本文涵蓋數據源、擷取、轉換、查詢和處理、服務、分析和記憶體方面的 Lakehouse 架構指引。
每個參考架構都有 11 x 17 (A3) 格式的可下載 PDF。
雖然 Databricks 上的 Lakehouse 是一個開放平臺,可與 大型合作夥伴工具生態系統整合,但參考架構僅著重於 Azure 服務和 Databricks Lakehouse。 所顯示的雲端提供者服務會選取來說明概念,而且並不詳盡。
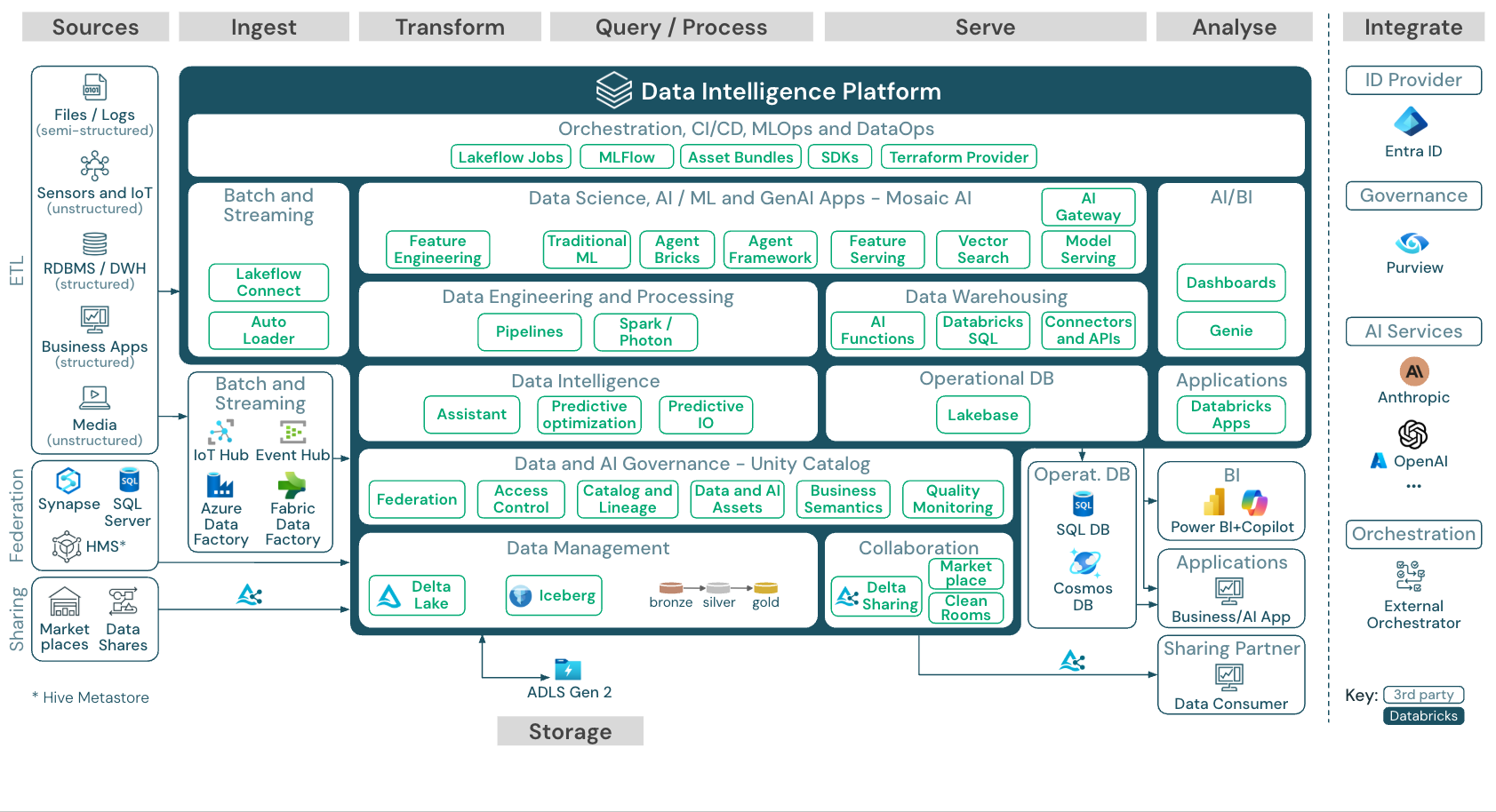
下載:Azure Databricks Lakehouse 的參考架構
Azure 參考架構顯示下列用於引入、存儲、提供和分析的 Azure 特定服務:
- 作為 Lakehouse Federation 之來源系統的 Azure Synapse 和 SQL Server
- 用於串流資料傳入的 Azure IoT 中樞和 Azure 事件中樞
- 用於批次匯入的 Azure Data Factory
- Azure Data Lake Storage Gen 2 (ADLS) 作為數據和 AI 資產的物件記憶體
- 用作操作資料庫的 Azure SQL DB 和 Azure Cosmos DB
- Azure Purview 作為企業目錄,UC 將架構和血統資訊匯出至此處。
- 用作 BI 工具的 Power BI
- Azure OpenAI 可用於模型服務,作為外部 LLM
參考架構的組織
參考架構會沿著泳道來源、攝取、轉換、查詢/處理、提供、分析和儲存進行結構化:
源
有三種方式可將外部數據整合到 Data Intelligence Platform:
- ETL:平臺可讓您與提供半結構化和非結構化數據的系統整合(例如感測器、IoT 裝置、媒體、檔案和記錄),以及關係資料庫或商務應用程式的結構化數據。
