如何在 Azure AI 搜尋中塑造結果
本文說明如何使用 Azure AI 搜尋服務中的查詢回應。 回應的結構是由查詢本身中的參數所決定,如搜尋文件 (REST) 或 SearchResults 類別 (Azure for .NET) 中所述。
查詢上的參數決定:
- 欄位選取
- 在查詢索引中找到的相符項目計數
- 分頁
- 回應中的結果數目 (根據預設,最多可為 50)
- 排序順序
- 醒目提示結果內的字詞,比對內文中的整個或部分字詞
結果組合
結果是表格式,其組成欄位為所有「可擷取」欄位,或僅限於 $select 參數中指定的欄位。 資料列是相符的文件。
您可以選擇搜尋結果中包含哪些欄位。 雖然搜尋文件可能包含大量的欄位,但通常只需要幾個欄位來表示結果中的每個文件。 在查詢要求上,附加 $select=<field list> 以指定哪些「可檢索」欄位應出現在回應中。
選擇在文件之間提供對比和區分的欄位,其會提供足夠的資訊來邀請部分的使用者點集回應。 在電子商務網站上,其可能是產品名稱、描述、品牌、色彩、大小、價格和評等。 針對內建旅館範例索引,其可能是下列範例中的「選取」欄位:
POST /indexes/hotels-sample-index/docs/search?api-version=2023-11-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City"
"count": true
}
未預期結果的提示
有時候,海平面結果的內容是非預期的。 例如,您可能會發現某些結果似乎重複,或「應該」出現在頂端附近的結果卻在結果中的較低位置。 當查詢結果不是預期的結果時,您可以嘗試進行下列查詢修改,看看結果是否有所改善:
將
searchMode=any(預設值) 變更為searchMode=all,以要求須符合所有準則,而非任何準則。 此做法在查詢中包含布林運算子時特別有用。試驗不同的語彙分析器或自訂分析器,來查看其是否變更查詢結果。 默認分析器會分解連字元字,並將單字減少為根窗體,這通常可改善查詢回應的健全性。 不過,如果您需要保留連字號,或如果字串包含特殊字元,您可能需要設定自訂分析器,以確保索引包含正確格式的權杖。 如需詳細資訊,請參閱部分字詞搜尋和具有特殊字元 (連字號、萬用字元、RegEx、模式) 的模式。
計算相符項目數
count 參數會傳回索引中被視為符合查詢的文件數目。 若要傳回計數,請將 $count=true 新增至查詢要求。 沒有搜尋服務強加的最大值。 根據您的查詢和文件的內容,計數可能與索引中的每個文件一樣高。
當索引穩定時,計數是正確的。 如果系統正在主動新增、更新或刪除文件,則計數會是近似值,但未完整編制索引的任何文件除外。
計數不會受到例行維護或搜尋服務上其他工作負載的影響。 不過,如果您有多個分割區和單一複本,在分割區重新啟動時,您可能會遇到文件計數的短期波動 (數分鐘)。
提示
若要檢查索引編制作業,您可以藉由在空白搜尋 search=* 查詢上新增 $count=true,以確認索引是否包含預期的文件數目。 結果是索引中文件的完整計數。
測試查詢語法時,$count=true 可以快速告訴您,您的修改會傳回更多還是更少的結果,這可能是很實用的回饋。
分頁結果
根據預設,搜尋引擎最多可傳回前 50 個相符項目。 前 50 個是由搜尋分數決定,假設查詢是全文檢索搜尋或語意搜尋。 否則,前 50 個是完全相符查詢的任意順序 (其中統一的 "@searchScore=1.0" 表示任意排名)。
上限是每頁搜尋結果傳回的 1,000 份檔,因此您可以將頂端設定為在第一個結果中最多傳回 1000 份檔。 在較新的預覽 API 中,如果您使用混合式查詢,您可以 指定 maxTextRecallSize 來傳回最多 10,000 份檔。
