適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
秘訣
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開啟新試用!
管線中的 Azure Synapse Spark 工作定義活動,會在 Azure Synapse Analytics 工作區中執行 Synapse Spark 工作定義。 這篇文章以資料轉換活動文章為基礎,提供了資料轉換及其所支援的轉換活動的一般概覽。
設定 Apache Spark 工作定義畫布
若要在管線中使用 Synapse 的 Spark 工作定義活動,請完成下列步驟:
一般設定
在 [管線活動] 窗格中搜尋 Spark 工作定義,然後將 Synapse 底下的 Spark 工作定義活動拖曳至管線畫布。
如果尚未在畫布上選取新的 Spark 工作定義活動,請加以選取。
在 [一般] 索引標籤中,輸入範例作為名稱。
(選項) 您也可以輸入描述。
逾時:活動可以執行的最長時間。 預設是 7 天,也就是允許的最長時間。 格式是 D.HH:MM:SS (日期.小時:分鐘:秒)。
重試嘗試:重新嘗試次數的上限。
重試間隔:每次重新嘗試間隔的秒數。
安全輸出:核取時,活動輸出不會擷取至記錄。
安全輸入:核取時,活動輸入不會擷取至記錄。
Azure Synapse Analytics (Artifacts) 設定
如果尚未在畫布上選取新的 Spark 工作定義活動,請加以選取。
選取 [Azure Synapse Analytics (Artifacts)] 索引標籤,選取或建立新的 Azure Synapse Analytics 連結服務,此服務將會執行 Spark 工作定義活動。
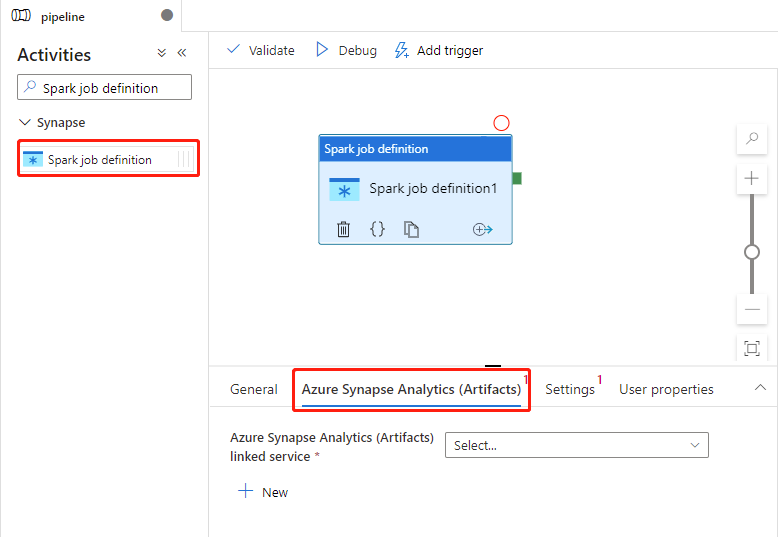
[設定] 索引標籤
如果尚未在畫布上選取新的 Spark 工作定義活動,請加以選取。
選取 [設定] 索引標籤。
展開 Spark 工作定義清單,您可以在連結的 Azure Synapse Analytics 工作區中選取現有的 Apache Spark 工作定義。
(選用) 您可以填入 Apache Spark 作業定義的資訊。 如果下列設定是空的,則會使用 Spark 工作定義本身的設定來執行;如果下列設定不是空的,這些設定將會取代 Spark 工作定義本身的設定。