- Lakehouse 同盟:SQL 來源,例如關係資料庫,可以整合至 Lakehouse 和 Unity 目錄 ,而不需要 ETL。 在此情況下,來源系統數據會受到 Unity 目錄的控管,而查詢會向下推送至來源系統。
- 目錄同盟:Hive 中繼存放區目錄也可以透過 目錄同盟整合到 Unity 目錄,讓 Unity 目錄控制 Hive 中繼存放區中儲存的數據表。
攝取
以批次或串流方式將資料導入湖倉:
- Databricks Lakeflow Connect 提供內建連接器,可從企業應用程式和資料庫擷取。 產生的匯入管線是由 Unity 目錄所控管,並由無伺服器計算和 Lakeflow 宣告式管線驅動。
- 傳遞至雲端記憶體的檔案可以直接使用 Databricks 自動載入器來載入。
- 針對從企業應用程式批次匯入數據到 Delta Lake,Databricks Lakehouse 依賴合作夥伴提供的內嵌工具及其專用配接器來處理這些系統的記錄。
- 串流事件可以從事件串流系統,如 Kafka,直接引入,並使用 Databricks 結構化串流來處理。 串流來源可以是感測器、IoT 或 異動數據擷取 程式。
存儲
- 數據通常儲存在雲端儲存系統中,ETL 管線使用 medallion 架構以策劃的方式將數據儲存為 Delta 檔案/表格或 Apache Iceberg 表格。
轉換 和 查詢/ 進程
Databricks Lakehouse 會針對所有轉換和查詢使用其引擎 Apache Spark 和 Photon 。
Lakeflow 宣告式管線 是一種宣告式架構,可簡化和優化可靠、可維護且可測試的數據處理管線。
