對應資料流程中的聯結轉換
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費啟動新的試用版!
Azure Data Factory 和 Azure Synapse Pipelines 中均可使用資料流。 本文適用於對應資料流。 如果您不熟悉轉換作業,請參閱簡介文章使用對應資料流轉換資料。
使用聯結轉換,在對應資料流程中結合來自兩個來源或資料流中的資料。 輸出資料流會包含這兩個來源中根據聯結條件進行比對的所有資料行。
聯結類型
對應資料流程目前支援五種不同的聯結類型。
內部聯結
內部聯結只會輸出在兩個資料表中具有相符值的資料列。
左方外部
左方外部聯結會傳回左方資料流中的所有資料列,以及右方資料流中的相符記錄。 如果左方資料流中的資料列沒有相符項,則右方資料流中的輸出資料行會設定為 NULL。 輸出將會是內部聯結所傳回的資料列,加上來自左方資料流的不相符資料列。
注意
資料流程所使用的 Spark 引擎偶爾由於聯結條件中可能的笛卡兒乘積而失敗。 如果發生這種情況,您可以切換到自訂交叉聯結,並手動輸入您的聯結條件。 這可能會導致您的資料流效能變慢,因為執行引擎可能需要計算關聯性兩側的所有資料列,然後篩選資料列。
右方外部
右方外部聯結會傳回右方資料流中的所有資料列,以及左方資料流中的相符記錄。 如果右方資料流中的資料列沒有相符項,則左方資料流中的輸出資料行會設定為 NULL。 輸出將會是內部聯結所傳回的資料列,加上來自右方資料流的不相符資料列。
完整外部
完整外部聯結會輸出兩側的所有資料行和資料列,對於不相符的資料行則為 NULL 值。
自訂交叉聯結
交叉聯結會根據條件輸出兩個資料流的交叉乘積。 如果您要使用不相等的條件,請指定自訂運算式做為交叉聯結條件。 輸出資料流將會是符合聯結條件的所有資料列。
您可以將這種聯結類型用於不相等聯結和 OR 條件。
如果您想要明確產生完整笛卡兒乘積,請在聯結之前於兩個獨立資料流的每一個中使用衍生的資料行轉換,以建立要比對的綜合索引鍵。 例如,在稱為 SyntheticKey 的每個資料流中,於衍生的資料行中建立新的資料行,並將它設定為等於 1。 然後,使用 a.SyntheticKey == b.SyntheticKey 做為自訂聯結運算式。
注意
請務必包含至少一個資料行,此資料行來自自訂交叉聯結中左方和右方關聯性的每一側。 執行具有靜態值的交叉聯結,而不是來自每一側的資料行,會導致整個資料集進行完整掃描,因而導致資料流的執行效能不佳。
模糊聯結
您可以開啟 [使用模糊比對] 核取方塊選項,選擇根據模糊聯結邏輯 (而不是確切的資料行值比對) 來聯結。
- 合併文字組件:使用此選項可藉由移除單字之間的空格來尋找相符項目。 例如,如果啟用此選項,Data Factory 會與 DataFactory 相符。
- 相似度分數資料行:您可以選擇將每個資料列的相符分數儲存在資料行中,方法是在此輸入新的資料行名稱來儲存該值。
- 相似度閾值:選擇介於 60 到 100 之間的值,做為所選資料行中值之間的百分比相符項目。
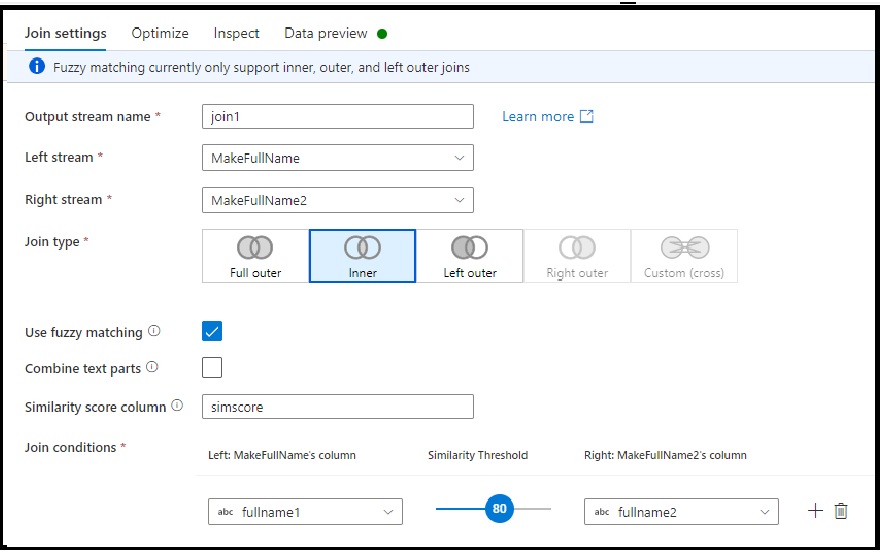
注意
模糊比對目前僅適用於字串資料行類型,以及具有內部、左外部和完整外部聯結類型。 使用模糊比對聯結時,您必須關閉廣播最佳化。
組態
- 在 [右方資料流] 下拉式清單中,選擇您要與其聯結的資料流。
- 選取您的 [聯結類型]
- 為聯結條件選擇您想要比對的索引鍵資料行。 根據預設,資料流程會在每個資料流中的資料行之間尋找等式。 若要透過計算值進行比較,請將滑鼠停留在資料行下拉式清單上,然後選取 [計算資料行]。