若要控制結果集中所傳回所有文件的分頁,請將 $top 和 $skip 參數新增至 GET 查詢要求,或是將 top 和 skip 參數新增至 POST 查詢要求。 下列清單說明邏輯。
傳回第一組 15 個相符的文件,加上相符項目總數:
GET /indexes/<INDEX-NAME>/docs?search=<QUERY STRING>&$top=15&$skip=0&$count=true傳回第二組,略過前 15 個以取得接下來的 15 個:
$top=15&$skip=15。 針對第三組的 15 個重複執行:$top=15&$skip=30
如果基礎索引會變,則不保證編頁查詢會有穩定結果。 分頁會變更每個頁面的 $skip 值,但每個查詢都是獨立的,而且會在資料的目前檢視上運作,因為其會在查詢時存在於索引中 (換句話說,沒有結果的快取或快照集,例如在一般用途資料庫中找到的結果)。
以下是您可能會取得重複項目的範例。 假設一個索引有四份文件:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
現在假設您想要一次傳回兩個結果,依評等排序。 您會執行此查詢來取得結果的第一頁:$top=2&$skip=0&$orderby=rating desc,這會產生下列結果:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
在服務上,假設在查詢呼叫之間將第五份文件新增至索引:{ "id": "5", "rating": 4 }。 不久之後,您會執行查詢來擷取第二頁:$top=2&$skip=2&$orderby=rating desc,並取得下列結果:
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
請注意,會擷取文件 2 兩次。 這是因為新文件 5 具有更高的評等值,所以其排序在文件 2 之前,並登陸第一頁。 儘管此行為可能是非預期的,但通常是搜尋引擎的行為方式。
對大量結果進行分頁
使用 $top 和 $skip 可讓搜尋查詢逐頁流覽 100,000 個結果,但如果結果大於 100,000 該怎麼辦? 若要逐頁查看如此大型的回應,請使用排序順序和範圍篩選作為 $skip 的因應措施。
在此因應措施中,排序和篩選條件會套用於文件識別碼欄位或每個文件唯一的另一個欄位。 唯一欄位在搜尋索引中必須具有 filterable 和 sortable 屬性。
發出查詢以傳回已排序結果的完整頁面。
POST /indexes/good-books/docs/search?api-version=2023-11-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }選擇搜尋查詢傳回的最後一個結果。 此處顯示了僅包含 "id" 值的範例結果。
{ "id": "50" }在範圍查詢中使用該 "id" 值來擷取下一頁結果。 此 "id" 欄位應該具有唯一值,否則分頁可能包含重複的結果。
POST /indexes/good-books/docs/search?api-version=2023-11-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }當查詢傳回零個結果時,分頁就會結束。
注意
只有在欄位第一次新增至索引時,才能啟用「可篩選」和「可排序」屬性,無法在現有欄位上啟用。
排序結果
在全文搜索查詢中,結果可依下列項目進行排名:
- 搜尋分數
- 語意重新排名器分數