財產 說明 主要定義檔 用於作業的主要檔案。 從您的儲存體中選取 PY/JAR/ZIP 檔案。 您可以選取 [上傳檔案],以將檔案上傳至儲存體帳戶。
範例:abfss://…/path/to/wordcount.jar子資料夾中的參考 從主要定義檔案的根資料夾掃描子資料夾,這些檔案將會新增為參考檔案。 系統會掃描名為 "jars"、“pyFiles”、“files” 或 “archive” 的資料夾,而且資料夾名稱會區分大小寫。 Main class name (主要類別名稱) 主要定義檔中的完整識別碼或主要類別。
範例:WordCount命令列引數 您可以按一下新增按鈕,新增命令列引數。 請注意,新增命令列引數會覆寫 Spark 工作定義所定義的命令列引數。
範例:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultApache Spark 集區 您可以從清單中選取 Apache Spark 集區。 Python 程式碼參考 主要定義檔中用於參考的其他 Python 程式碼檔案。
其支援將檔案 (.py、.py3、.zip) 傳遞至 “pyFiles” 屬性。 其會覆寫 Spark 工作定義中定義的 "pyFiles" 屬性。參考檔案 主要定義檔中用來作為參考的其他檔案。 Apache Spark 集區 您可以從清單中選取 Apache Spark 集區。 動態配置執行程式 此設定會對應到 Spark 設定中的動態配置屬性,以進行 Spark 應用程式執行程式配置。 執行程式數目下限 要在針對工作所指定 Spark 集區中配置的執行程式數目下限。 執行程式數目上限 要在針對工作所指定 Spark 集區中配置的執行程式數目上限。 驅動程式大小 在指定 Apache Spark 集區中提供給作業使用的驅動程式所能使用的核心和記憶體數目。 Spark 設定 指定下列主題中所列的 Spark 設定屬性值:Spark 設定 - 應用程式屬性。 使用者可以使用預設設定和自訂設定。 認證 Spark 作業定義中已支援使用者指派的受控識別或系統指派的受控識別。 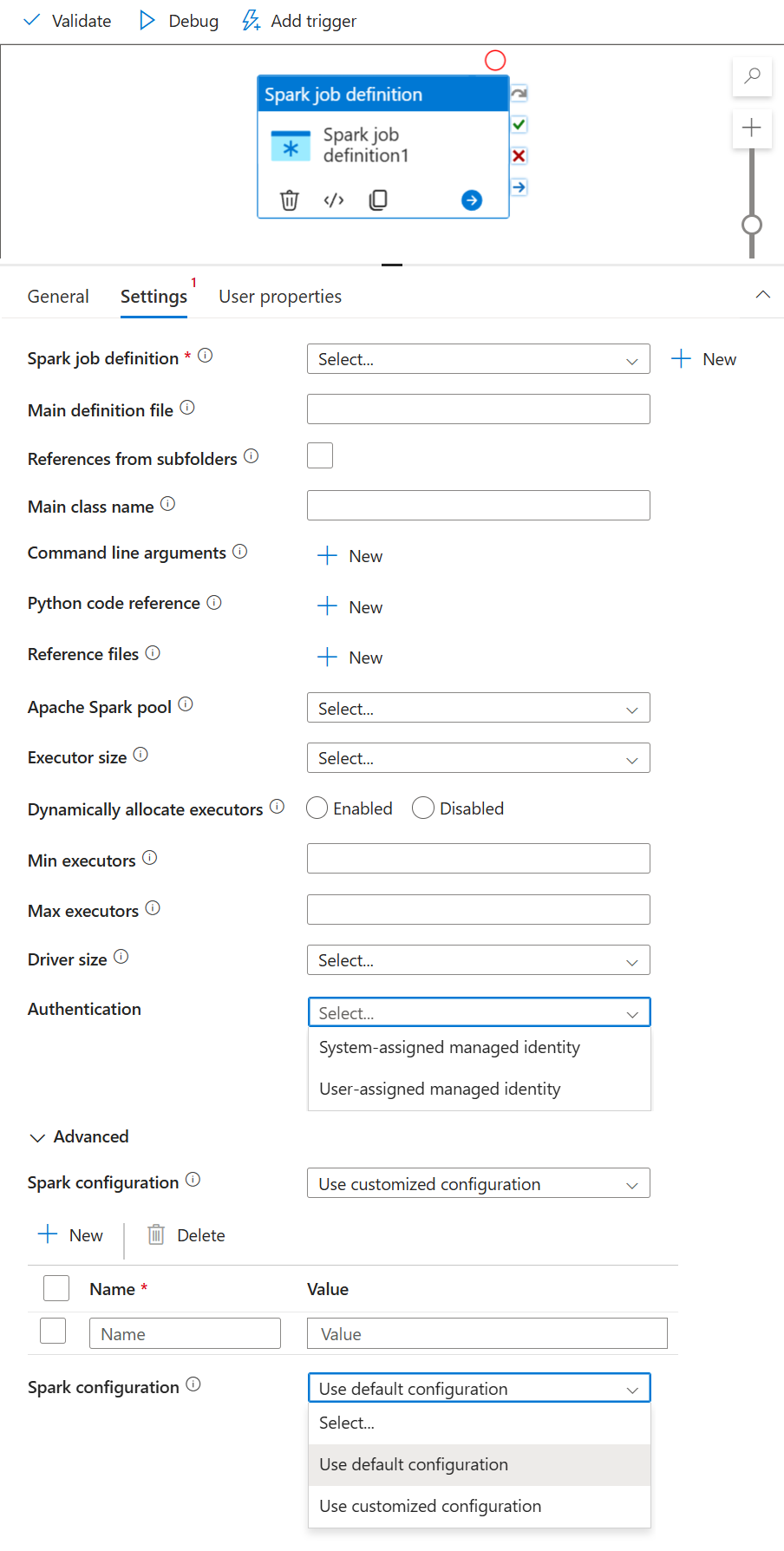
您可以按一下新增動態內容按鈕,或按快速鍵 Alt+Shift+D,新增動態內容。 在 [新增動態內容] 頁面,您可使用任何組合的運算式、函式和系統變數,新增至動態內容。