不相等聯結
若要在聯結條件中使用條件運算子 (例如不相等 (!=) 或大於 (>)),請變更兩個資料行之間的運算子下拉式清單。 不相等聯結需要至少廣播兩個串流的其中一個,方法為使用 [最佳化] 索引標籤中的 [固定] 廣播。

最佳化聯結效能
不同於 SSIS 之類工具中的合併聯結,聯結轉換不是必要的合併聯結作業。 聯結索引鍵不需要排序。 聯結作業是根據 Spark 中的最佳化聯結作業 (廣播或對應端聯結) 進行。

在聯結、查閱和存在轉換中,如果其中一個或兩個資料流納入背景工作角色節點記憶體中,您可以藉由啟用 [廣播] 來最佳化效能。 根據預設,Spark 引擎會自動決定是否要廣播一邊。 若要手動選擇廣播哪一邊,請選取 [固定]。
除非您的聯結遇到逾時錯誤,否則不建議透過 [關閉] 選項停用廣播。
自我聯結
若要自我聯結資料流與本身,請使用選取轉換,為現有的資料流加上別名。 按一下轉換旁邊的加號圖示,然後選取 [新增分支],以建立新的分支。 新增選取轉換,為原始資料流加上別名。 新增聯結轉換,然後選擇原始資料流做為左方資料流,然後選擇選取轉換做為右方資料流。

測試聯結條件
在偵錯模式中使用資料預覽來測試聯結轉換時,請使用小型的已知資料集。 從大型資料集中取樣資料列時,您無法預測將讀取哪些資料列和索引鍵進行測試。 結果是不具確定性的,這表示您的聯結條件可能不會傳回任何相符項。
資料流程指令碼
語法
<leftStream>, <rightStream>
join(
<conditionalExpression>,
joinType: { 'inner'> | 'outer' | 'left_outer' | 'right_outer' | 'cross' }
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <joinTransformationName>
內部聯結範例
下列範例是名為 JoinMatchedData 的聯結轉換,其會採用左方資料流 TripData 和右方資料流 TripFare。 聯結條件是運算式 hack_license == { hack_license} && TripData@medallion == TripFare@medallion && vendor_id == { vendor_id} && pickup_datetime == { pickup_datetime},如果每個資料流中的 hack_license、medallion、vendor_id和 pickup_datetime 資料行相符,就會傳回 True。 joinType 是 'inner'。 我們只會在左方資料流中啟用廣播,因此 broadcast 具有值 'left'。
在 UI 中,這項轉換看起來如下圖所示:

