避免大型項目,因為好幾 MB 的文件會造成應用程式變慢。
下一步
若要深入了解如何針對規模和高效能設計您的應用程式,請參閱 Azure Cosmos DB 的資料分割與調整規模。
正在嘗試為遷移至 Azure Cosmos DB 進行容量規劃嗎? 您可以使用現有資料庫叢集的相關資訊進行容量規劃。
- 如果您知道現有資料庫叢集中的虛擬核心和伺服器數目,請參閱使用虛擬核心或 vCPU 來估計要求單位
- 如果您知道目前資料庫工作負載的一般要求率,請參閱使用 Azure Cosmos DB 容量規劃工具來估計要求單位