Databricks Data Intelligence Platform 由 Apache Spark 和 Photon 提供,可支援這兩種類型的工作負載:透過 SQL 倉儲進行 SQL 查詢,以及透過工作區 叢集的 SQL、Python 和 Scala 工作負載。
針對數據科學(ML 模型化和 Gen AI),Databricks AI 和 Machine Learning 平臺 提供 適用於 AutoML 和編碼 ML 作業的特製化 ML 運行時間。 MLflow 最能支援所有數據科學和 MLOps 工作流程。
服務
針對數據倉儲 (DWH) 和 BI 使用案例, Databricks Lakehouse 會提供 Databricks SQL、 SQL 倉儲所提供的數據倉儲,以及 無伺服器 SQL 倉儲。
針對機器學習, 馬賽克 AI 模型服務 是一種可調整、即時、企業級的模型服務功能,裝載於 Databricks 控制平面中。 馬賽克 AI 閘道 是 Databricks 的解決方案,用來控管和監視支援的生成式 AI 模型及其相關模型服務端點的存取。
作業資料庫:如外部系統等作業資料庫,可用來儲存和傳遞最終數據產品給用戶應用程式。
共同作業:商務合作夥伴可透過 Delta Sharing 安全地存取所需的數據。 根據Delta Sharing,Databricks Marketplace 是一個開放的數據產品交流平台。
- 清理室 是安全且隱私權保護的環境,用戶可以在敏感數據上共同作業,而不需要直接存取彼此的數據。
分析
最終的商務應用程式位於這個泳道中。 範例包括自定義用戶端,例如連線至 馬賽克 AI 模型服務 的 AI 應用程式,以進行即時推斷,或存取從 Lakehouse 推送至操作型資料庫的數據的應用程式。
針對 BI 使用案例,分析師通常會使用 BI 工具來存取數據倉儲。 SQL 開發者也可以另外使用 Databricks SQL 編輯器(未顯示在圖表中)進行查詢和儀表板操作。