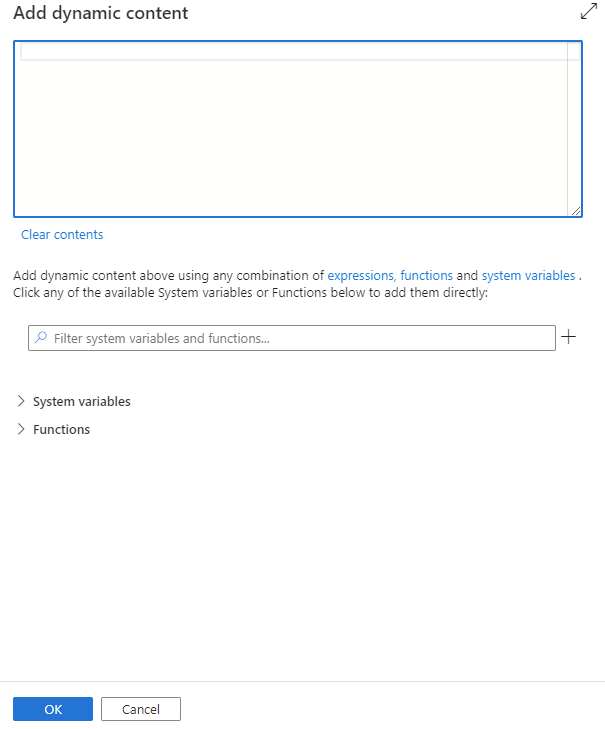
[使用者屬性] 索引標籤
您可以在此面板新增 Apache Spark 工作定義活動的屬性。

Azure Synapse Analytics Spark 工作定義活動定義
以下是 Azure Synapse Analytics Notebook 活動的範例 JSON 定義:
{
"activities": [
{
"name": "Spark job definition1",
"type": "SparkJob",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"typeProperties": {
"sparkJob": {
"referenceName": {
"value": "Spark job definition 1",
"type": "Expression"
},
"type": "SparkJobDefinitionReference"
}
},
"linkedServiceName": {
"referenceName": "AzureSynapseArtifacts1",
"type": "LinkedServiceReference"
}
}
],
}
Azure Synapse Spark 工作定義屬性
下表說明 JSON 定義中使用的 JSON 屬性:
| 財產 | 說明 | 必要 |
|---|---|---|
| 名稱 | 管線中的活動名稱。 | 是的 |
| 說明 | 說明活動用途的文字。 | 不 |
| 類型 | 針對 Azure Synapse spark 工作定義活動,活動類型為 SparkJob。 | 是的 |
請參閱 Azure Synapse Spark 工作定義活動執行歷程記錄
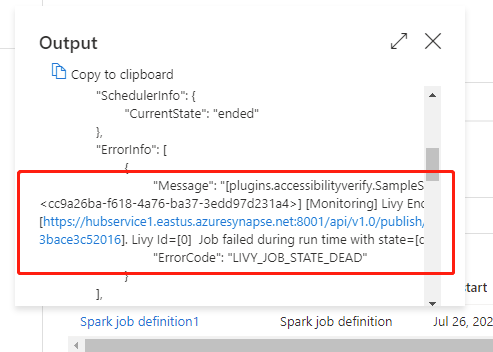
移至 [監視] 索引標籤下的 [管線執行],您會看到已觸發的管線。 開啟內含 Azure Synapse Spark 工作定義活動的管線,以查看執行歷程記錄。

您可以選取 [輸入] 或 [輸出] 按鈕,以查看筆記本活動輸入或輸出。 若管線因使用者錯誤而失敗,請選取 [輸出] 來檢查 [結果] 欄位,以查看詳細的使用者錯誤追溯。