此轉換的資料流指令碼位於下列程式碼片段中:
TripData, TripFare
join(
hack_license == { hack_license}
&& TripData@medallion == TripFare@medallion
&& vendor_id == { vendor_id}
&& pickup_datetime == { pickup_datetime},
joinType:'inner',
broadcast: 'left'
)~> JoinMatchedData
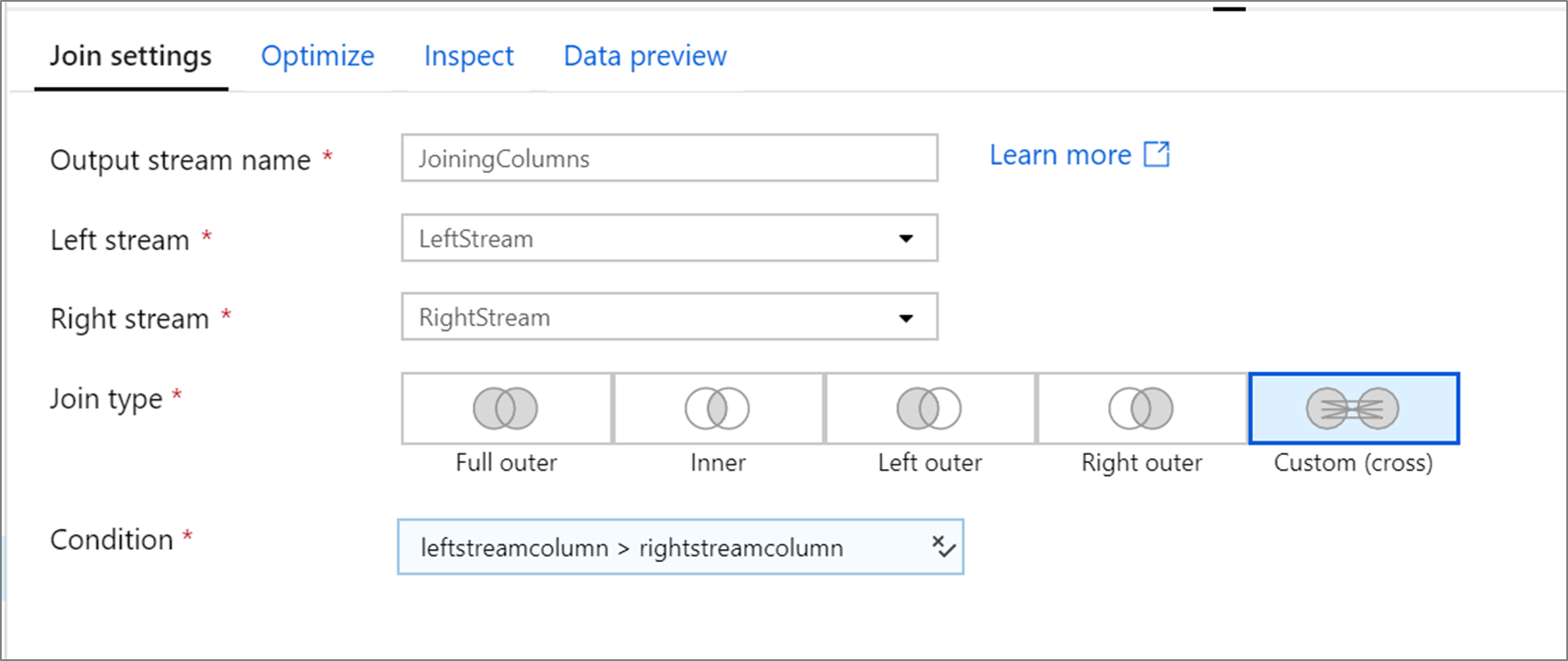
自訂交叉聯結範例
下列範例是名為 JoiningColumns 的聯結轉換,其會採用左方資料流 LeftStream 和右方資料流 RightStream。 這項轉換會採用兩個資料流,並將資料行 leftstreamcolumn 大於資料行 rightstreamcolumn 的所有資料列聯結在一起。 joinType 是 cross。 未啟用廣播,broadcast 具有值 'none'。
在 UI 中,這項轉換看起來如下圖所示:
此轉換的資料流指令碼位於下列程式碼片段中:
LeftStream, RightStream
join(
leftstreamcolumn > rightstreamcolumn,
joinType:'cross',
broadcast: 'none'
)~> JoiningColumns