Data Intelligence Platform 也提供 儀錶板 來建置數據視覺效果並共用見解。
結合
- Databricks 平臺會與標準身分識別提供者整合,以進行使用者管理和單一登錄 (SSO)。
OpenAI、LangChain 或 HuggingFace 等外部 AI 服務可以直接在 Databricks Intelligence Platform 內使用。
外部協調器可以使用完整的 REST API,或者可以使用專用連接器來連接像 Apache Airflow 這樣的外部協調工具。
Unity 目錄用於 Databricks Intelligence Platform 中的所有數據和 AI 治理,並可透過 Lakehouse 同盟將其他資料庫整合到其治理中。
此外,Unity 目錄也可以整合到其他企業目錄,例如 Purview。 如需詳細資訊,請連絡企業目錄廠商。
所有工作負載的常見功能
此外,Databricks Lakehouse 隨附可支援所有工作負載的管理功能:
數據和 AI 治理
Databricks Data Intelligence Platform 中的中央資料和 AI 治理系統是 Unity Catalog。 Unity 目錄提供單一位置來管理適用於所有工作區的資料存取原則,並支援在 Lakehouse 中建立或使用的所有資產,例如資料表、容量、功能(功能存放區)和模型(模型登錄)。 Unity Catalog 也可以用來捕捉在 Databricks 上執行的查詢之間的運行時資料血統。
Databricks Lakehouse 監視 可讓您監控您帳戶中所有資料表的資料品質。 它也可以追蹤 機器學習模型和模型服務端點的效能。