- [可排序] 欄位上的排序順序
您也可以藉由新增評分設定檔來提升特定欄位中找到的任何相符項目。
依搜尋分數排序
針對全文檢索搜尋查詢,結果會自動依搜尋分數排名,其根據文件中的字詞頻率和鄰近性來計算 (衍生自 TF-IDF),而較高的分數會移至搜尋字詞上具有更多或更強相符項目的文件。
針對較舊的服務,"@search.score" 範圍是未繫結的,或是 0 到 1.00 (但不包括)。
針對任一演算法,"@search.score" 等於 1.00,表示未評分或未排名的結果集,其中 1.0 分數在所有結果中都是一致的。 當查詢形式為模糊搜尋、萬用字元或 RegEx 查詢,或空搜尋 (search=*) 時,就會出現未評分的結果。 如果您需要對未評分的結果強加排名結構,$orderby 運算式將協助您達成該目標。
依語意重新排名器排序
如果您是使用語意排名,"@search.rerankerScore" 會決定結果的排序順序。
"@search.rerankerScore" 範圍是 1 到 4.00,其中較高的分數表示更強的語意相符。
使用 $orderby 排序
如果一致的排序是應用程式需求,您可以在欄位上明確定義 $orderby 運算式。 只有將索引編製為「可排序」的欄位可以用來排序結果。
通常用於 $orderby 的欄位包含評等、日期和位置。 除了欄位名稱之外,依位置篩選需要篩選運算式呼叫 geo.distance() 函式。
數值欄位 (Edm.Double、Edm.Int32、Edm.Int64) 是以數值順序排序 (例如,1、2、10、11、20)。
字串欄位 (Edm.String、Edm.ComplexType 子欄位) 是以 ASCII 排序順序或 Unicode 排序順序排序,取決於語言。 您無法排序任何類型的集合。
字串欄位中的數值內容是依字母順序排序 (1、10、11、2、20)。
大寫字串的排序在小寫字串之前 (APPLE、Apple、BANANA、Banana、apple、banana)。 您可以指派文字正規化程式,在排序之前預先處理文字來變更此行為。 使用小寫權杖化工具 ona 欄位不會影響排序行為,因為 Azure AI 搜尋服務會在欄位的非分析複本上排序。
以變音符號開頭的字串最後出現 (Äpfel、Öffnen、Üben)
使用評分設定檔提升相關性
提升順序一致性的另一種方法是使用自訂評分設定檔。 評分設定檔可讓您更充分掌控搜尋結果中的項目排名,並能夠提升在特定欄位中找到的相符項目。 額外的評分邏輯有助於覆寫複本之間的次要差異,因為每個文件的搜尋分數會相距更遠。 我們建議對此方法使用排名演算法。
搜尋結果醒目提示
點擊醒目提示是指將文字格式 (例如粗體或黃色醒目提示) 套用至結果中的相符字詞,讓您輕鬆找出相符項目。 醒目提示適用於較長的內容欄位,例如描述欄位,其中相符項目不是顯而易見。
請注意,醒目提示會套用至個別字詞。 沒有醒目提示功能針對整個欄位的內容。 如果想要醒目提示片語,您必須在引號括住的查詢字串中提供相符字詞 (或片語)。 本節會進一步描述這項技術。
查詢要求上會提供點擊醒目提示指示。 觸發引擎中查詢擴充的查詢 (例如模糊和萬用字元搜尋) 對點擊醒目提示的支援有限。
點擊醒目提示的需求
- 欄位必須是
Edm.String或Collection(Edm.String) - 欄位必須屬性化為可搜尋
在要求中指定醒目提示
若要傳回醒目提示的字詞,請在查詢要求中包含 "highlight" 參數。 參數會設定為以逗號分隔的欄位清單。
根據預設,格式標記為 <em>,但您可以使用 highlightPreTag 和 highlightPostTag 參數覆寫標籤。 您的用戶端程式碼會處理回應 (例如,套用粗體字型或黃色背景)。