為了可觀察性,系統數據表 是由 Databricks 託管的帳戶作業數據的分析存放區。 系統資料表可用於提供帳戶的歷史觀察性。
數據智能引擎
Databricks Data Intelligence Platform 可讓您的整個組織利用數據和 AI,透過將生成式 AI 與 Lakehouse 的整合好處結合起來,以深入了解數據的獨特語意。 請參閱 Databricks AI 支援的功能。
Databricks Assistant 可在 Databricks 筆記本、SQL 編輯器、檔案編輯器及其他工具中,作為具有內容感知功能的 AI 助理來供使用者使用。
自動化與協調流程
Lakeflow 作業 會在 Databricks Data Intelligence Platform 上協調數據處理、機器學習和分析流程。 Lakeflow 宣告式管線 可讓您使用宣告式語法來建置可靠且可維護的 ETL 管線。 平台也支援 CI/CD 和 MLOps
Azure 上 Data Intelligence Platform 的高階使用案例
使用 Lakeflow Connect 從 SaaS 應用程式和資料庫進行內建資料擷取
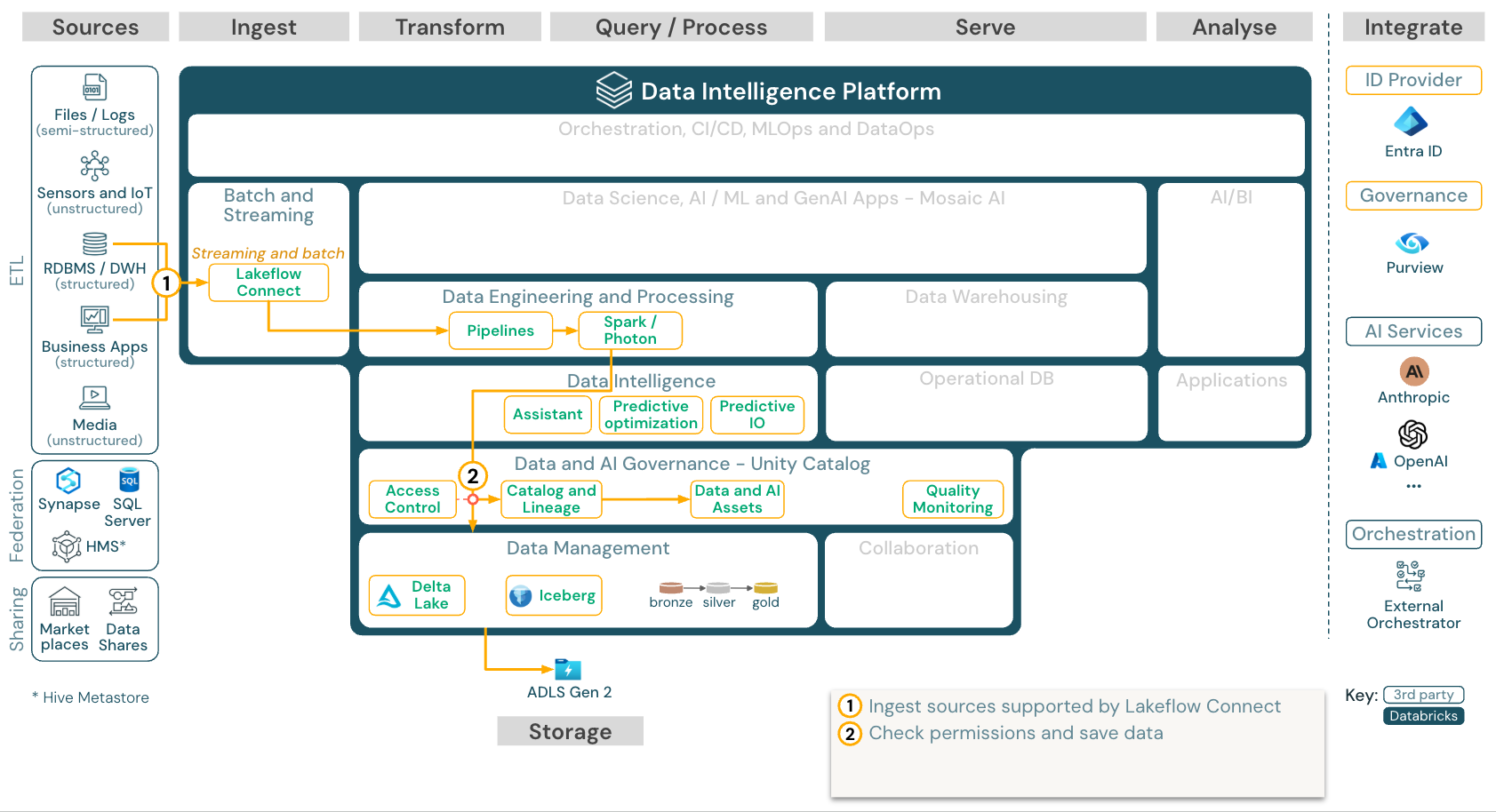
下載:適用於 Azure Databricks 的 Lakeflow Connect 參考架構。
Databricks Lakeflow Connect 提供內建連接器,可從企業應用程式和資料庫擷取。 產生的匯入管線是由 Unity 目錄所控管,並由無伺服器計算和 Lakeflow 宣告式管線驅動。
Lakeflow Connect 利用有效率的累加式讀取和寫入,讓數據擷取更快、可調整且更具成本效益,而您的數據仍可供下游取用。
批次擷取和 ETL
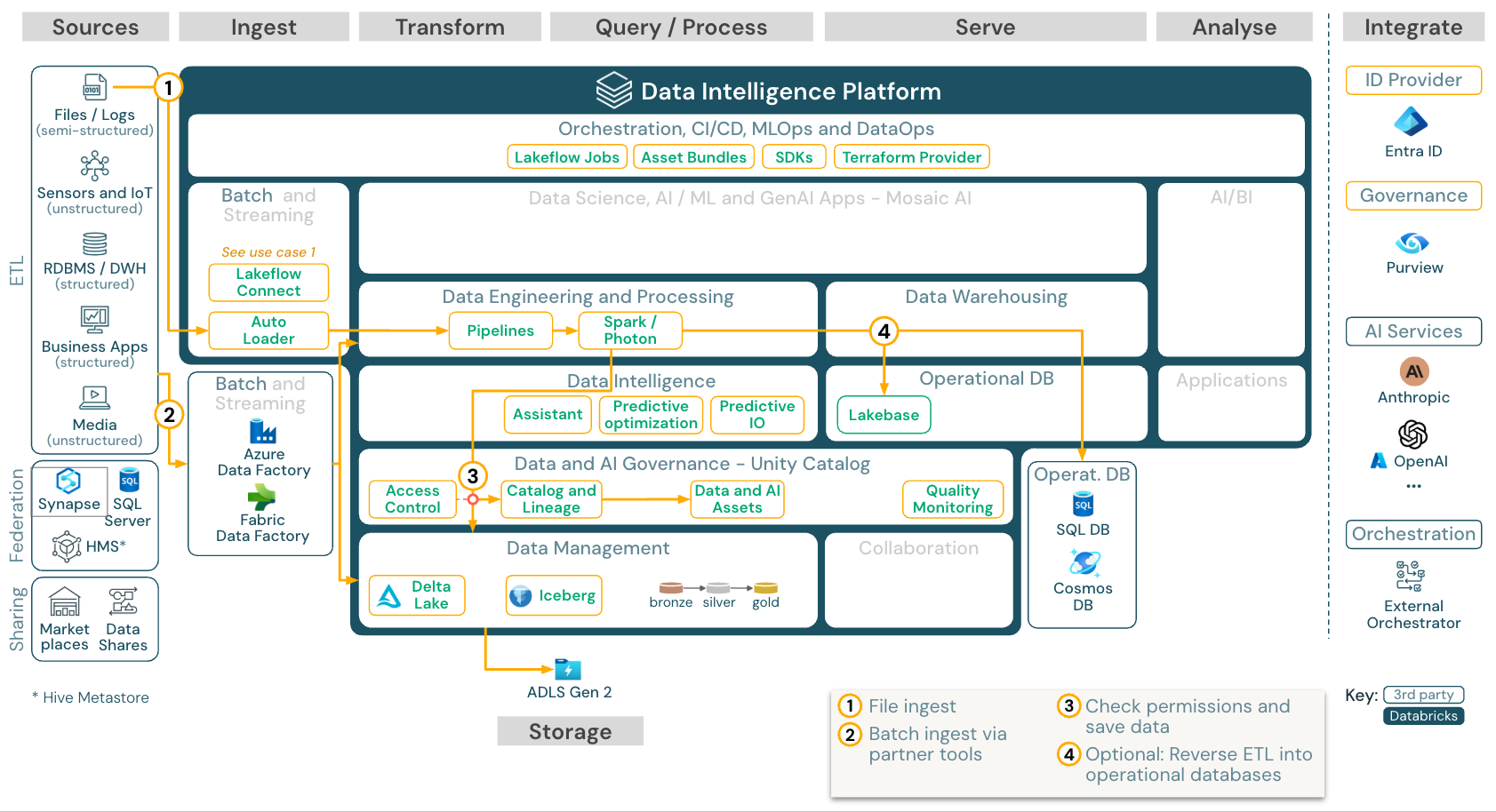
下載:適用於 Azure Databricks 的 Batch ETL 參考架構
擷取工具使用來源特定的配接器來讀取來源數據,然後將其儲存在雲端儲存中,Auto Loader 可從中讀取數據,或直接呼叫 Databricks(例如,將合作夥伴的擷取工具整合到 Databricks Lakehouse 中)。 為了載入數據,Databricks ETL 和處理引擎會透過 Lakeflow 宣告式管線執行查詢。 使用 Lakeflow 作業 協調單一或多任務作業,並使用 Unity 目錄加以控管(訪問控制、稽核、譜系等等)。 若要為低延遲的操作系統提供特定黃金表格的存取權,請將表格匯出至操作性資料庫,例如在 ETL 管線末端的 RDBMS 或索引鍵/值存放區。
串流和變動資料擷取(CDC)
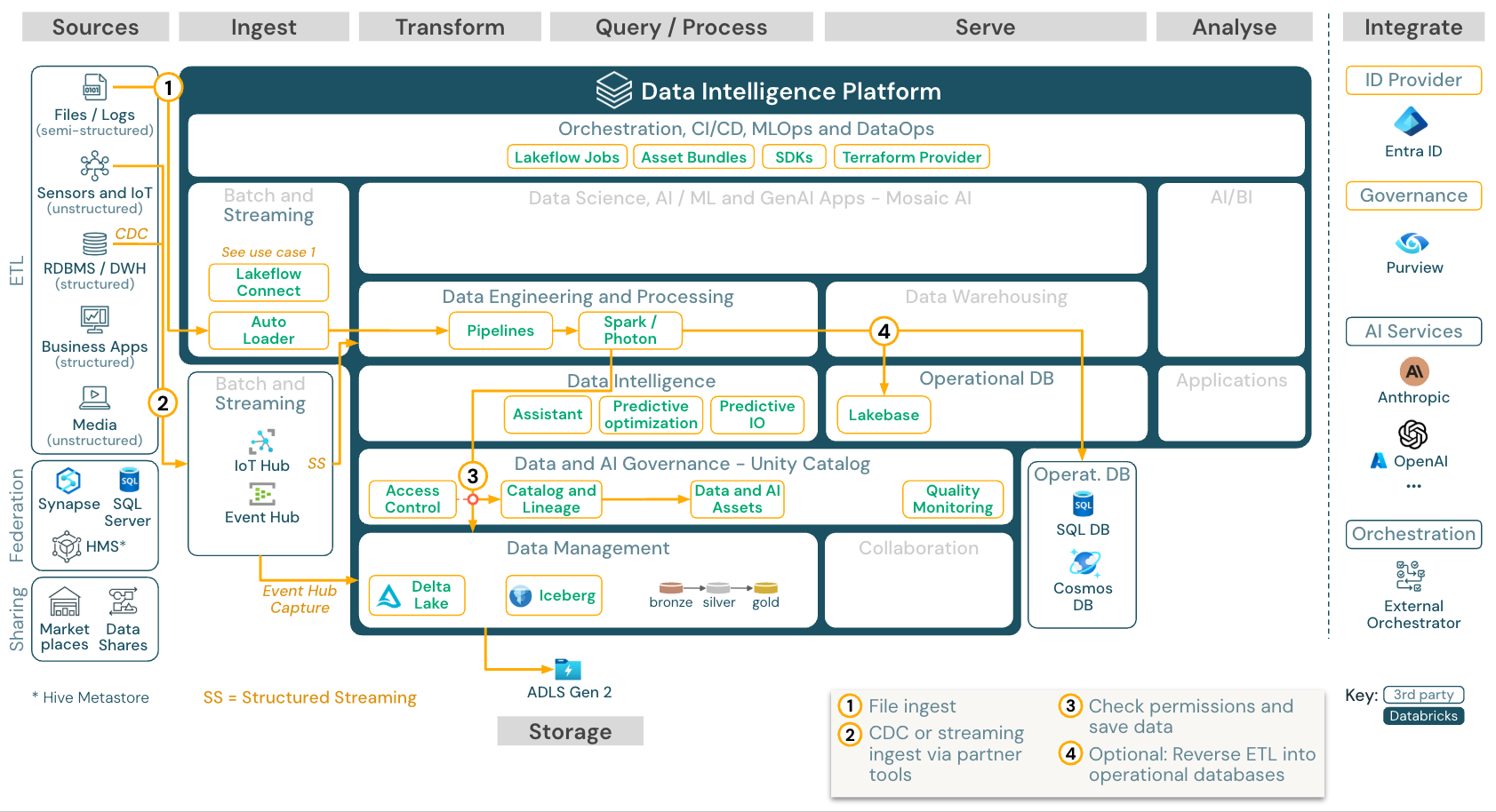
下載:適用於 Azure Databricks 的 Spark 結構化串流架構
Databricks ETL 引擎會使用 Spark 結構化串流 從 Apache Kafka 或 Azure 事件中樞等事件佇列讀取。 下游步驟遵循上述批處理使用案例的方法。
實時 變更數據擷取 (CDC) 通常會使用事件佇列來儲存擷取的事件。 從那裡開始,使用案例會遵循串流使用案例。
如果 CDC 是以將擷取的記錄先儲存在雲端儲存空間的批次中完成,則 Databricks 自動載入器可以讀取這些記錄,而使用案例會遵循批次 ETL。
機器學習和 AI(傳統)
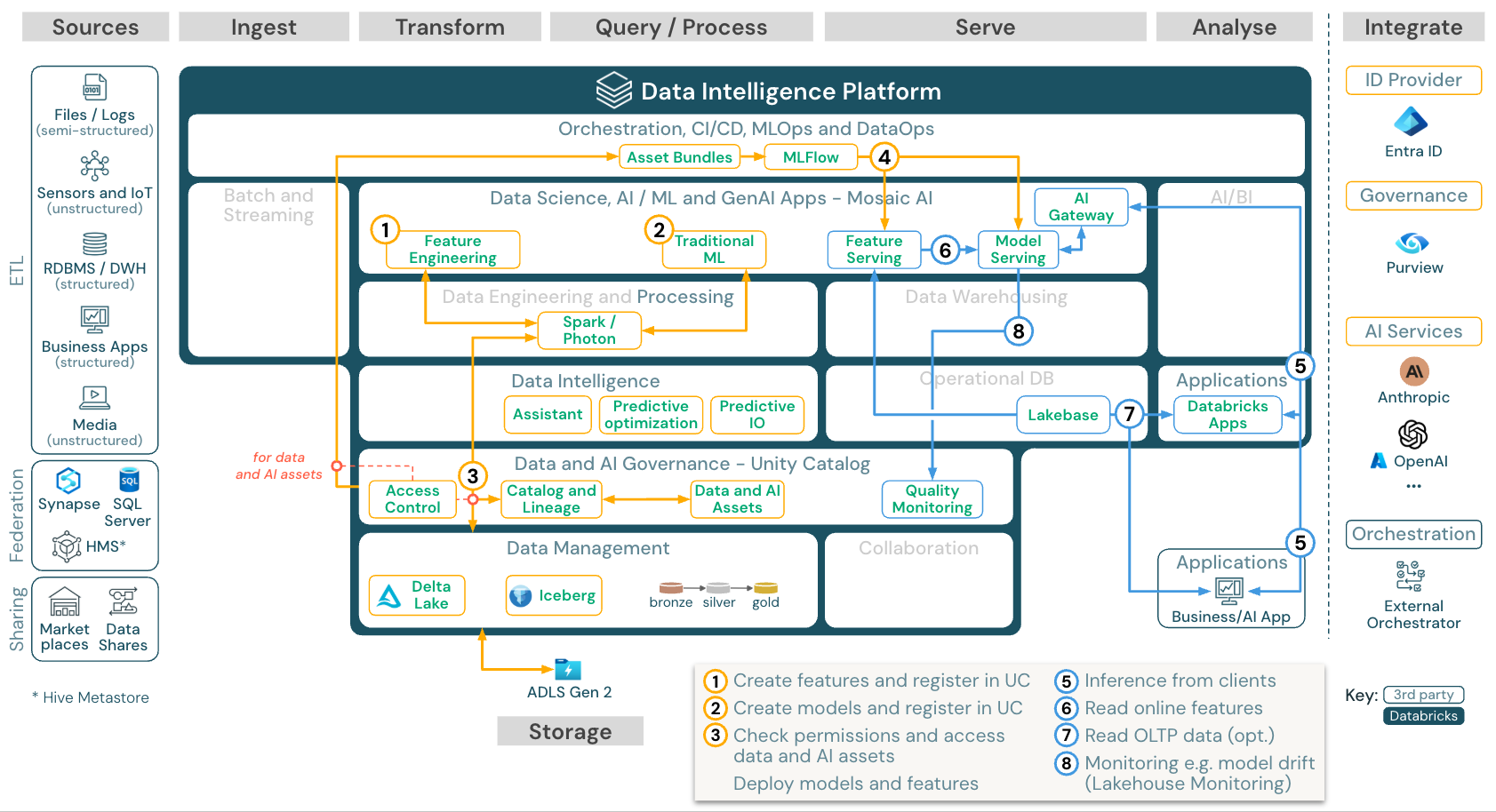
下載:適用於 Azure Databricks 的機器學習和 AI 參考架構
針對機器學習,Databricks Data Intelligence 平臺提供馬賽克 AI,其隨附最先進的 機器學習和深度學習連結庫。 它提供功能庫和模型註冊表等功能(這兩者皆已整合進 Unity 目錄),具備 AutoML 的低程式代碼功能,以及將 MLflow 整合到資料科學生命週期中。
所有數據科學相關資產(數據表、功能和模型)都受到 Unity 目錄的控管,數據科學家可以使用 Lakeflow 作業 來協調其工作。
若要以可調整且企業級的方式部署模型,請使用 MLOps 功能在模型服務中發佈模型。
AI 代理應用程式 (Gen AI)
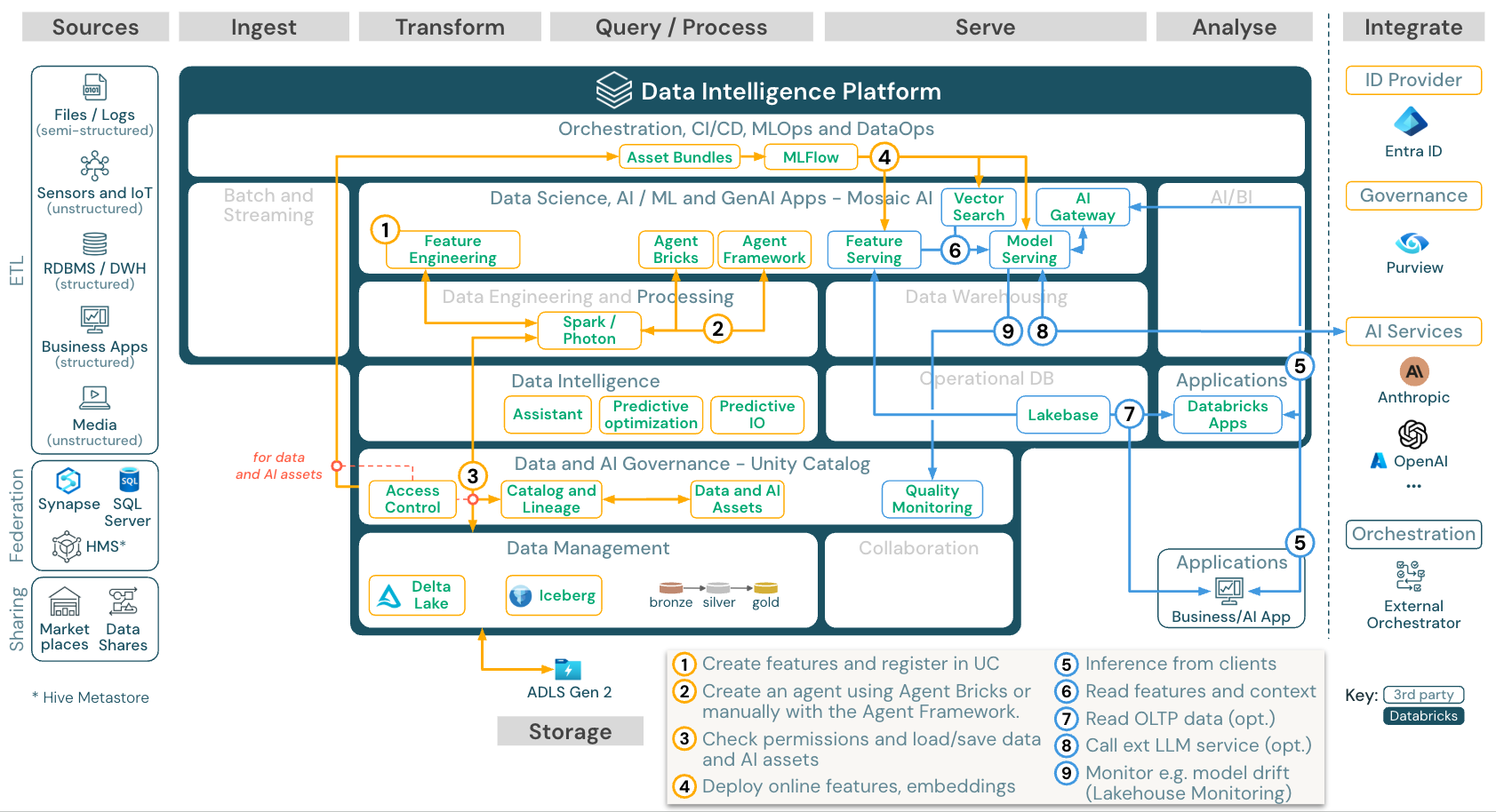
下載:適用於 Azure Databricks 的 Gen AI 應用程式參考架構
若要以可調整且企業級的方式部署模型,請使用 MLOps 功能在模型服務中發佈模型。
BI 和 SQL 分析
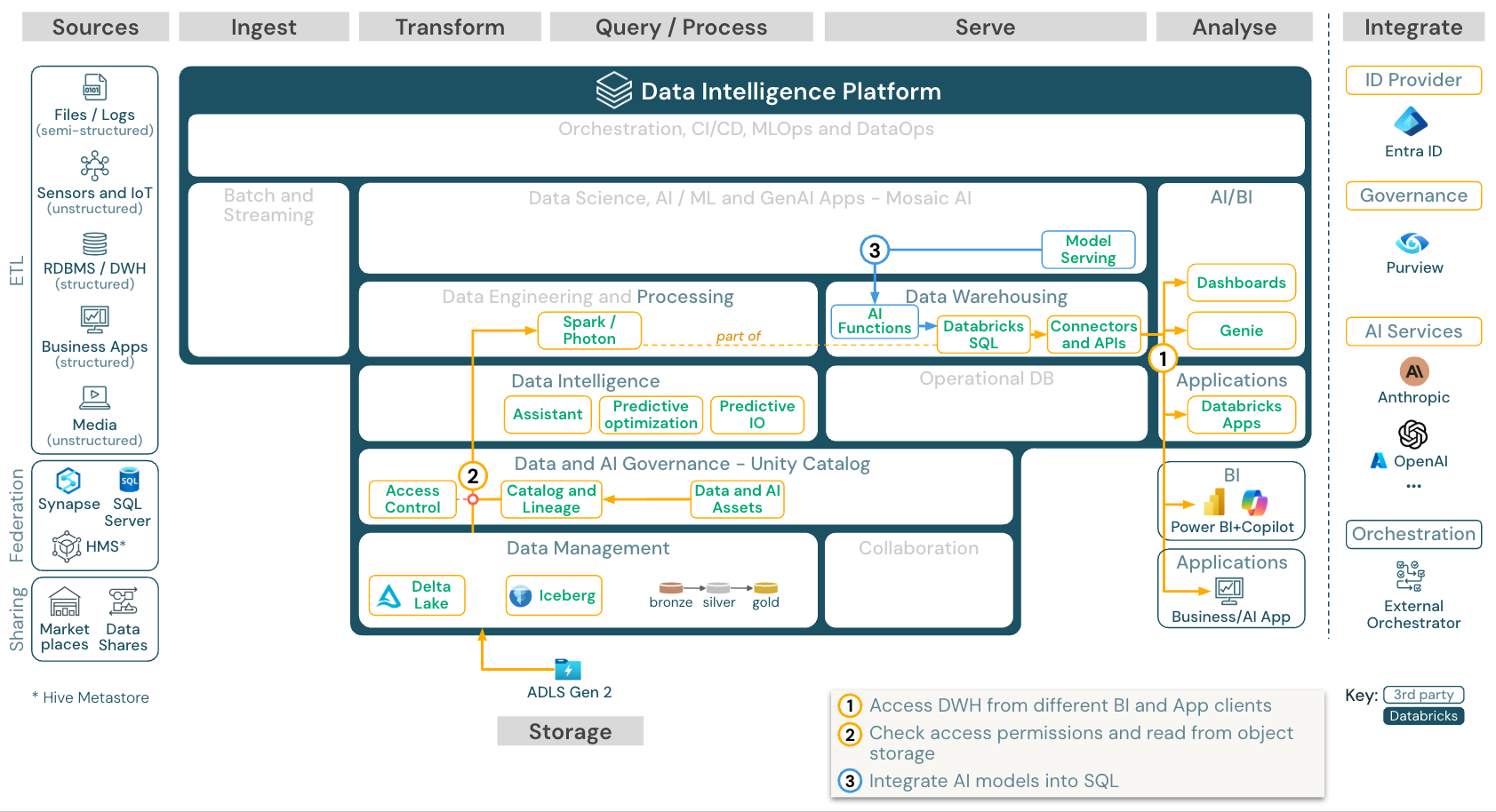
下載:適用於 Azure Databricks 的 BI 和 SQL 分析參考架構
針對 BI 使用案例,商務分析師可以使用 儀錶板、 Databricks SQL 編輯器 或 BI 工具 ,例如 Tableau 或 Power BI。 在所有情況下,引擎都是 Databricks SQL(無伺服器或非無伺服器),而 Unity 目錄會提供數據探索、探索和存取控制。
Lakehouse 同盟
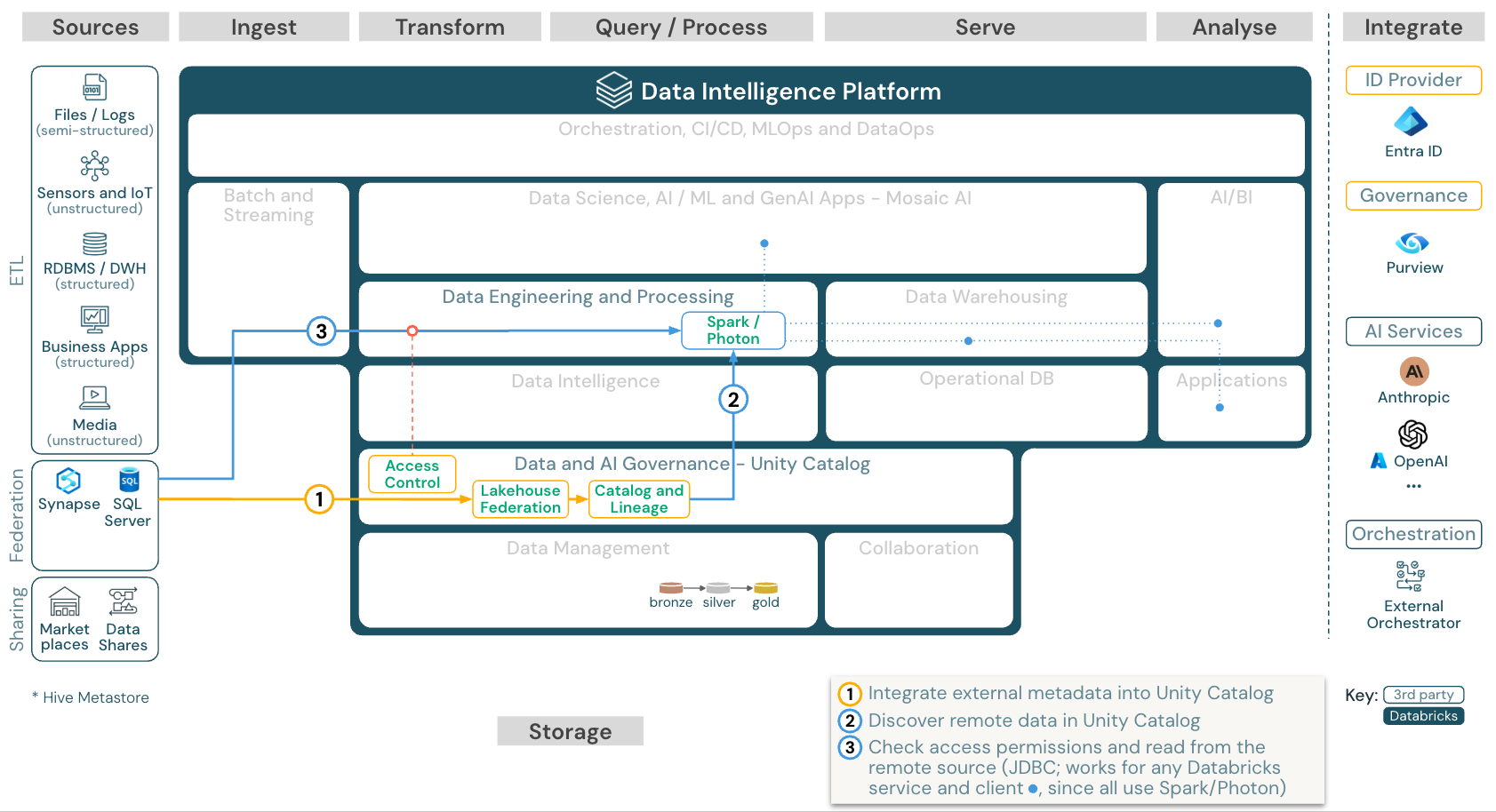
下載:適用於 Azure Databricks 的 Lakehouse 同盟參考架構
Lakehouse 同盟 可讓外部數據 SQL 資料庫(例如 MySQL、Postgres、SQL Server 或 Azure Synapse)與 Databricks 整合。
所有工作負載 (AI、DWH 和 BI) 可以從中受益,而不需要先將資料 ETL 到物件儲存體。 外部來源目錄已映射到 Unity 目錄,可以應用更細緻的訪問控制,通過 Databricks 平臺進行訪問。
目錄同盟
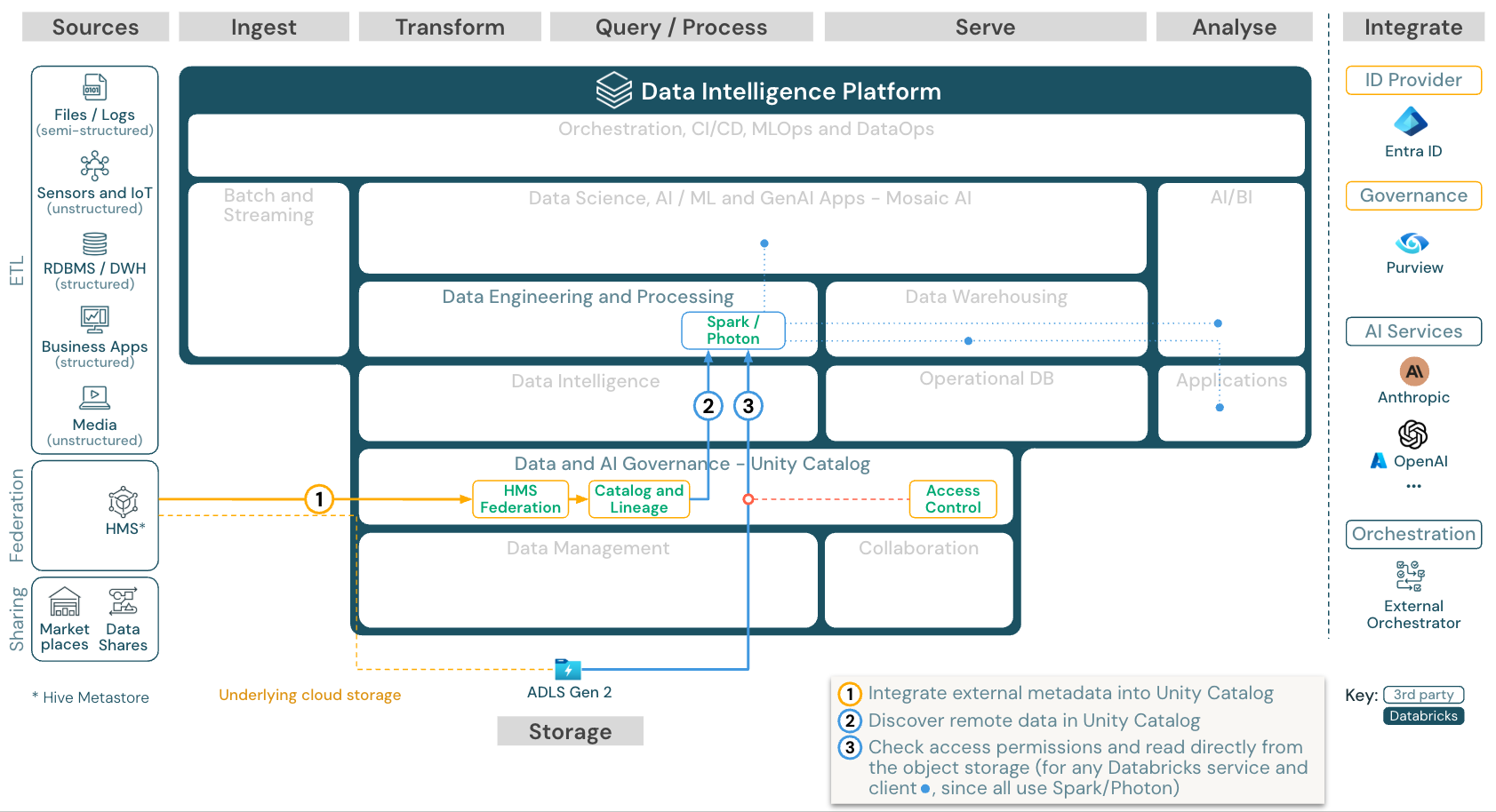
目錄同盟 可讓外部 Hive 中繼存放區(例如 MySQL、Postgres、SQL Server 或 Azure Synapse)與 Databricks 整合。
所有工作負載 (AI、DWH 和 BI) 可以從中受益,而不需要先將資料 ETL 到物件儲存體。 外部來源目錄會新增至 Unity 目錄,其中會透過 Databricks 平臺套用更細緻的訪問控制。
使用第三方工具共享數據
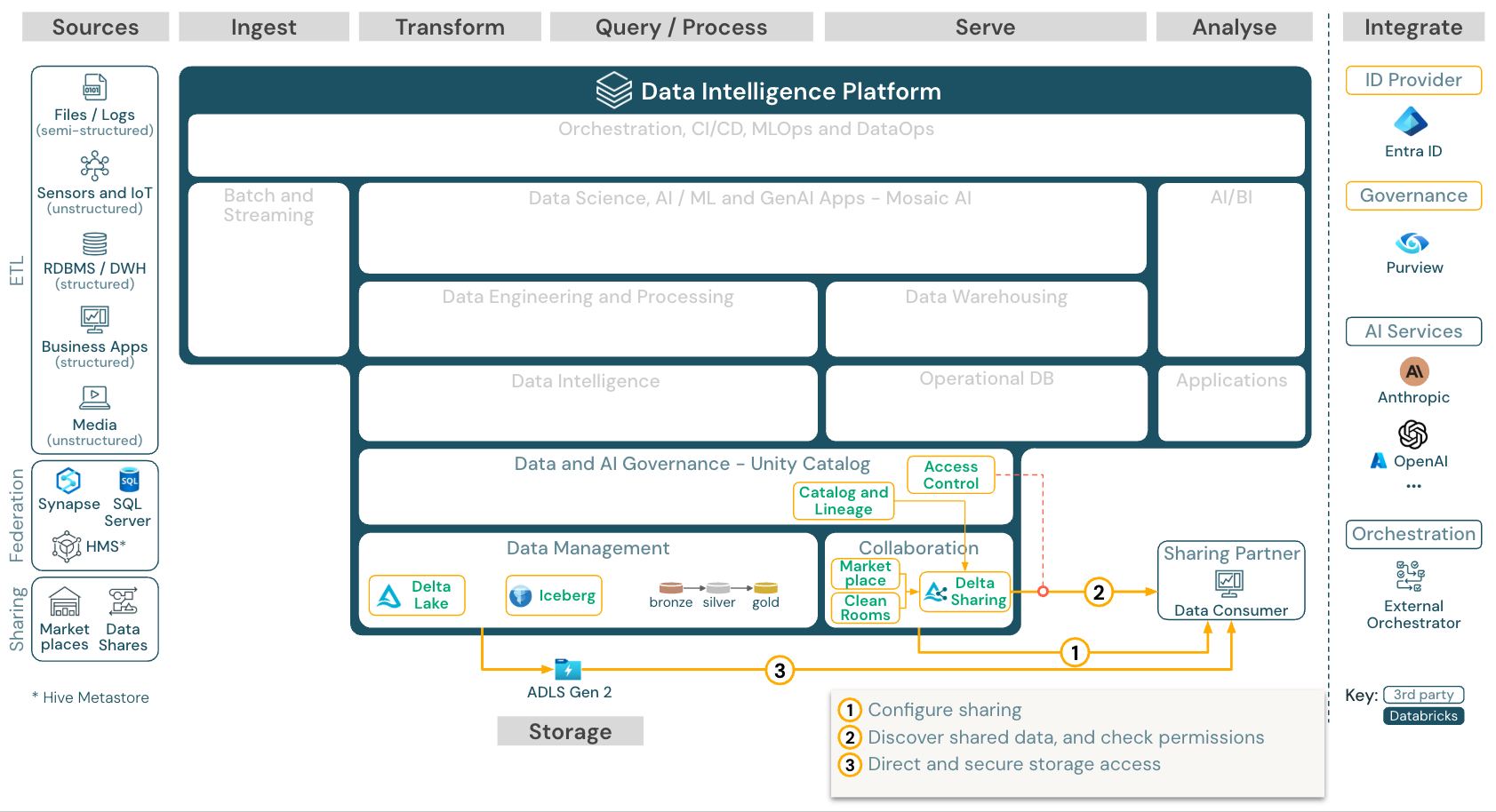
下載:使用 Azure Databricks 的第三方工具參考架構共享數據
第三方提供的企業級數據共用是由 Delta Sharing 提供。 它可讓您直接存取 Unity 目錄所保護之物件存放區中的數據。 這項功能也用於 Databricks Marketplace,這是交換數據產品的開放論壇。
從 Databricks 取用共享數據
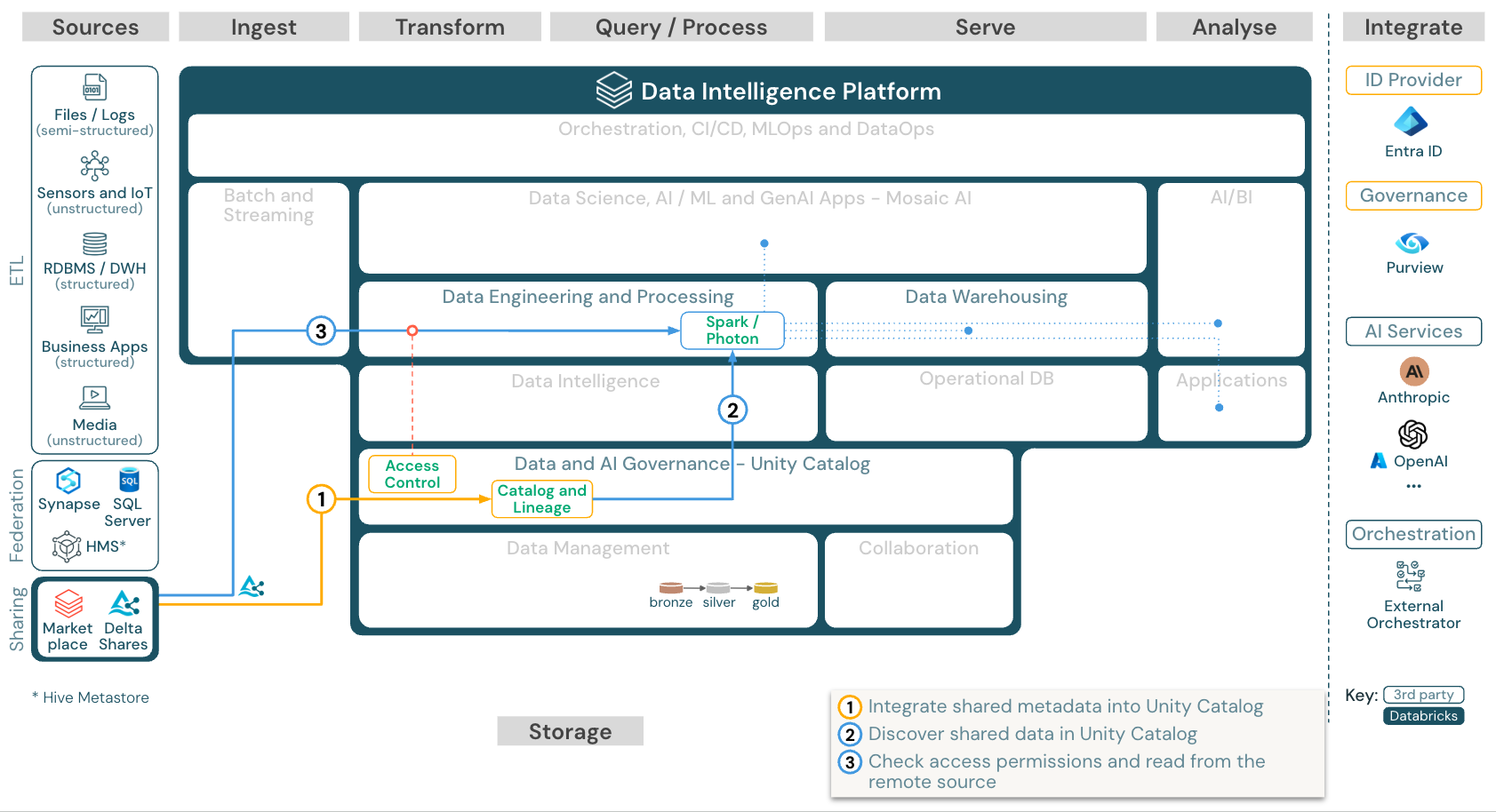
下載:從 Azure Databricks 的 Databricks 參考架構取用共享數據
Delta Sharing Databricks-to-Databricks 通訊協定允許與任何 Databricks 使用者安全地共用數據,無論帳戶或雲端主機為何,只要該用戶能夠存取已啟用 Unity 目錄的工作區即可。