POST /indexes/good-books/docs/search?api-version=2023-11-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
根據預設,Azure AI 搜尋服務最多可傳回每個欄位五個醒目提示。 您可以附加後面跟著整數的虛線來調整此數目。 例如,"highlight": "description-10" 會對 [描述] 欄位中的相符內容最多傳回 10 個醒目提示的字詞。
醒目提示的結果
將醒目提示新增至查詢時,回應會包含每個結果的 "@search.highlights",以便您的應用程式碼可以將該結構設為目標。 回應中包含針對 「醒目提示」指定的欄位清單。
在關鍵字搜尋中,系統會個別掃描每個字詞。 查詢 "divine secrets" 會傳回任何文件上包含任一字詞的相符項目。
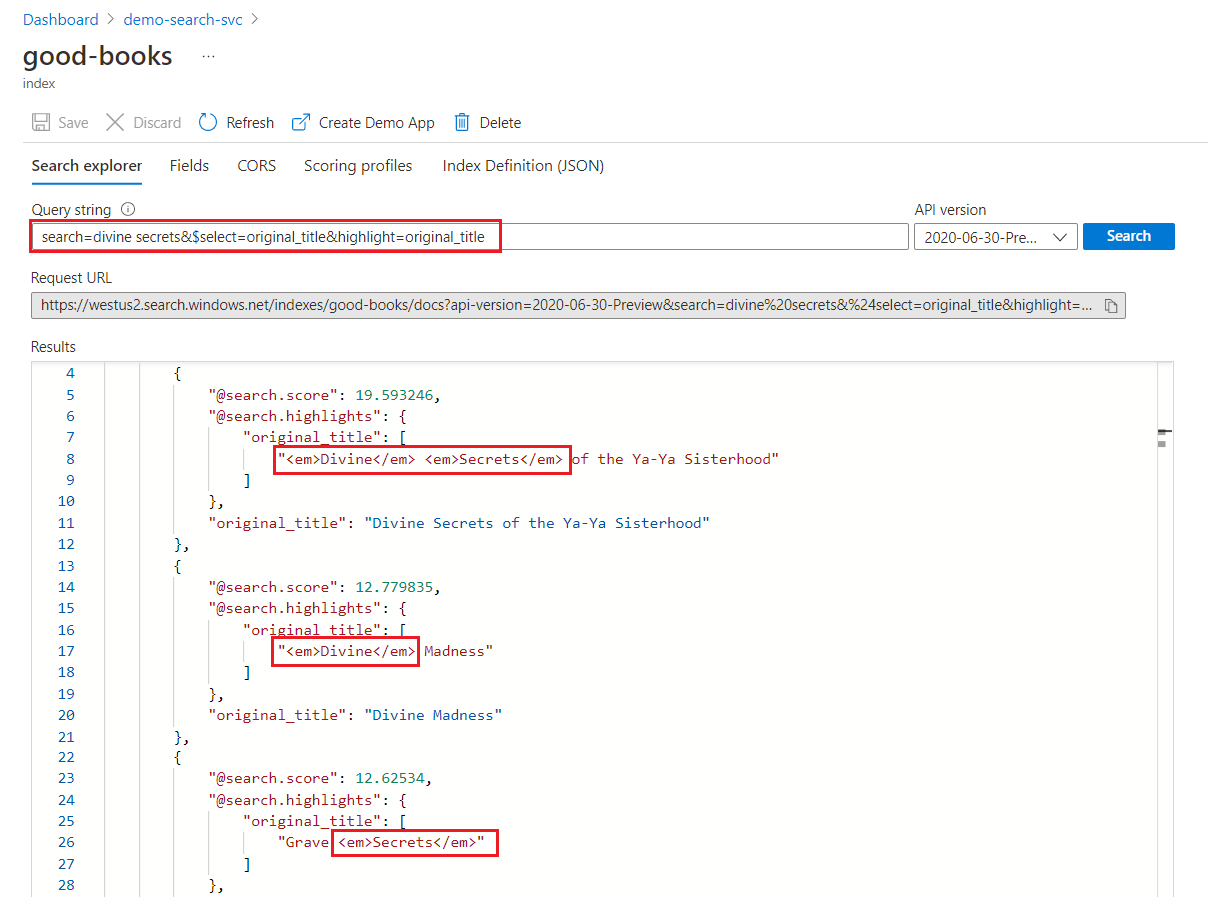
關鍵字搜尋醒目提示
在醒目提示的欄位中,格式化會套用至整個字詞。 例如,在比對 "The Divine Secrets of the Ya-Ya Sisterhood" 時,即使連續,也會個別將格式套用至每個字詞。
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
片語搜尋醒目提示
整個字詞格式即使在片語搜尋上也適用,其中多個字詞會以雙引號括住。 下列範例是相同的查詢,不同之處在於「神聖的秘密」會以引號括住的片語提交(某些 REST 用戶端要求您以反斜杠 \"逸出內部引號):
POST /indexes/good-books/docs/search?api-version=2023-11-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
因為準則現在包含這兩個字詞,所以搜尋索引中只會找到一個相符項目。 上述查詢的回應如下所示:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
舊版服務上的片語醒目提示
在 2020 年 7 月 15 日之前建立的搜尋服務會針對片語查詢實作不同的醒目提示體驗。
針對下列範例,假設查詢字串包含引號括住的片語 "super bowl"。 在 2020 年 7 月之前,片語中的任何字詞都會醒目提示:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
針對在 2020 年 7 月之後建立的搜尋服務,只有符合完整片語查詢的片語將會在 "@search.highlights" 中傳回:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
下一步
若要為您的用戶端快速產生搜尋頁面,請考慮下列選項:
在入口網站中建立示範應用程式,建立包含影像的搜尋列、多面向導覽和結果區域的 HTML 頁面。
將搜尋新增至 ASP.NET Core (MVC) 應用程式是建置功能用戶端的教學課程和程式碼範例。
將搜尋新增至 Web 應用程式是教學課程和程式碼範例,其會針對使用者體驗使用 React JavaScript 程式庫。 應用程式會使用 Azure Static Web Apps 進行部署。
意見反映
即將推出:我們會在 2024 年淘汰 GitHub 問題,並以全新的意見反應系統取代並作為內容意見反應的渠道。 如需更多資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交及檢視以下的意見反映: